









目录:
1、前期参考
2、大顶堆原理
3、小顶堆原理
4、大顶堆和小顶堆对比图
5、大顶堆代码
6、执行结果
————————————————————————————-
1、前期参考
使用一维数组存储二叉树
http://blog.csdn.net/silentwolfyh/article/details/76946539
Java链表来存储二叉树和(前中后序)遍历二叉树
http://blog.csdn.net/silentwolfyh/article/details/72901541
2、大顶堆原理
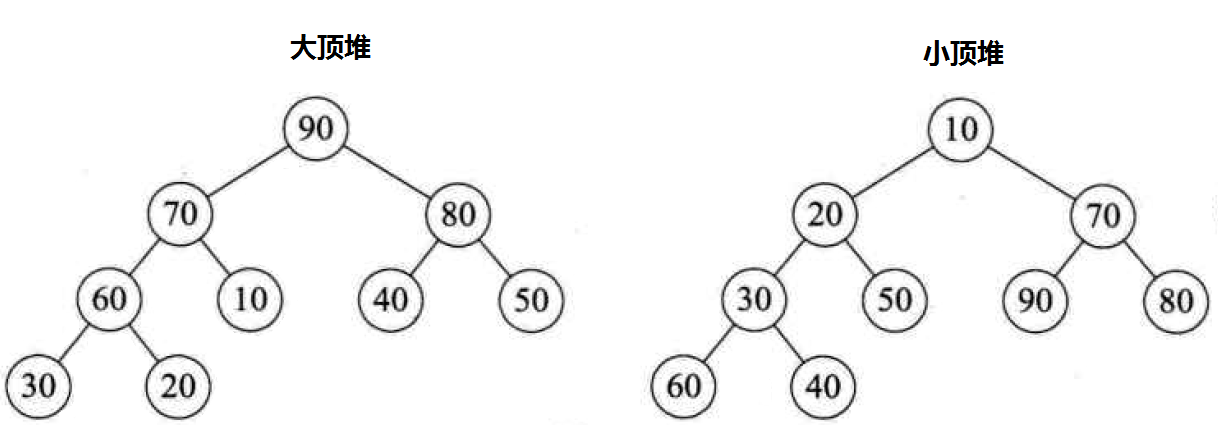
大顶堆原理:根结点(亦称为堆顶)的关键字是堆里所有结点关键字中最大者,称为大顶堆。大根堆要求根节点的关键字既大于或等于左子树的关键字值,又大于或等于右子树的关键字值。
3、小顶堆原理
小顶堆原理:根结点(亦称为堆顶)的关键字是堆里所有结点关键字中最小者,称为小顶堆。小根堆要求根节点的关键字既小于或等于左子树的关键字值,又小于或等于右子树的关键字值。
4、大顶堆和小顶堆对比图
5、大顶堆代码
package com.datastructure;
/***
* 需求:Java实现大顶堆和小顶堆
*
* 备注:
* 1、左节点的坐标等于父节点的坐标*2,右节点的坐标等于父节点的坐标*2+1
* 2、变量j是2的倍数,也就是说j是左子节点
* 3、【如果小顶堆,则在看while中小顶堆的比较】
*
* 代码步骤:
* 1、整体执行过程:从最大根节点的坐标递减
* 2、while中的if(j<size)语句,会判断二叉树的节点是偶数还是基数
* 3、如果是偶数则只有左节点,无法比较,只能和父节点比较
* 4、如果是基数则对比两个子节点获取最大值,再与父节点比较
* 5、父节点大于子节点则退出
* 6、父节点小于子节点则继续while循环比较
*/
import java.io.*;
public class MaxHeap
{
public static void main(String args[]) throws IOException
{
int i,size,data[]={0,5,6,10,8,3,2,19,9,11}; //原始数组内容
size=data.length;
System.out.print("原始数组:");
for(i=1;i<size;i++)
System.out.print("["+data[i]+"] ");
System.out.println("");
MaxHeap.heap(data,size); //建立堆积树
}
public static void heap(int data[] ,int size)
{
int i,j,tmp;
for(i=(size/2);i>0;i--) //建立堆积树节点
MaxHeap.ad_heap(data,i,size-1);
System.out.print("\n堆积内容:");
for(i=1;i<size;i++) //原始堆积树内容
System.out.print("["+data[i]+"] ");
}
public static void ad_heap(int data[],int i,int size){
int j,tmp,post;
j=2*i;
tmp=data[i];
post=0;
while(j<=size && post==0)
{
if(j<size)
{
//if(data[j]>data[j+1]) //小顶堆的比较
if(data[j]<data[j+1]) //找出两个子节点最大值
j++;
}
//if(tmp<=data[j]) //小顶堆的比较
if(tmp>=data[j]) //若树根较大,结束比较过程
post=1;
else
{
data[j/2]=data[j]; //若树根较小,则继续比较,这里将最大子节点赋值给父节点
j=2*j;
}
}
data[j/2]=tmp; //指定树根为父节点
}
}
6、执行结果
原始数组:[5] [6] [10] [8] [3] [2] [19] [9] [11]
堆积内容:[19] [11] [10] [9] [3] [2] [5] [6] [8]
















 1268
1268

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











