







随着软件行业的快速发展,高效的研发效能已成为企业竞争力的关键因素。尤其对于具有一定人数规模的敏捷研发团队,如何在复杂的项目环境中客观衡量研发效能,更是团队和管理者面临的重要课题。这不仅关系到项目的质量、交付速度,更直接影响到企业的市场地位和经济效益。因此,探索合理、有效的研发效能度量方法,对于研发团队来说,具有重要的现实意义。
作为一家领先的研发效能度量分析服务提供商,思码逸通过其DevInsight 研发效能度量分析平台,已经协助众多研发团队构建了一套专业的研发效能度量体系与分析能力。针对如何通过度量研发效能,以及多角度洞察敏捷团队的价值交付的问题,我们将以一个实际的客户案例进行介绍(为保护客户隐私,案例中的数据非实际数据,部分进行过人为修改)。
在本文中,我们将重点分享以下内容:
-
项目的背景信息
-
团队面临的痛点与挑战
-
我们的解决方案
-
如何通过季度报告帮助高层管理者管理研发的交付价值和成本
-
如何通过月度报告帮助中层管理者发现效能短板、聚焦管理精力
-
如何利用双周报告辅助团队领导管理研发过程、打造改进闭环
-
项目背景
该企业是互联网行业知名的电商企业,有 200+人的研发团队,采用敏捷开发模式。CTO 牵头发起研发效能的建设项目,由该团队的质量管理负责人和 PMO 推动研发效能体系的落地。
团队痛点与挑战
我们这个案例中的团队主要面对的研发效能难题有两方面:
1. 研发价值的反馈不透明,高层管理者希望了解研发成本是否花在了有价值的事情上?
2. 管理层中的不同的角色对研发效能的关注点不同,希望通过研发效能度量为不同角色提供针对性的数据抓手。那么希望研发效能带来的数据和洞察可以实现:
-
1)由于项目每双周一次迭代,所以希望通过研发数据驱动研发Leader/项目经理发现风险或问题。计划通过效能双周会展示数据,落实改进点、负责人、及改进措施。
2)每个月能够给中层管理者提供研发价值和成本投入情况,能够看到整体研发效能和短板,聚焦管理成本。
3)每季度需要跟高层管理者汇报,希望能够给高层汇报价值达成、研发效能的宏观结果。
解决方案
针对以上这些痛点,思码逸 DevInsight 提供了从研发数据归集、治理,到研发效能指标体系、数据看板与专家级分析建议等全套的解决方案。同时,我们还为客户提供了创新的“代码当量”指标(点击阅读指标解释)。该指标相对于工时、需求数量、代码行数等指标,可以帮助团队更科学、更客观地度量研发工作量。
在这个案例中,由于不同的角色对于研发效能数据分析的需求不同,所以我们需要针对高层管理者、中层管理者、研发团队 Leader,三个不同角色提供对应的数据看板来分析不同维度的效能指标。同时,针对第一个痛点,我们通过交付价值、交付成本、交付效率、交付质量等维度来分析、解释团队的“研发价值”和“研发成本与产出”。另外,不同角色的视角不同,例如高层管理者更需要看宏观的数据和分析报告,而团队 leader 则需要关注更多细节,所以我们不仅要按照角色,还需要按照时间维度来提供相应的数据报告。
那么我们是怎么做的呢?我们接下来通过一些实例,讲讲我们为这三个不同的角色,提供了哪些数据指标,以及如何基于看板来分析他们所关注的效能问题。
一、如何通过季度报告帮助高层管理者管理研发的交付价值和成本
度量目标:重点从交付价值和成本出发,根据数据分析结果,识别出不同维度的短板。
1)针对交付价值
通过数据回答的问题:
真正产生价值的需求有多少?
通过思码逸的 DevInsight研发效能度量分析平台 ,我们可以统计所选时间范围内,到达考核周期的需求的价值转化情况。这里的需求价值可以包含用户价值、企业价值、服务价值、销售价值等,具体可以根据企业自身情况来决定。基于不同价值对企业的重要程度,会有一个评分权重,依次来计算最终的需求价值。
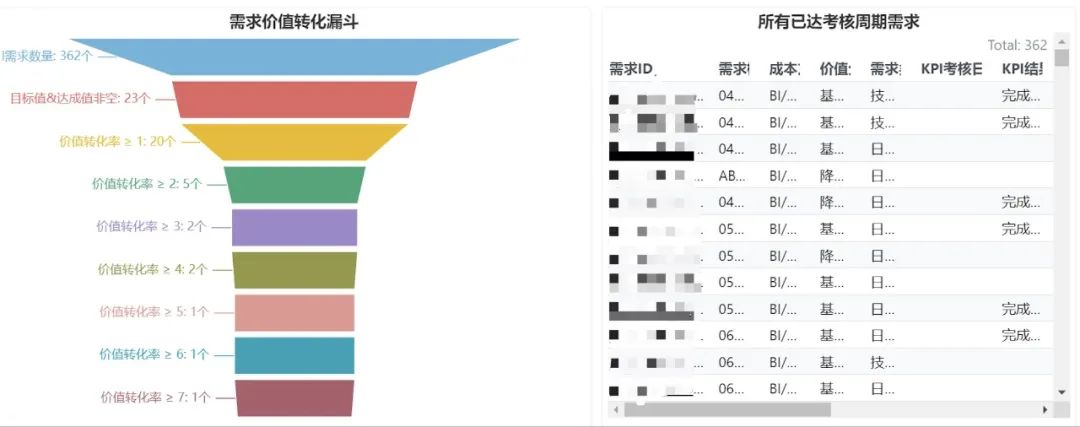
2)针对交付成本
通过数据回答的问题:
研发成本是否花在了有价值的事情上?
「产品需求」投入成本 VS 价值产出
管理者可以通过开发工作量(即:代码当量)与价值产出的四象限分析,定位“投入多/价值达成率低”的改善区间。在进行分析时,管理者可以参照以下的计算方法来分析:
-
需求投入成本,即需求下关联的所有技术任务的「代码当量」累计;
-
需求价值转化率 = 实际达成值 / 计划目标值。
-
四象限交叉点:需求价值转化率为 1 、需求投入代码当量均值。

3)针对交付效率
通过数据回答的问题:
团队的交付水平如何?与历史比变化如何?
针对这个问题,我们需要解答的主要指标是“需求交付效率”、“研发交付周期”和“月均需求吞吐量”。在这里,我们要与高层对齐这几个指标分别都是如何计算的:
-
需求交付效率,即结合研发交付周期与需求吞吐量的综合判断,衡量需求交付是否又“快”又“多”。
-
研发交付周期,即需求从开发中状态至完成状态成所用的时间。
-
月均需求吞吐量,即所选时间范围内月均交付需求数量。
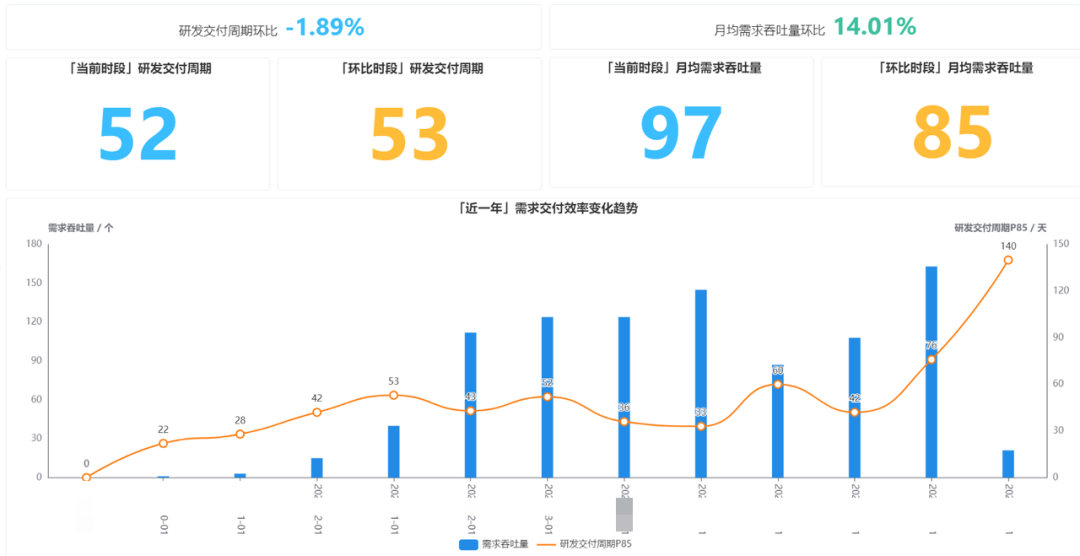
4)针对交付质量
通过数据回答的问题:
项目交付的质量如何?与之前相比有什么变化?
针对这个问题,我们需要结合代码当量与缺陷数量来计算,并根据时间范围,给出缺陷逃逸率。同时,我们还要进行环比,观察质量变化的趋势。具体的指标计算方式如下:
-
线上缺陷逃逸率 = 所选时间范围内,线上缺陷数量 /(内测+线上缺陷)数量 ;内测千当量缺陷密度 = 所选时间范围内,新增缺陷数 / 新增代码当量
-
环比变化,为环比90/180天(依赖筛选器选择的环比模式)指标值上升或下降的比例。
二、如何通过月度报告帮助中层管理者发现效能短板、聚焦管理精力
度量目标:由于中层管理者管理多个团队,需要了解团队间横向差异,重点是定位各维度“关键的少数”,及时发现问题。
针对这样的度量目标,客户在 DevInsight 中建立了月报,围绕交付价值、交付成本、交付质量三方面度量多个团队的指标,以便进行横向对比,发现差异,在出现问题苗头时快速做出改进动作。
1)针对交付价值
通过数据回答的问题:
哪些成本方(业务线)需求的达标率偏低?哪一类的需求达标率偏低?聚焦管理重点。
交付价值的度量属于研发效能整体度量框架中重要的一部分,通过对研发资源、不同需求的投入产出比的度量,洞察研发团队交付价值产出情况。例如我们通过下图可以看到不同业务线在同一个时间周期内需求达标率。
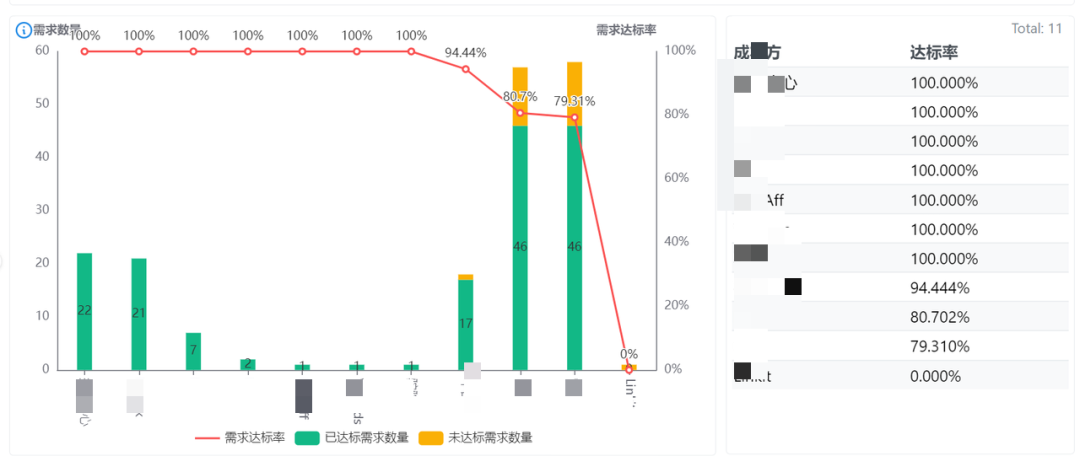
2)针对交付成本
通过数据回答的问题:
研发成本投入的变化是否符合业务规划?研发的投入与产出是否平衡?
近一年「成本方」投入工时占比趋势
通过成本方各月已完成任务对应工时的比例变化,衡量成本投入是否符合预期计划,及业务规划或诉求等。
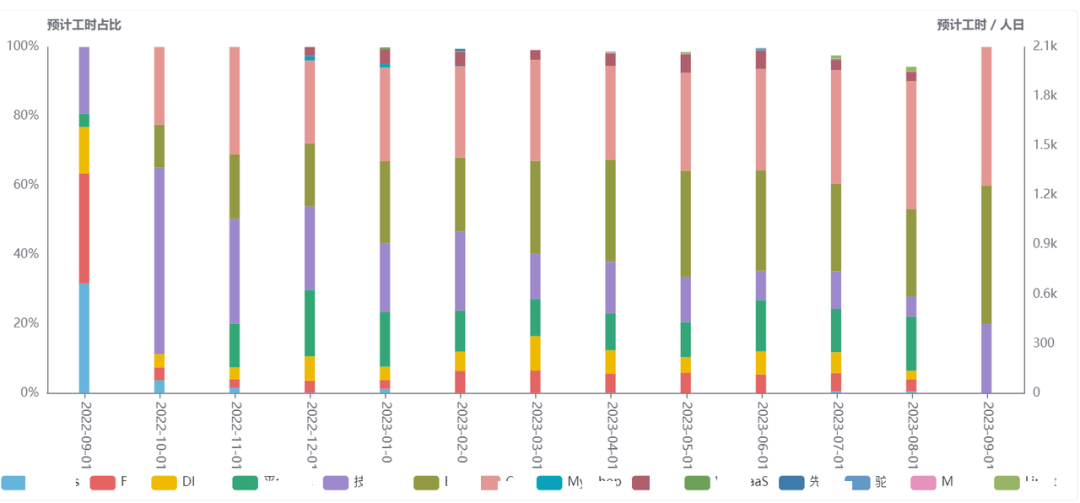
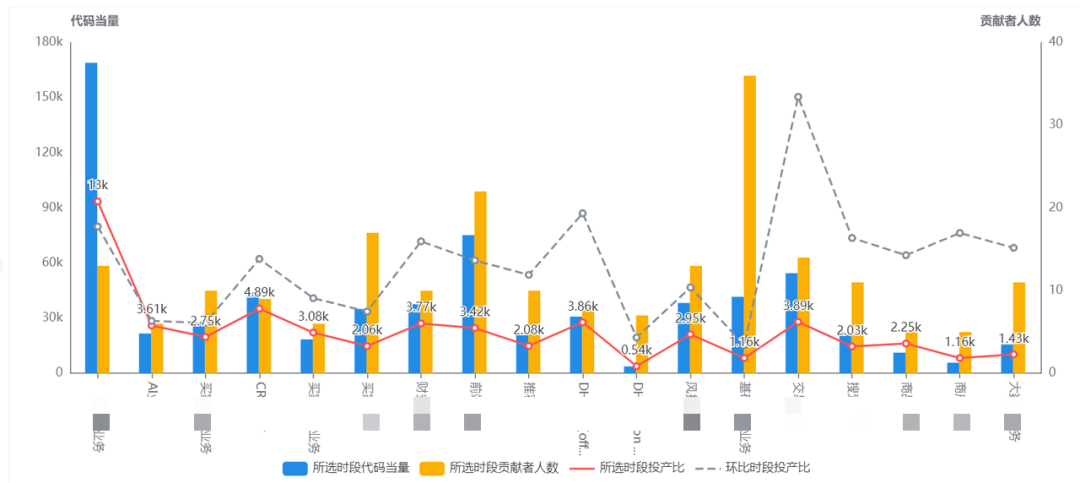
「各项目」投入产出比
通过项目投入人力、产出当量两者的变化,判断投入产出是否符合预期。通过环比,判断各项目投产比近期变化是否符合阶段特征。
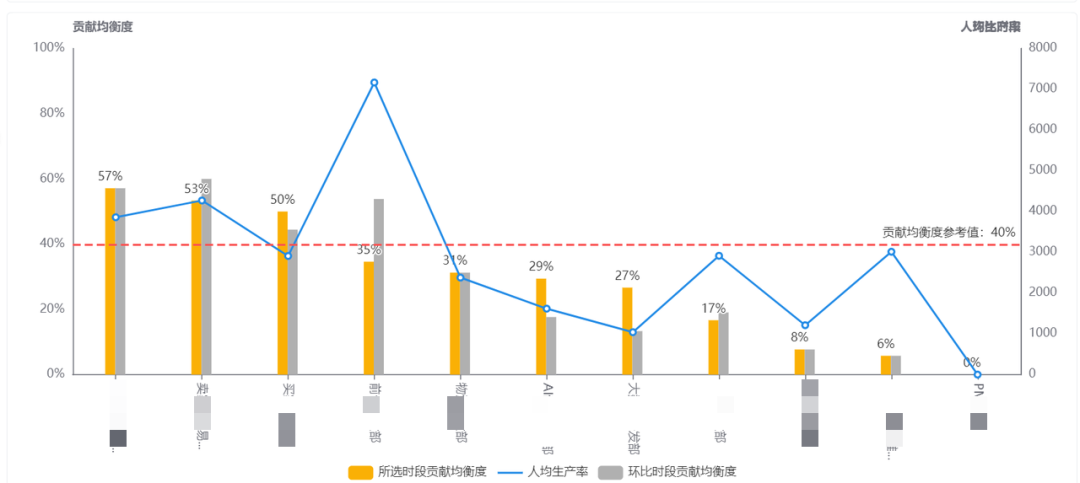
「各团队」贡献均衡度 VS 月生产率
贡献均衡度与生产率密切相关,可通过提升贡献均衡度提高生产率。
-
在下图中,当贡献均衡度与生产率均低,会提示存在任务低负载的风险;贡献均衡度低但生产率高,则提示个别贡献者有任务过载的风险。
-
图中的研发团队月生产率,以月为度量步长,即为月人均当量数值。
3)针对交付效率
通过数据回答的问题:
需求交付效率变化如何,是否有提升空间?哪些团队的研发效率需要重点关注?
解决方法是通过绝大多需求研发交付周期的85%分位值判断研发交付价值的速度;通过交付周期的环比变化,判断研发交付速度是否平稳或有缩短。
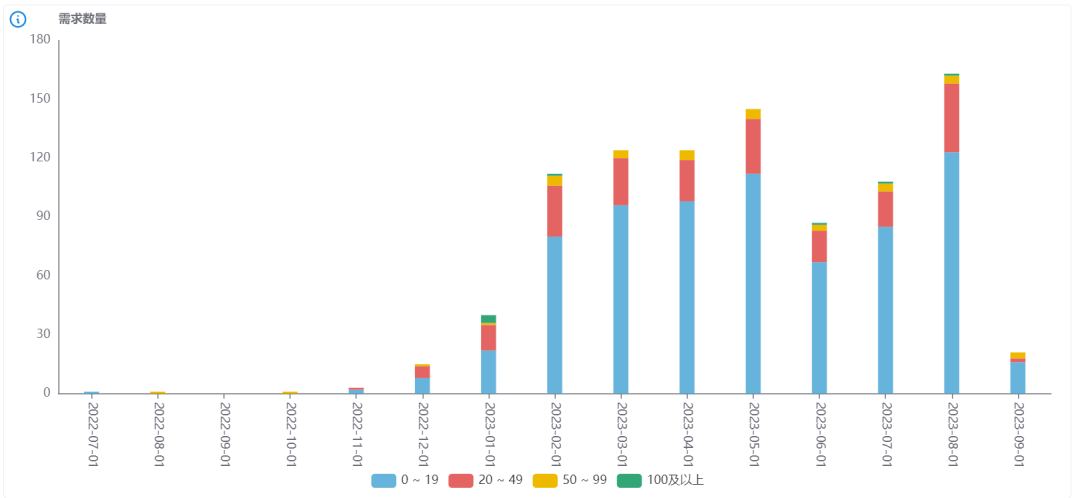
近一年「月需求吞吐量」变化
首先,已完成需求 要满足以下条件:需求下所有任务的最晚「预计结束」均在时间筛选范围内 & 需求状态 = 完成or已复盘。在下图中,我们用不同颜色来表示需求工时(人天),即需求下所有技术任务「预估工时」的累计。用于区分需求大小,分为4个区间, 0-19;>=20 - 49;>=50 - 99;>=100。光有工时还不够精准,后续还可以将需求与当量关联,用当量区分需求大小,并校准工时,进行更科学地度量。
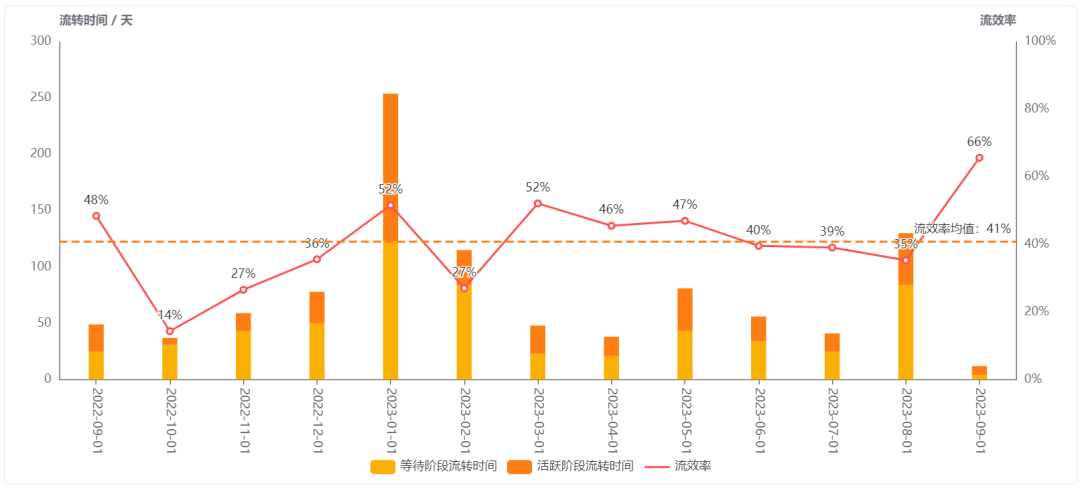
近一年需求交付「流效率」趋势变化
需求从创建到完成,交付过程的流效率 = 单位时间内已交付需求的总活跃时间 / (总活跃时间+总等待时间)。我们需要评估一年的需求交付流效率的趋势变化,来辅助解答交付效率有哪些变化。如下图所示,可以看到有两类需求,一种是处于活跃阶段(开发中、测试中),还有一种是等待阶段(规划中、BRD评审通过、暂停等),我们可以通过曲线来观察流效率,并可以看到流效率在什么时间段低于了均值(图中虚线)。如果持续低于均值,则需要管理者进一步下钻找出问题根源。
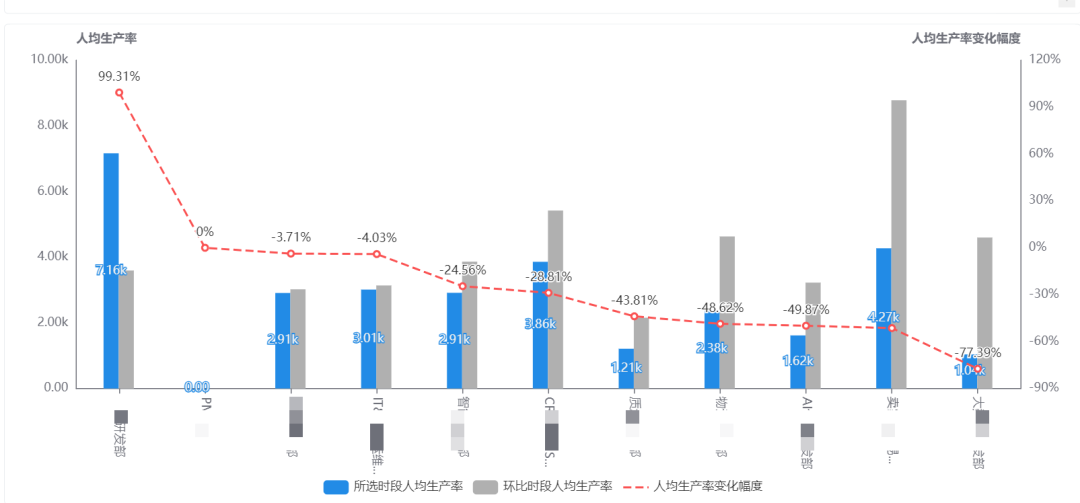
技术中心「各团队」月生产率环比
观察各团队生产率的环比变化,判断生产率是否相对平稳、产出效率是否与任务交付规划相符。
4)针对交付质量
通过数据回答的问题:
需求的交付质量趋势变化如何?外部质量是否逐渐平稳或需要加强内建质量?
近一年「线上缺陷」逃逸率
观察线上缺陷逃逸率的变化,如果呈上升状态,提示关注内部质量风险,针对性投入内部质量成本。具体的计算方式是:
线上缺陷逃逸率 = 生产缺陷数量 / (测试缺陷数量 + 生产缺陷数量 + 缺陷类型为”空“的缺陷数量)
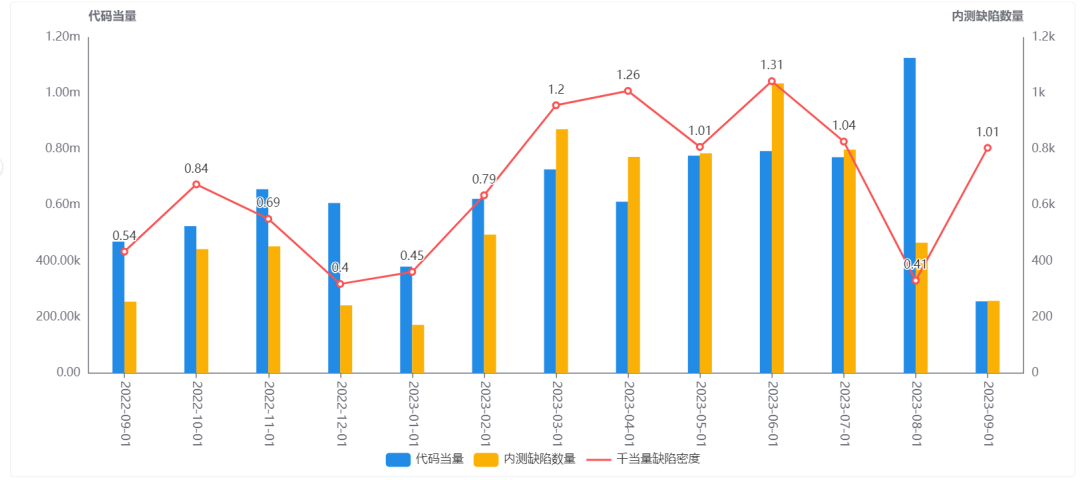
近一年千当量「测试缺陷」密度
观察内测千当量缺陷密度的变化,如果呈上升状态,提示关注开发质量、需求质量等质量左移测试是否到位。如下图所示:
-
千当量测试缺陷密度 = 月创建的内测缺陷数量 / 月新增千代码当量。
三、如何利用双周报告辅助团队领导管理研发过程、打造改进闭环
度量目标:各团队通过过程指标及时识别自身效能问题,跟随迭代改进。
相对于上述两个角色,团队 Leader 需要从项目、项目对比两个维度来度量分析交付成本、交付效率、交付质量。差别也很容易理解:
1、围绕项目整体度量,重点在于单个项目的三项指标变化;
2、项目对比,则是横向对比多个项目在成本、效率等方面的表现。
1)围绕项目整体
1.1)针对交付成本
通过数据回答的问题:
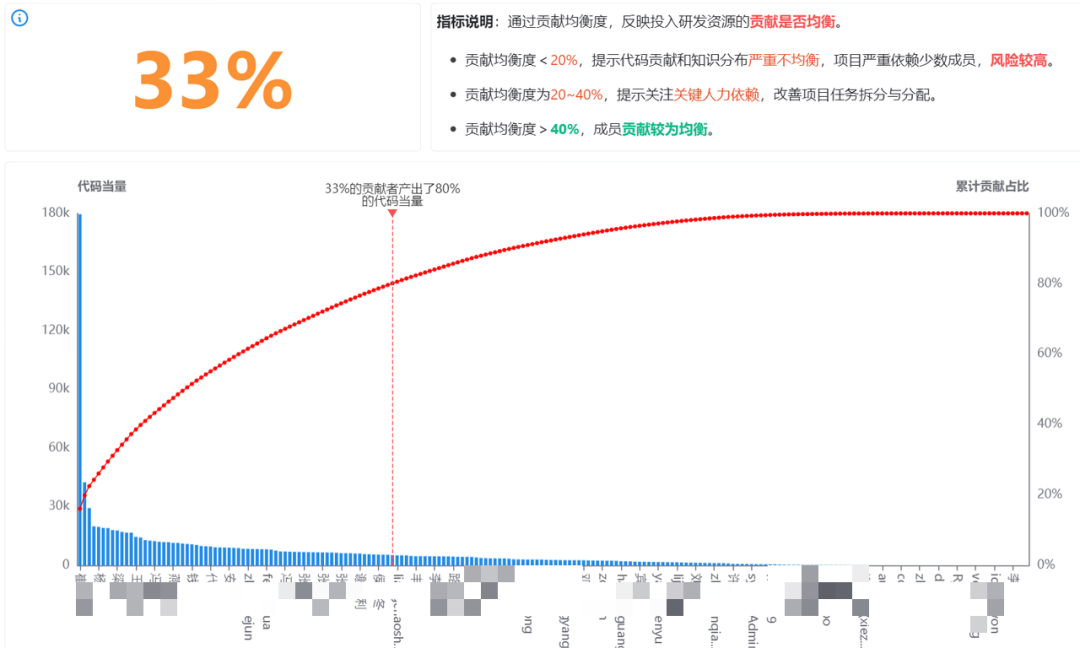
项目上投入的资源成本对项目的代码贡献是否均衡?
针对这个问题,DevInsight提供了“贡献均衡度”看板,用来度量分析开发资源代码产出是否均衡。通过计算一个时间周期内,团队每个成员提交的代码当量,来观察团队的均衡度。我们会将团队整体提交的代码当量的 80%作为一条基准线,如果<20%的贡献者产出了 80%的代码当量,则说明团队的贡献均衡度不均衡,有的项目严重依赖少数成员,需要及时调整,避免部分成员过于劳累。如果有>40%的贡献者产出了 80%的代码当量,那么说明贡献均衡度比较均衡。
1.2)交付效率
通过数据回答的问题:
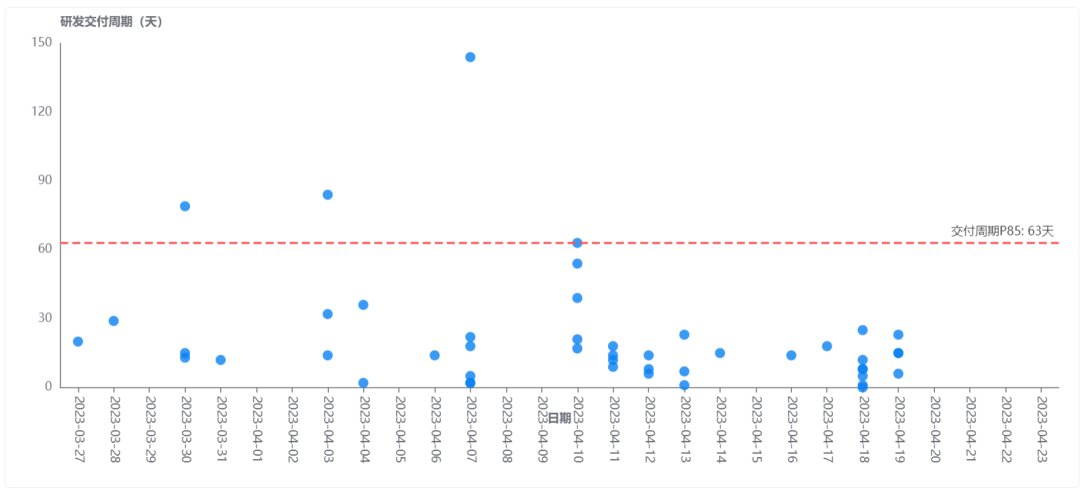
哪些需求的交付周期偏长?需求交付趋势是否平稳?
需要要接交付周期,那么就要度量需求受理后的交付速度,而且这个指标需要具备预测性,能通过现在的需求交付速度来判断未来新需求交付时长,这样才能对超出预期交付周期的需求进行管理。
另一方面,我们还需要度量需求吞吐量(单位时间内交付的需求数量),从而合理规划业务目标、项目计划,管理整体的交付趋势。
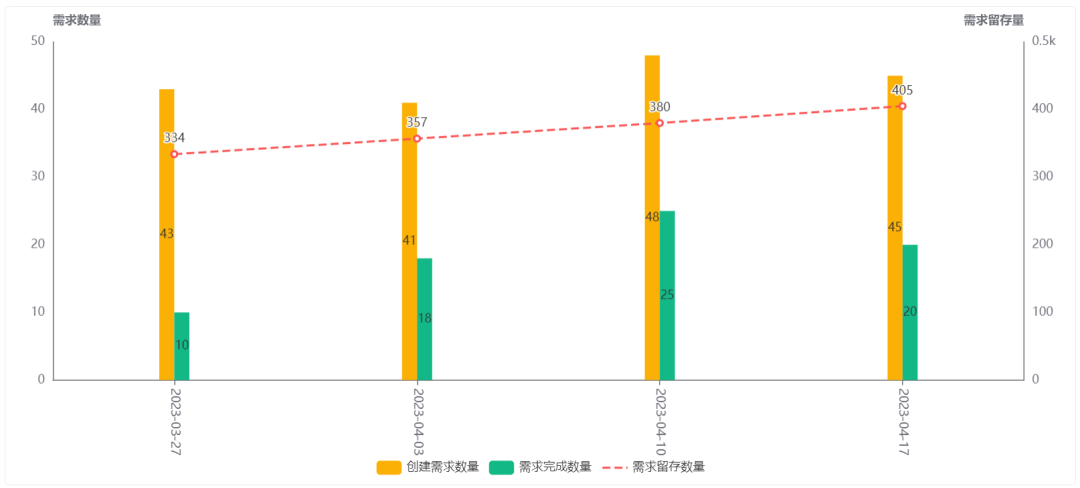
1.3)交付质量
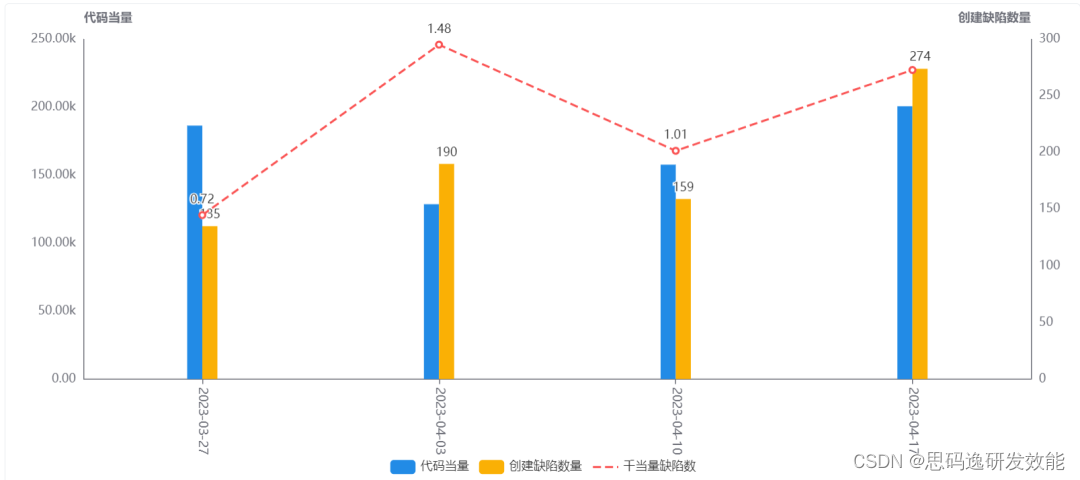
通过数据回答的问题:
需求的交付质量趋势变化如何?外部质量是否逐渐平稳或需要加强内建质量?
这里的度量目标是通过千当量缺陷密度的趋势变化,判断内测质量是否平稳,若趋势上升提示关注提测风险、内建质量风险。那么我们采用的千当量缺陷密度(测试提交BUG)作为度量指标,即周期时间内内测新增缺陷与新增代码当量的比值。
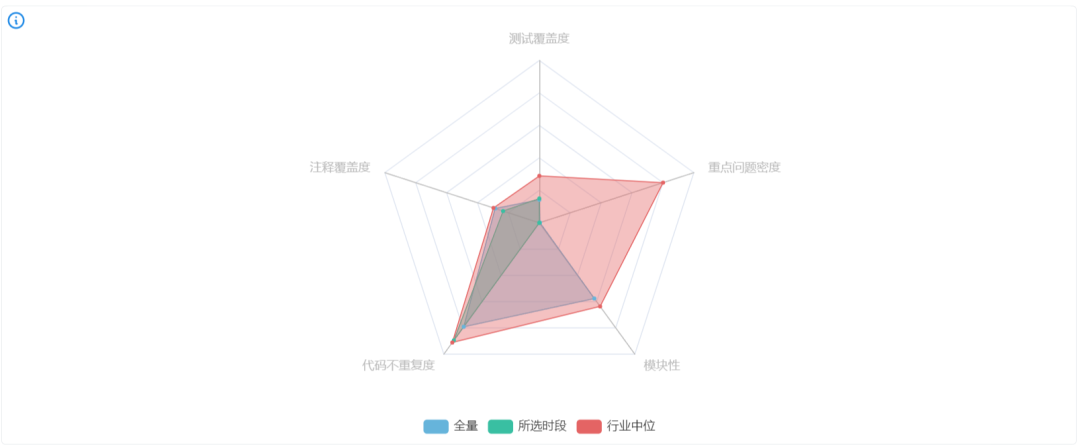
研发工程质量可以反映项目整体及所选时段增量代码的内建质量,同时与与行业中等水平的对比作为参考。
2)项目对比
2.1)交付成本
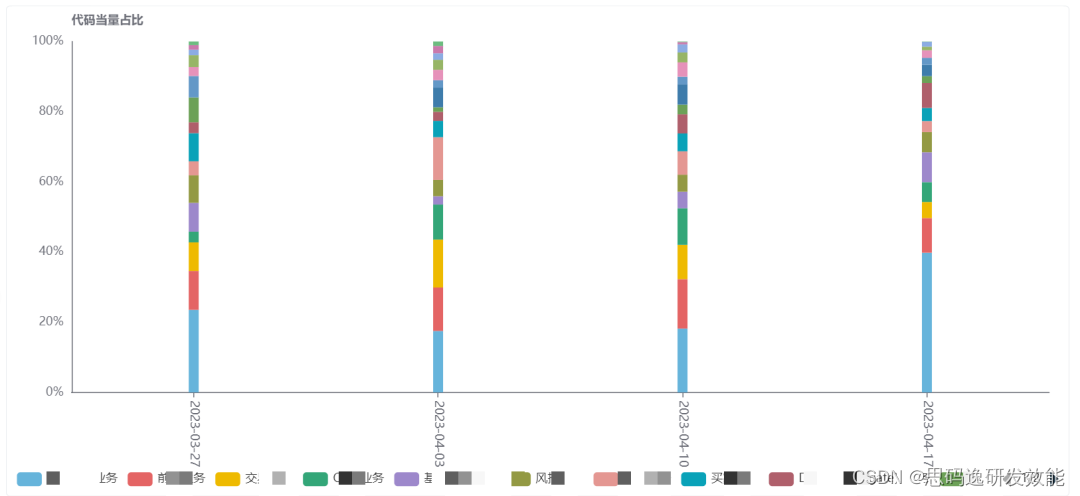
通过数据回答的问题:
各项目投入的研发成本变化如何,是否符合整体计划或预期?
其中我们可以客观量化的就是项目中编程的工作量投入占比,如图中所示,通过新增代码当量指标来进行度量,图中不同颜色代表了不同业务消耗的研发成本(这里用当量衡量)随时间的变化情况,我们通过这样的占比统计可以分析出当前业务成本投入是否符合预期。团队 Leader 可以通过调配资源,将团队重心放在关键项目上。
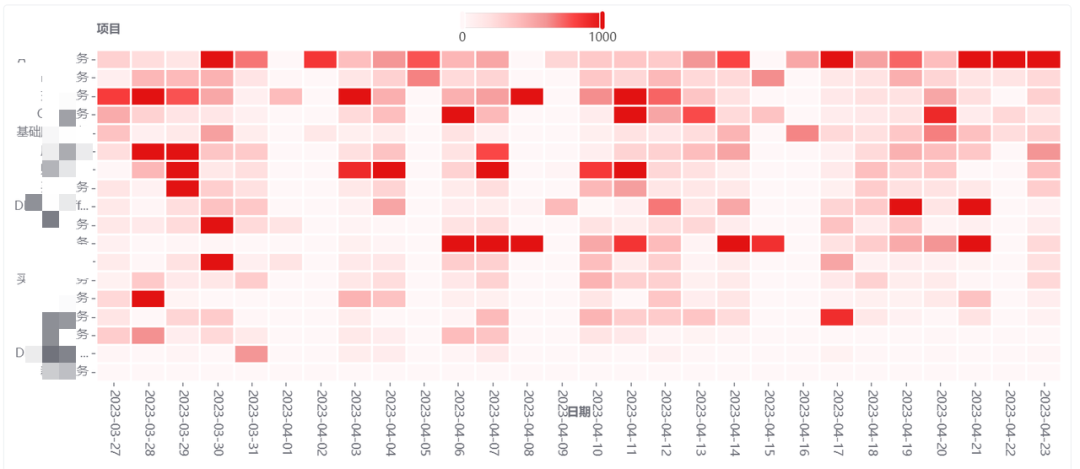
项目任务饱和度:日人均当量
通过数据回答的问题:
哪些项目资源负载过高或偏低,是否需要进行项目间的资源调配?
要解决这个问题,我们就需要度量需求受理后的交付速度,即研发交付周期。这个指标反映了各个项目贡献者每日生产率的变化,如下图看板所示,颜色越深代表生产率越高、任务越繁忙。
如果连续多个工作日无代码提交,则意味着资源出现空置和或积压提交,那么管理者需要考虑进行合理的任务拆分或项目间资源调配。反之,如果连续多个非工作日高生产率,那么意味着出现了任务溢出,建议此时管理者关注质量和进度风险。
2.2)交付效率
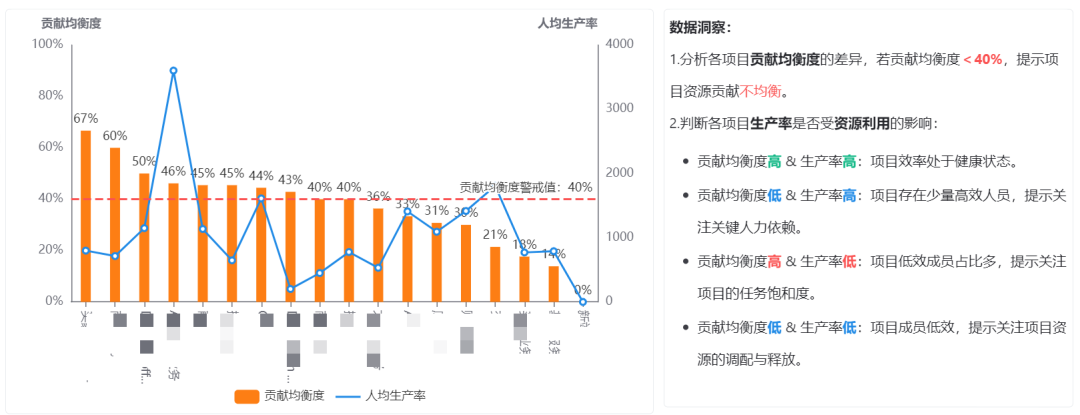
通过数据回答的问题:
不同项目的研发效率如何?资源贡献均衡度是否对项目效率有负向影响?
如果要解答这个问题,我们就需要将资源贡献均衡度和项目交付效率放在一起进行对比。所以我们在 DevInsight 中提供了这样一个看板,如下图所示。通过图中右侧的专家系统可以看到,该企业设定了贡献均衡度的预警阈值为 40%,如果均衡度低于这个值,就说明资源贡献不均衡。同时,配合折线可以观察项目的研发生产效率趋势。
项目研发生产率 VS 贡献均衡度
2.3)交付质量
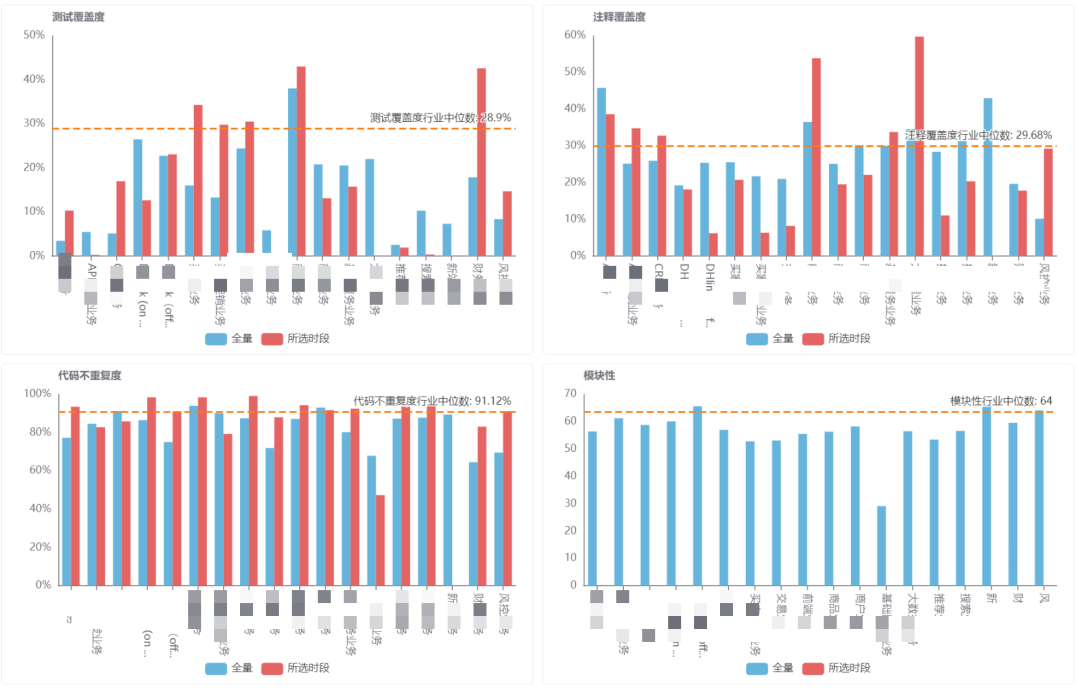
通过数据回答的问题:
哪些项目的内建质量需要重点关注和提升?
思码逸DevInsight 提供了这样一个看板,可以度量每个项目的内建质量。图中的行业中位数的数据是来自于行业中部分热门开源项目,可以为企业提供一个行业参考。注意,图中「模块性」指标不支持局部时间段的统计,图表中将仅显示代码库全量统计数值
小结
思码逸 DevInsight 研发效能度量分析平台从项目、团队、个人的角度,度量研发项目的产出、需求交付效率、内建质量等指标,帮助企业的高层、中层管理者,以及团队 leader 洞察交付成本、交付效率、交付质量情况,解决了研发价值反馈不透明,以及管理层中不同角色对研发效能不同指标的度量、分析需求。如果大家还希望了解更多案例,欢迎访问思码逸官网或免费预约试用。如果您希望快速交流更多最佳实践案例,可扫描小助手联系效能顾问。














 52
52











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









