







 spark调度分为两种,一是应用之间的,二是应用内部作业的。本文主要介绍spark应用内部的作业调度,多线程提交作业的情况下,各个job的调度方式。详细介绍了FIFO与Fair调度算法的原理、源码与案例。结合thriftserver介绍了SQL级别的作业调度
spark调度分为两种,一是应用之间的,二是应用内部作业的。本文主要介绍spark应用内部的作业调度,多线程提交作业的情况下,各个job的调度方式。详细介绍了FIFO与Fair调度算法的原理、源码与案例。结合thriftserver介绍了SQL级别的作业调度
一、调度分类
调度分为两种,一是应用之间的,二是应用内部作业的。
(一)应用之间
我们前面几章有说过,一个spark-submit提交的是一个应用,不同的应用之间是有调度的,这个就由资源分配者来调度。如果我们使用Yarn,那么就由Yarn来调度。调度方式的配置就在$HADOOP_HOME/etc/hadoop/yarn-site.xml中
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value>
</property>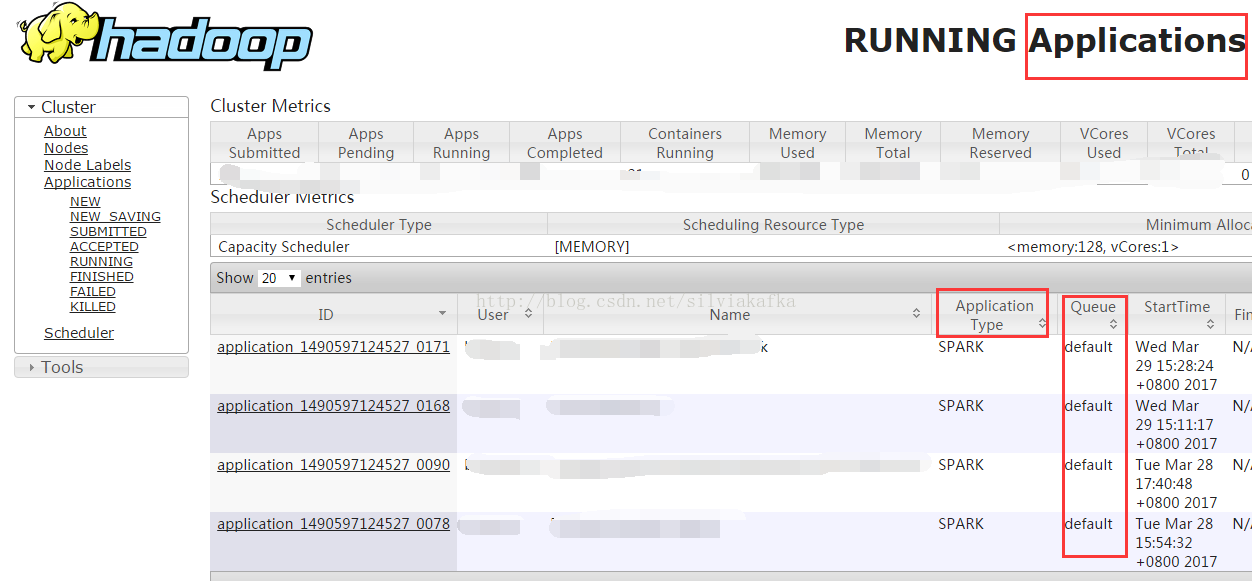
(二)应用内部
参考《Spark基础入门(三)--------作业执行方式》可以看到,SparkContext底层会触发调用runJob的方法阻塞式的提交job,提交job的线程会处于阻塞状态,同一个线程中,后面的job需要等待前面job完成才能提交。但当多线程执行时,则可以并发提交Job。
例如SparkStreaming运行并发提交时,可以看到一个SparkStreaming的项目中多个job在同时跑:
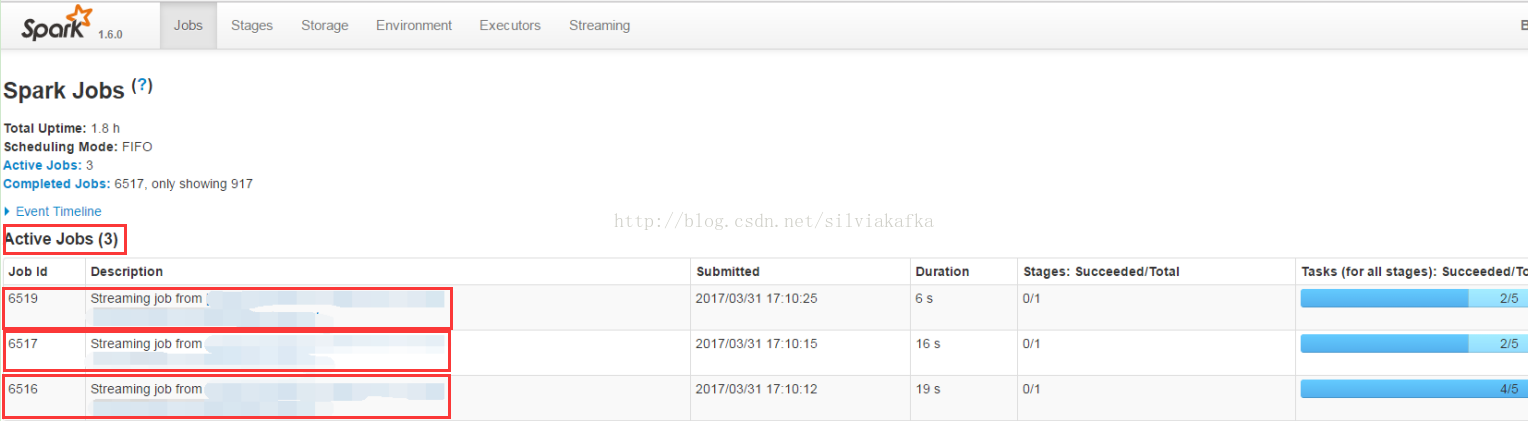
再例如Thriftserver,多个用户通过beeline连接Thriftserver提交自己的查询,所有的查询都是并行运行的:
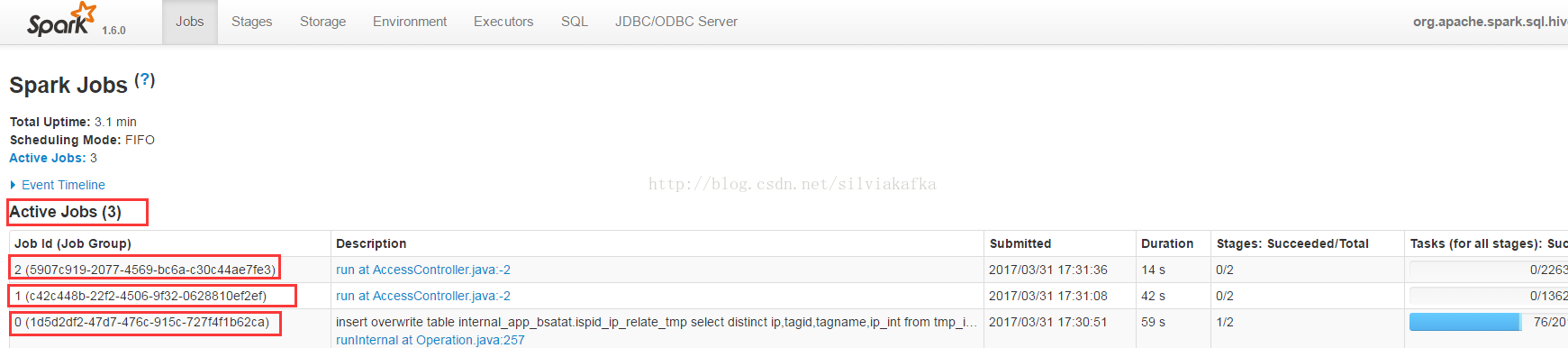
我们重点介绍应用内部的调度,调度方式的配置在
$SPAKR_HOME/conf/spark-defaults.conf
spark.scheduler.mode = FIFO/FAIR二、调度原理
结合《Spark基础入门(三)--------作业执行方式》
(一)作业提交与调度池的创建
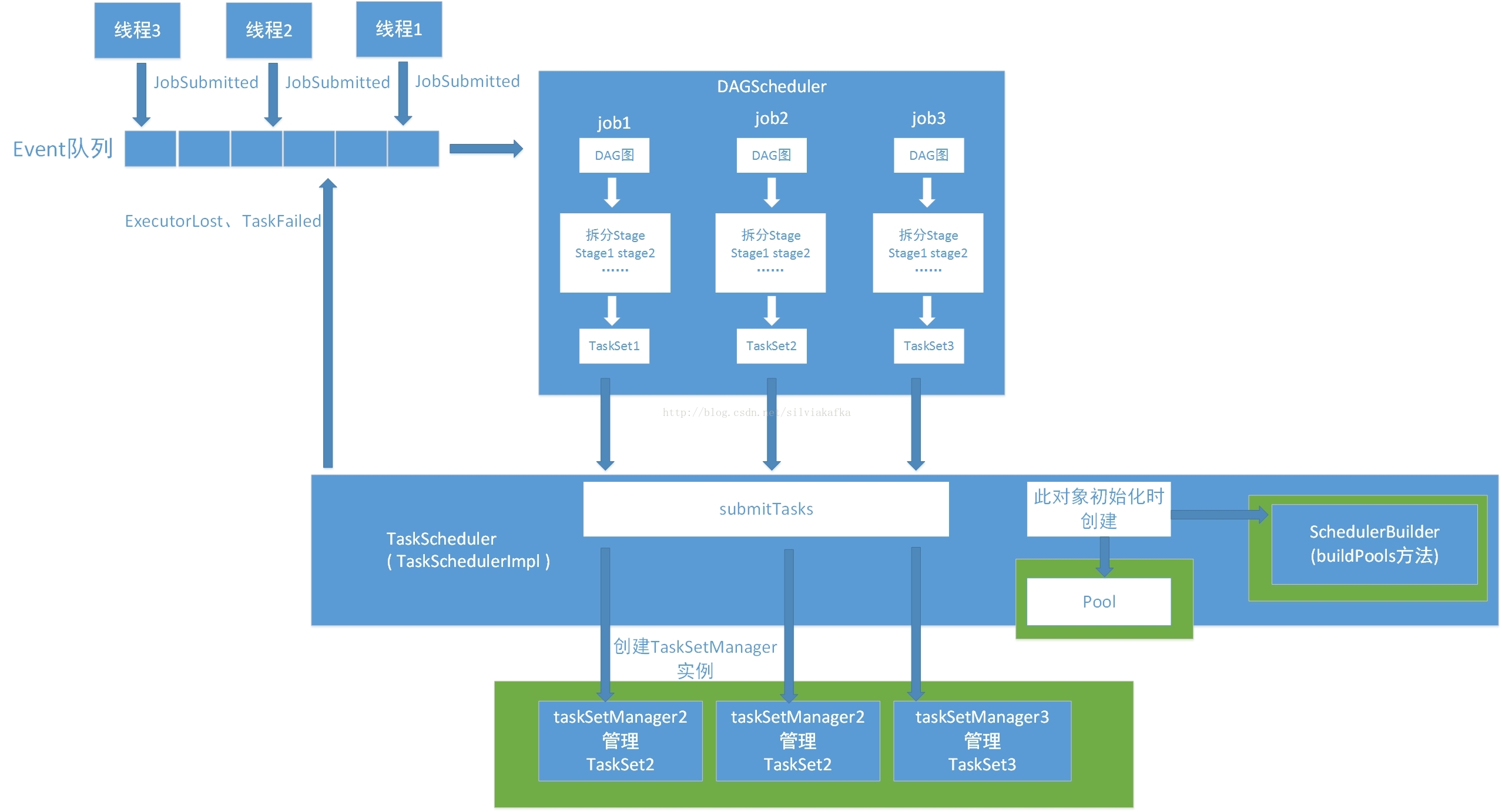
1. DAGScheduler采取的生产者消费者模型,存在一个Event队列,用户和TaskScheduler会生产event到这个队列中,DAGScheduler中会有一个Daemon线程去消费这些event并产生对应的处理。DAGScheduler可以处理的Event包括:JobSubmitted、CompletionEvent、ExecutorLost、TaskFailed、StopDAGScheduler。
2. DAGScheduler 在接收到JobSubmitted的Event之后,会首先计算出其DAG图,然后划分Stage,最后提交TaskSet到TaskScheduler(通过调用TaskScheduler的submitTasks,TaskScheduler还有cancelTasks的方法)
3. TaskScheduler的submitTasks方法最后会创建TaskManager的实例,由它去管理里面的TaskSet。
4. SparkContext是多线程安全的,可以有多个线程提交Job,这个Job也就是sparkAction
5. 每个线程提交Job时,是按Stage为最小单位来提交的,提交一个stage的TaskSet(一堆task任务)有一个TaskSetManager会来管理TaskSet,一个TaskSet对应一个
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 147
147











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









