







一说到缓存,有没有脑海里立马想到的是guava cache、ehcache、redis、memerycache等等这些和缓存相关的技术实现,计算机专业出生可能还会想到cpu的一级缓存、二级缓存、三级缓存等等。以说到缓存,层出不穷的技术可以列举非常多,那么到底什么是缓存?guava cache是缓存么?是也不是;redis是缓存的,是也不是,那么下面就说下我对缓存的看法
我对缓存的认识就是:当多个系统(组件、甚至是软件分层)之间,处理一件事情的时候,有速度差异的时候,为了提高速度,将上一层的处理结果记录下来,后续的访问就直接从本层拿到记录下来的结果,而不需要去上一层去获取结果,从而提高整体的响应速度。
从这个角度来看,理解下cpu的高速缓存:
高速缓存产生的背景就是:cpu需要的数据都是从内存中读取的,但是内存的速度和cpu的速度相差好几个数量级,为了更高效的利用cpu的计算能力,平衡内存和cpu之间的效率差距,引入高速缓存。cpu不是从内存中直接获取数据,而只是和高速缓存交互,如果高速缓存中有,就直接用高速缓存中的数据;如果没有就去内存转给你读取。这个地方缓存是站在cpu的角度来说,高速缓存记录的就是从内存中拿到的结果一次提高效率。
应用缓存:
一个应用所需要的数据很多,有的是来自磁盘,比如配置文件,有的是来自db,比如业务数据。应用数据要获取这些数据都需要经过IO去获取,为了提高效率,应用中可以将拿到的数据放到自己本地内存中,这样后续需要这些数据的时候就从内存中取就好了。
所以说,凡是使用了一个更高效的方式来冗余数据,而为了获取这些数据是比较耗时的,那这种都可以认为是缓存。缓存不一定是内存,那些镜像站其实也是缓存,比如github,maven仓库等,直接去访问美国的仓库是比较慢的,所以在国内有很多镜像站,本质也是缓存。
下面从内存缓存的角度看,可以有哪些通用的实现以及他们的实现原理及细节。
HashMap
利用HashMap就可以实现一个简单的缓存,将一些获取比较耗时的结果放到HashMap中,后续就读取就好了。一个比较典型的应用场景就是反射缓存,在几乎所有的框架中都会将反射给缓存起来的,还有就是一个小的优化就是枚举的反序列化缓存,总之像这种固定不变的东西,而总量是有限的,还是比较适合用HashMap来做缓存的。
但是内存毕竟是有限的,所以当缓存的数据越来越多,最终可能导致OOM,所以缓存一定要有度,也就是说当缓存数据达到一定的阈值时,应该有策略淘汰掉一部分,不能让缓存无限增长,最终导致进程崩溃,或者说不能让缓存占用过多的内存以影响程序的正常运行,。
HashMap肯定是没有数据淘汰机制的,所以一般直接用HashMap来作为缓存的基本都是确定数据有限的场景,比如上述的反射缓存,配置文件缓存等。
一种简单的缓存淘汰方式就是FIFO,在数据写入的时候,将数据放到队头。那也就是先被更新的被先淘汰。这个其实是不合理的,缓存优化的是查询效率,那这样会让缓存命中率比较低。试想,更新频率不大,但是查询不大的数据会被淘汰出缓存,这肯定不合理,缓存优化的就是更新不大,查询大的场景,让查询更高效。所以FIFO不适合做为缓存淘汰策略,一种更加好的方式就是LRU算法那。
LRU缓存
LRU缓存就是使用LRU淘汰算法的缓存结构。所谓的LRU直接翻译就Latest Recent Used,它的理论基础就是:如果一个数据被访问了,那么它在接下来还会被访问的可能性非常大,所以当内存不够用的时候,那么先淘汰哪些最久没有被访问过的。
基于这个理论,实现LRU的常见方式就是基于链表:每次访问一个数据的时候都将这个数据移动到链表头部,然后内存不够需要淘汰的时候,直接删除链表尾部元素,从而实现LRU。
基于单个链表的实现

问题:
1. 访问速度是O(n),即每次根据key查询数据的时候都需要遍历链表,这是不能接受的。
链表+HashMap实现
链表的方式比较方便的实现了LRU,只是需要移动一下指正就能够完成LRU算法,这个过程是O(1)的,但是查询是个O(n)的操作。HashMap的查询是O(1)的,所以链表结合HashMap可以实现O(1)的查询。
基本结构入下:

- 链表是用来存储key-value换出数据的。
- 每次访问的时候,将访问的节点都放到链表头部,然后当链表元素个数超过容量的时候,从尾部删除。这样依靠链表的头尾来实现LRU算法。
- HashMap的作用其实就是索引,实现O(1)的数据访问
- ps:这里区分下jdk中HashMap中用链表法解决hash冲突的那个链表,这里的链表不是一回事,如果将HashMap解决冲突的量表也画进来,结构应该是这样的

插入缓存put()方法逻辑:

缓存查询get()方法逻辑:
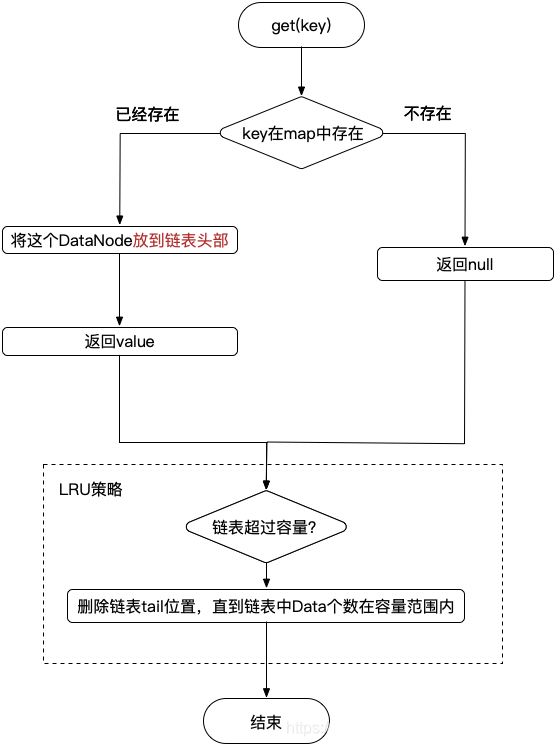
这个方式是是实现了最基本最朴素的LRU,这里的HashMap+链表的结构,jdk中已经有一个专门的结构进行了封装LinkedHashMap,也就是说LinkedHashMap已经实现了LRU了,只是需要在构建LinkedHashMap的时候,传入入参accessOrder=true,在put()/get()的时候,就会将访问的数据放到链表头部,这正是LRU淘汰的基础。但是,LinkedHashMap默认没有实现当数据量到达初始化容量的时候,是扩容了,而不是淘汰数据,但是给了扩展接口,只需要需要自己重写实现一下removeEldestEntry()这个接口,那就有LRU的效果啦。
class LinkedHashMapBaseLRUCache<K, V> extends LinkedHashMap {
private int capacity;// 这是缓存的大小
public LinkedHashMapBaseLRUCache(int capacity) {
// 这是HashMap的大小,可以不一致,也可以一致。
super(16, 0.75f, true);
this.capacity = capacity;
}
@Override
protected boolean removeEldestEntry(Map.Entry eldest) {
return super.size() > capacity;
}
}这仅仅是一个实现了基本的LRU算法的一个缓存,但是实际上要成为一个好用的缓存,还需要跟多额外的功能,比如:
1. 按照访问时间的自动过期机制。
2. 缓存内存控制,比如当jvm内存告警,淘汰缓存,即缓存使用WeakReference,而不是强引用。
3. 并发控制
4. 。。。
但是,很多缓存的实现的基础都是双链表+HashMap的思路,然后在这基础之上做了一些优化以及功能加强。下面会详细分析的guava cache基本结构也是如此。
堆
其实LRU就是一个按照访问时间排序的优先队列,而堆天生就是个优先队列,所以说堆天然就有LRU的特点。但是堆的操作中实际上没有查找任意元素,由于堆的特点,它不是一个搜索树,所以查找任意元素的效率O(n),但是插入/删除一个元素都是O(lgn)的,总体相比于hashMap+链表的实现,效率上逊色不少。
guava cache
guava cache是guava实现的一个通用的进程内的内存缓存,其提供了丰富api来满足不同的使用场景。上面也提到了,它的实现基础也是HashMap+链表的方式。
理解guava cache主要看它如何实现如下4个功能
1. 缓存数据结构
2. 如何实现定时清除的
3.如何实现LRU
4. 线程安全
guava cache的实现虽然也是hashMap+链表的方式,但他没有直接使用jdk线程的HashMap,而是自己实现了一个HasnMap。考虑到线程安全问题,guava 在实现这个HashMap的时候采用了jdk7中
ConcurrentHashMap一样的思路:分段。
如下就是guava cache的整体结构:上半个虚线框是HashMap部分,下半部分就是链表部分。

其中用于保存实际数据的ReferenceEntry结构,对于guava cache至关重要,guava cache实现除了基本的缓存数据k-v存储外,一些LRU内存淘汰策略、按照最近查询时间/最近修改时间自动过期、key和value的weak引用类型等这些都依赖于ReferenceEntry结构,其结构如下:

自动过期的实现:这个是指缓存数据具有自动过期机制,而不是坐等缓存满了才淘汰。
- StrongEntry:不具备自动过期
- StrongAccessEntry:记录查询时刻,具备按照查询时间自动过期,比如查询后5s后没有查询,这条记录就自动删除
- StrongWriteEntry:记录修改时刻,具备按照修改时间自动过期,比如插入/更新后5s后没有更新,这条记录就自动删除
- StrongAccessWriteEntry:记录查询+时刻,具备按照查询时间/修改时间过期
这样只需要获得当前时间,然后和ReferenceEntry中保存的上次访问时间比较一下,如果大于指定时间,就删除对应的数据就好了。
guava cache对key和value还是先了若引用:key可以上强引用、WeakReference;value可以是强引用、SoftReference、WeakReference。key的强弱就是ReferenceEntry的子类:StrongxxxReference,key就是强引用;是WeakxxxxReference,那key就是WeakReference,所以上面的列表中还有一个对应的WeakxxxEntry。而对于value的引用类型,ValueReference来封装的
LRU实现:实现LRU主要是靠accessQueue和recencyQueue两个队列来实现LRU
按照前述使用链表实现LRU的原理,只需要每次读/写的时候,将读/写的元素都放到链表头部,然后当发现缓存中元素个数大于最大容量的时候,就直接删除链表尾部就好了,按照这个思路,一个链表就搞定了。但是guava cache中很明显有三个,这是为啥?
- accessQueue:它的地位就是我们自己实现的朴素LRU算法中那个双向链表。当发生读/写的时候,将读写涉及到的ReferenceEntry放到链表头(队头);然后在put()的时候,如果发现缓存中已有元素个数超过了总的容量,那就从accessQueue队头出队一个元素,然后将这个元素删除(Hash表中删除+accessQueue中删除)。但是有个问题:accessQueue是LocalCache中自己实现的内部类:AccessQueue,这个类是线程不安全的,所以每次读/写的时候,要将元素移动到队头,需要先获得对应Segement的锁,然后才能操作。对于缓存来说,应用场景本身就是写少读多的,那么在写的时候,需要先获得Segement的锁才能写无可厚非,但是如果是读也要竞争这个锁就有点不好了,如果发生了竞争,就会阻塞读,这会大大影响读的QPS的,所以说读的时候不能加Segement锁,guava的解决办法就是recencyQueue。
- recencyQueue:在每次get()的时候,不会去改变accessQueue(即不会将读取到的ReferenceEntry立马放到AccessQueue的队尾),而是直接将读取到的元素插入到recencyQueue中。recencyQueue使用的是jdk的ConcurrentLinkedQueue,它实现变成安全的,所以所有线程在get()的时候可直接使用recencyQueue#add()将读取的元素添加到队尾。在get()结束的时候,会去tryLock()一下Segement锁,如果拿到锁,就会遍历recencyQueue,然后依次出队,然后将其中的ReferenceEntry在accessQueue中移动到队尾,这样recencyQueue就变成空的了,而历史读取的元素以依次在accessQueue中都放到了队尾(ps:这里可以理解成在get()读取的时候,将读取的ReferenceEntry放到accessQueu队尾是个延迟的批量操作,recencyQueue就是这个批操作的一个缓存,这个批大小LocalCache写死的为64)。这这个逻辑就是在get()的finally块中调用的postReadCleanup()实现。
ps:
1. AccessQueue#add()这个方法很特殊:如果ReferenceEntry在队列中已存在,就是将其移动到队尾;如果不存在才是添加到队尾,先了解这个逻辑,再去看代码,看到相关代码就少些疑惑。
2. 处理recencyQueue不光是在get()的最后会尝试处理,在put()的时候也会去处理(put()的时候先拿到了Segement锁,由于使用的是ReentrantLock,由于其可重入性,tryLock()一定会成功的)
问题:
1. 因为recencyQueue的原因,guava cache的读性能,是受ConcurrentLinkedQueue的写入性能约束的。而且如果写入也比较大,持续竞争的话,可能导致recencyQueue非常大。
2. 不管是LRU淘汰,还是最近访问时间自动淘汰机制、还是WeakReference情况下具体的缓存数据被gc掉了去清理引用,这三种情况的清理都是在put()/get()方法执行过程中,同步去执行的,这势必会影响读写QPS的。
3. 所有的key的有效期都是一样的,没办法为不同key设置不同的有效期。ps:Caffine好像也不行。
4. LRU算法本身的问题:对于偶发的批量数据读取,会污染缓存中的数据,导致将真正的热点数据挤出缓存。为了解决这个问题,有很多对LRU的优化,比如Innodb中对LRU的优化LRU算法及其优化策略——算法篇 - 掘金。另外redis也是使用了LRU算法,但是实现上也做了一些优化:
redis的淘汰策略:Redis优化--LRU和LFU区别 - it610.com
guava cache的使用例子
Cache<String, String> cache =
CacheBuilder.newBuilder()
.maximumSize(4)// cache的最大容量,超过后将使用LRU淘汰 这个是基于缓存总容量的淘汰:即缓存的数据量达到了maximumSize,就开始按照LRU淘汰
//.maximumWeight(12)// maximumWeight+weigher,maximumWeight指定的是最大权重,weigher是一个权重比例。
//.weigher(null)// 如果不指定,默认实现的weigher就是OneWeigher,返回的权重就是1,这个时候跟总量maximumSize的淘汰是一样的,maximumWeight就是最大容量。
.concurrencyLevel(1)// 这个命名其实还是蛮讲究的,guava cache其内部的HashMap是采用分段来实现的,一个分段独享一把锁,按有多少个分段,那么统一时刻就允许有多少线程操作HashMap
// ,所以说白了这里的ConcurrentLevel就是分段个数。
.initialCapacity(2)// HashMap的初始容量,也就是说初始化的时候并不会直接初始化一个maximumSize大小的hashMap,而是初始化一个initialcapacity
// 大小,后续需要的时候会扩容。真实存储数据的是在Segement中,
// 所以初始化的时候根据concurrencyLevel决定创建多少了Segment,然后根据initialCapacity/concurrencyLevel决定Segement中数组的大小
.weakKeys()//默认情况,Cache中的key和value都是强引用。weakKeys()开启后,key将使用WeakReference引用
//.weakValues() // 开启后value的引用就是WeakReference
//.softValues() // 开启后value的引用就是SoftReference
//.expireAfterWrite(3, TimeUnit.SECONDS)// 写入过后3s后没有访问,自动过期删除
//.expireAfterAccess(3,TimeUnit.SECONDS)// 读取过后3s没有访问,自动删除过期。
.refreshAfterWrite(3, TimeUnit.SECONDS)// 自从上上次写入后,没隔3s调用cacheLoader去自动更新一遍数据。
// 这里需要注意,guava的实现并不是真的起了个异步任务在做这个事情,而是在查询的时候去检查,如果上次写入时间举当前超过了3s,就去重新load一遍,去看实现上虽然表面上看是异步执行的呀,
// 但默认实现上是sameThreadExecutor,其实就是同步执行的,所以如果生产环境中要设置这个参数就要注意了,这个相当于没隔3s的get()查询都会去调用一遍CacheLoad。
.recordStats()//打开统计信息:如缓存命中率等,这个是有一些开销的
.removalListener(
new MyRemovalListener<String, String>())// 当一个entry删除的时候(主动删除or缓存淘汰删除)
// ,会调用指定的Listener。具体哪些场景会调用这个removeListener参考:RemovalCause
//.ticker(null)// 实际就是一个时间计时器,用于计算entry是否过期。默认就是System.nanoTime(),这个跟guava StopWatch是一样的
.build(new MyCacheLoader());CacheLoader的实现例子:
// 当设置了refreshAfterWrite(3, TimeUnit.SECONDS)参数,那么当数据距离上次写入3s后,再次调用get()的时候,会自动去调用reload()方法重新加载数据,刷新一遍。
// 但是默认实现的reload()方法是同步的,即直接调用了CacheLoader#load(),这里我们可以重新实现reload()变成变成异步的。
@Override
public ListenableFuture reload(String key, String oldValue) throws Exception {
Future<String> future = executorService.submit(new Callable<String>() {
@Override
public String call() throws Exception {
System.out.println("reload thread:" + Thread.currentThread().getId());
return key+"-reload";
}
});
// 这里这么写是掩耳盗铃的,需要自己实现ListableFuture,这个地方即使是实现了异步,其实也只是和一些内存处理并行。
// 如果在这些内存操作处理结束,这里的load还没有加载成功,那么就会丢掉这里reload的结果,所以要自己实现异步的时候一定要注意一下
return Futures.immediateFuture(future.get());
}RemovalListener的实现
class MyRemovalListener<K, V> implements RemovalListener {
@Override
public void onRemoval(RemovalNotification notification) {
System.out.println("删除了," + notification.getKey() + "=" + notification.getValue() + " cause:" + notification.getCause());
}
}
参考:
1. LRU算法及其优化策略——算法篇 - 掘金 这个文章比较详细介绍了从最朴素的LRU以及一些优化的LRU算法
2. 你应该知道的缓存进化史 - 咖啡拿铁的技术分享的个人空间 - OSCHINA - 中文开源技术交流社区 这个文章比较详细介绍了集中缓存的实现,并结合guava cache的源码详细介绍了guava cache的使用及对应原理
附件:LocalCache的注释,以供参考:
/*
* Copyright (C) 2009 The Guava Authors
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package com.zj.cache.guavacache;
import CacheLoader.InvalidCacheLoadException;
import com.google.common.annotations.GwtCompatible;
import com.google.common.annotations.GwtIncompatible;
import com.google.common.annotations.VisibleForTesting;
import com.google.common.base.Equivalence;
import com.google.common.base.Function;
import com.google.common.base.Stopwatch;
import com.google.common.base.Ticker;
import com.google.common.cache.AbstractCache.SimpleStatsCounter;
import com.google.common.cache.AbstractCache.StatsCounter;
import com.google.common.cache.*;
import com.google.common.collect.*;
import com.google.common.primitives.Ints;
import com.google.common.util.concurrent.*;
import javax.annotation.Nullable;
import javax.annotation.concurrent.GuardedBy;
import java.io.IOException;
import java.io.ObjectInputStream;
import java.io.Serializable;
import java.lang.ref.Reference;
import java.lang.ref.ReferenceQueue;
import java.lang.ref.SoftReference;
import java.lang.ref.WeakReference;
import java.util.*;
import java.util.concurrent.*;
import java.util.concurrent.atomic.AtomicInteger;
import java.util.concurrent.atomic.AtomicReferenceArray;
import java.util.concurrent.locks.ReentrantLock;
import java.util.logging.Level;
import java.util.logging.Logger;
import static com.google.common.base.Preconditions.checkNotNull;
import static com.google.common.base.Preconditions.checkState;
import static com.google.common.util.concurrent.Uninterruptibles.getUninterruptibly;
import static com.zj.cache.guavacache.CacheBuilder.NULL_TICKER;
import static com.zj.cache.guavacache.CacheBuilder.UNSET_INT;
import static java.util.concurrent.TimeUnit.NANOSECONDS;
/**
* The concurrent hash map implementation built by {@link com.zj.cache.guavacache.CacheBuilder}.
*
* <p>This implementation is heavily derived from revision 1.96 of <a
* href="http://tinyurl.com/ConcurrentHashMap">ConcurrentHashMap.java</a>.
*
* @author Charles Fry
* @author Bob Lee ({@code com.google.common.collect.MapMaker})
* @author Doug Lea ({@code ConcurrentHashMap})
*/
@GwtCompatible(emulated = true)
class LocalCache<K, V> extends AbstractMap<K, V> implements ConcurrentMap<K, V> {
/*
* The basic strategy is to subdivide the table among Segments, each of which itself is a
* concurrently readable hash table. The map supports non-blocking reads and concurrent writes
* across different segments.
*
* If a maximum size is specified, a best-effort bounding is performed per segment, using a
* page-replacement algorithm to determine which entries to evict when the capacity has been
* exceeded.
*
* The page replacement algorithm's data structures are kept casually consistent with the map. The
* ordering of writes to a segment is sequentially consistent. An update to the map and recording
* of reads may not be immediately reflected on the algorithm's data structures. These structures
* are guarded by a lock and operations are applied in batches to avoid lock contention. The
* penalty of applying the batches is spread across threads so that the amortized cost is slightly
* higher than performing just the operation without enforcing the capacity constraint.
*
* This implementation uses a per-segment queue to record a memento of the additions, removals,
* and accesses that were performed on the map. The queue is drained on writes and when it exceeds
* its capacity threshold.
*
* The Least Recently Used page replacement algorithm was chosen due to its simplicity, high hit
* rate, and ability to be implemented with O(1) time complexity. The initial LRU implementation
* operates per-segment rather than globally for increased implementation simplicity. We expect
* the cache hit rate to be similar to that of a global LRU algorithm.
*/
// Constants
/**
* The maximum capacity, used if a higher value is implicitly specified by either of the constructors with arguments. MUST be a power of
* two <= 1<<30 to ensure that entries are indexable using ints.
*/
static final int MAXIMUM_CAPACITY = 1 << 30;
/**
* The maximum number of segments to allow; used to bound constructor arguments.
*/
static final int MAX_SEGMENTS = 1 << 16; // slightly conservative
/**
* Number of (unsynchronized) retries in the containsValue method.
*/
static final int CONTAINS_VALUE_RETRIES = 3;
/**
* Number of cache access operations that can be buffered per segment before the cache's recency ordering information is updated. This
* is used to avoid lock contention by recording a memento of reads and delaying a lock acquisition until the threshold is crossed or a
* mutation occurs.
*
* <p>This must be a (2^n)-1 as it is used as a mask.
*/
static final int DRAIN_THRESHOLD = 0x3F;//十进制63
/**
* Maximum number of entries to be drained in a single cleanup run. This applies independently to the cleanup queue and both reference
* queues.
*/
// TODO(fry): empirically optimize this
static final int DRAIN_MAX = 16;
// Fields
static final Logger logger = Logger.getLogger(LocalCache.class.getName());
static final ListeningExecutorService sameThreadExecutor = MoreExecutors.sameThreadExecutor();
/**
* Mask value for indexing into segments. The upper bits of a key's hash code are used to choose the segment.
*/
final int segmentMask;
/**
* Shift value for indexing within segments. Helps prevent entries that end up in the same segment from also ending up in the same
* bucket.
*/
final int segmentShift;
/**
* The segments, each of which is a specialized hash table.
*/
final Segment<K, V>[] segments;
/**
* The concurrency level.
*/
final int concurrencyLevel;
/**
* Strategy for comparing keys.
*/
final Equivalence<Object> keyEquivalence;
/**
* Strategy for comparing values.
*/
final Equivalence<Object> valueEquivalence;
/**
* Strategy for referencing keys.
*/
final Strength keyStrength;
/**
* Strategy for referencing values.
*/
final Strength valueStrength;
/**
* The maximum weight of this map. UNSET_INT if there is no maximum.
*/
final long maxWeight;
/**
* Weigher to weigh cache entries.
*/
final Weigher<K, V> weigher;
/**
* How long after the last access to an entry the map will retain that entry.
*/
final long expireAfterAccessNanos;
/**
* How long after the last write to an entry the map will retain that entry.
*/
final long expireAfterWriteNanos;
/**
* How long after the last write an entry becomes a candidate for refresh.
*/
final long refreshNanos;
/**
* Entries waiting to be consumed by the removal listener.
*/
// TODO(fry): define a new type which creates event objects and automates the clear logic
final Queue<RemovalNotification<K, V>> removalNotificationQueue;
/**
* A listener that is invoked when an entry is removed due to expiration or garbage collection of soft/weak entries.
*/
final RemovalListener<K, V> removalListener;
/**
* Measures time in a testable way.
*/
final Ticker ticker;
/**
* Factory used to create new entries.
*/
final EntryFactory entryFactory;
/**
* Accumulates global cache statistics. Note that there are also per-segments stats counters which must be aggregated to obtain a global
* stats view.
*/
final StatsCounter globalStatsCounter;
/**
* The default cache loader to use on loading operations.
*/
@Nullable
final CacheLoader<? super K, V> defaultLoader;
/**
* Creates a new, empty map with the specified strategy, initial capacity and concurrency level.
*/
LocalCache(
CacheBuilder<? super K, ? super V> builder, @Nullable CacheLoader<? super K, V> loader) {
concurrencyLevel = Math.min(builder.getConcurrencyLevel(), MAX_SEGMENTS);
keyStrength = builder.getKeyStrength();
valueStrength = builder.getValueStrength();
keyEquivalence = builder.getKeyEquivalence();
valueEquivalence = builder.getValueEquivalence();
maxWeight = builder.getMaximumWeight();
weigher = builder.getWeigher();
expireAfterAccessNanos = builder.getExpireAfterAccessNanos();
expireAfterWriteNanos = builder.getExpireAfterWriteNanos();
refreshNanos = builder.getRefreshNanos();
removalListener = builder.getRemovalListener();
removalNotificationQueue = (removalListener == CacheBuilder.NullListener.INSTANCE)
? LocalCache.<RemovalNotification<K, V>>discardingQueue()
: new ConcurrentLinkedQueue<RemovalNotification<K, V>>();
ticker = builder.getTicker(recordsTime());
entryFactory = EntryFactory.getFactory(keyStrength, usesAccessEntries(), usesWriteEntries());
globalStatsCounter = builder.getStatsCounterSupplier().get();
defaultLoader = loader;
int initialCapacity = Math.min(builder.getInitialCapacity(), MAXIMUM_CAPACITY);
if (evictsBySize() && !customWeigher()) {
initialCapacity = Math.min(initialCapacity, (int) maxWeight);
}
// Find the lowest power-of-two segmentCount that exceeds concurrencyLevel, unless
// maximumSize/Weight is specified in which case ensure that each segment gets at least 10
// entries. The special casing for size-based eviction is only necessary because that eviction
// happens per segment instead of globally, so too many segments compared to the maximum size
// will result in random eviction behavior.
int segmentShift = 0;
int segmentCount = 1;
while (segmentCount < concurrencyLevel
&& (!evictsBySize() || segmentCount * 20 <= maxWeight)) {
++segmentShift;
segmentCount <<= 1;
}
this.segmentShift = 32 - segmentShift;
segmentMask = segmentCount - 1;
this.segments = newSegmentArray(segmentCount);
int segmentCapacity = initialCapacity / segmentCount;
if (segmentCapacity * segmentCount < initialCapacity) {
++segmentCapacity;
}
int segmentSize = 1;
while (segmentSize < segmentCapacity) {
segmentSize <<= 1;
}
if (evictsBySize()) {
// Ensure sum of segment max weights = overall max weights
long maxSegmentWeight = maxWeight / segmentCount + 1;
long remainder = maxWeight % segmentCount;
for (int i = 0; i < this.segments.length; ++i) {
if (i == remainder) {
maxSegmentWeight--;
}
this.segments[i] =
createSegment(segmentSize, maxSegmentWeight, builder.getStatsCounterSupplier().get());
}
} else {
for (int i = 0; i < this.segments.length; ++i) {
this.segments[i] =
createSegment(segmentSize, UNSET_INT, builder.getStatsCounterSupplier().get());
}
}
}
boolean evictsBySize() {
return maxWeight >= 0;
}
boolean customWeigher() {
return weigher != OneWeigher.INSTANCE;
}
boolean expires() {
return expiresAfterWrite() || expiresAfterAccess();
}
boolean expiresAfterWrite() {
return expireAfterWriteNanos > 0;
}
boolean expiresAfterAccess() {
return expireAfterAccessNanos > 0;
}
boolean refreshes() {
return refreshNanos > 0;
}
boolean usesAccessQueue() {
return expiresAfterAccess() || evictsBySize();
}
boolean usesWriteQueue() {
return expiresAfterWrite();
}
boolean recordsWrite() {
return expiresAfterWrite() || refreshes();
}
boolean recordsAccess() {
return expiresAfterAccess();
}
boolean recordsTime() {
return recordsWrite() || recordsAccess();
}
boolean usesWriteEntries() {
return usesWriteQueue() || recordsWrite();
}
boolean usesAccessEntries() {
return usesAccessQueue() || recordsAccess();
}
boolean usesKeyReferences() {
return keyStrength != Strength.STRONG;
}
boolean usesValueReferences() {
return valueStrength != Strength.STRONG;
}
enum Strength {
/*
* TODO(kevinb): If we strongly reference the value and aren't loading, we needn't wrap the
* value. This could save ~8 bytes per entry.
*/
STRONG {
@Override
<K, V> ValueReference<K, V> referenceValue(
Segment<K, V> segment, ReferenceEntry<K, V> entry, V value, int weight) {
return (weight == 1)
? new StrongValueReference<K, V>(value)
: new WeightedStrongValueReference<K, V>(value, weight);
}
@Override
Equivalence<Object> defaultEquivalence() {
return Equivalence.equals();
}
},
SOFT {
@Override
<K, V> ValueReference<K, V> referenceValue(
Segment<K, V> segment, ReferenceEntry<K, V> entry, V value, int weight) {
return (weight == 1)
? new SoftValueReference<K, V>(segment.valueReferenceQueue, value, entry)
: new WeightedSoftValueReference<K, V>(
segment.valueReferenceQueue, value, entry, weight);
}
@Override
Equivalence<Object> defaultEquivalence() {
return Equivalence.identity();
}
},
WEAK {
@Override
<K, V> ValueReference<K, V> referenceValue(
Segment<K, V> segment, ReferenceEntry<K, V> entry, V value, int weight) {
return (weight == 1)
? new WeakValueReference<K, V>(segment.valueReferenceQueue, value, entry)
: new WeightedWeakValueReference<K, V>(
segment.valueReferenceQueue, value, entry, weight);
}
@Override
Equivalence<Object> defaultEquivalence() {
return Equivalence.identity();
}
};
/**
* Creates a reference for the given value according to this value strength.
*/
abstract <K, V> ValueReference<K, V> referenceValue(
Segment<K, V> segment, ReferenceEntry<K, V> entry, V value, int weight);
/**
* Returns the default equivalence strategy used to compare and hash keys or values referenced at this strength. This strategy will
* be used unless the user explicitly specifies an alternate strategy.
*/
abstract Equivalence<Object> defaultEquivalence();
}
/**
* Creates new entries.
*/
enum EntryFactory {
STRONG {
@Override
<K, V> ReferenceEntry<K, V> newEntry(
Segment<K, V> segment, K key, int hash, @Nullable ReferenceEntry<K, V> next) {
return new StrongEntry<K, V>(key, hash, next);
}
},
STRONG_ACCESS {
@Override
<K, V> ReferenceEntry<K, V> newEntry(
Segment<K, V> segment, K key, int hash, @Nullable ReferenceEntry<K, V> next) {
return new StrongAccessEntry<K, V>(key, hash, next);
}
@Override
<K, V> ReferenceEntry<K, V> copyEntry(
Segment<K, V> segment, ReferenceEntry<K, V> original, ReferenceEntry<K, V> newNext) {
ReferenceEntry<K, V> newEntry = super.copyEntry(segment, original, newNext);
copyAccessEntry(original, newEntry);
return newEntry;
}
},
STRONG_WRITE {
@Override
<K, V> ReferenceEntry<K, V> newEntry(
Segment<K, V> segment, K key, int hash, @Nullable ReferenceEntry<K, V> next) {
return new StrongWriteEntry<K, V>(key, hash, next);
}
@Override
<K, V> ReferenceEntry<K, V> copyEntry(
Segment<K, V> segment, ReferenceEntry<K, V> original, ReferenceEntry<K, V> newNext) {
ReferenceEntry<K, V> newEntry = super.copyEntry(segment, original, newNext);
copyWriteEntry(original, newEntry);
return newEntry;
}
},
STRONG_ACCESS_WRITE {
@Override
<K, V> ReferenceEntry<K, V> newEntry(
Segment<K, V> segment, K key, int hash, @Nullable ReferenceEntry<K, V> next) {
return new StrongAccessWriteEntry<K, V>(key, hash, next);
}
@Override
<K, V> ReferenceEntry<K, V> copyEntry(
Segment<K, V> segment, ReferenceEntry<K, V> original, ReferenceEntry<K, V> newNext) {
ReferenceEntry<K, V> newEntry = super.copyEntry(segment, original, newNext);
copyAccessEntry(original, newEntry);
copyWriteEntry(original, newEntry);
return newEntry;
}
},
WEAK {
@Override
<K, V> ReferenceEntry<K, V> newEntry(
Segment<K, V> segment, K key, int hash, @Nullable ReferenceEntry<K, V> next) {
return new WeakEntry<K, V>(segment.keyReferenceQueue, key, hash, next);
}
},
WEAK_ACCESS {
@Override
<K, V> ReferenceEntry<K, V> newEntry(
Segment<K, V> segment, K key, int hash, @Nullable ReferenceEntry<K, V> next) {
return new WeakAccessEntry<K, V>(segment.keyReferenceQueue, key, hash, next);
}
@Override
<K, V> ReferenceEntry<K, V> copyEntry(
Segment<K, V> segment, ReferenceEntry<K, V> original, ReferenceEntry<K, V> newNext) {
ReferenceEntry<K, V> newEntry = super.copyEntry(segment, original, newNext);
copyAccessEntry(original, newEntry);
return newEntry;
}
},
WEAK_WRITE {
@Override
<K, V> ReferenceEntry<K, V> newEntry(
Segment<K, V> segment, K key, int hash, @Nullable ReferenceEntry<K, V> next) {
return new WeakWriteEntry<K, V>(segment.keyReferenceQueue, key, hash, next);
}
@Override
<K, V> ReferenceEntry<K, V> copyEntry(
Segment<K, V> segment, ReferenceEntry<K, V> original, ReferenceEntry<K, V> newNext) {
ReferenceEntry<K, V> newEntry = super.copyEntry(segment, original, newNext);
copyWriteEntry(original, newEntry);
return newEntry;
}
},
WEAK_ACCESS_WRITE {
@Override
<K, V> ReferenceEntry<K, V> newEntry(
Segment<K, V> segment, K key, int hash, @Nullable ReferenceEntry<K, V> next) {
return new WeakAccessWriteEntry<K, V>(segment.keyReferenceQueue, key, hash, next);
}
@Override
<K, V> ReferenceEntry<K, V> copyEntry(
Segment<K, V> segment, ReferenceEntry<K, V> original, ReferenceEntry<K, V> newNext) {
ReferenceEntry<K, V> newEntry = super.copyEntry(segment, original, newNext);
copyAccessEntry(original, newEntry);
copyWriteEntry(original, newEntry);
return newEntry;
}
};
/**
* Masks used to compute indices in the following table.
*/
static final int ACCESS_MASK = 1;
static final int WRITE_MASK = 2;
static final int WEAK_MASK = 4;
/**
* Look-up table for factories.
*/
static final EntryFactory[] factories = {
STRONG, STRONG_ACCESS, STRONG_WRITE, STRONG_ACCESS_WRITE,
WEAK, WEAK_ACCESS, WEAK_WRITE, WEAK_ACCESS_WRITE,
};
static EntryFactory getFactory(Strength keyStrength, boolean usesAccessQueue,
boolean usesWriteQueue) {
int flags = ((keyStrength == Strength.WEAK) ? WEAK_MASK : 0)
| (usesAccessQueue ? ACCESS_MASK : 0)
| (usesWriteQueue ? WRITE_MASK : 0);
return factories[flags];
}
/**
* Creates a new entry.
*
* @param segment to create the entry for
* @param key of the entry
* @param hash of the key
* @param next entry in the same bucket
*/
abstract <K, V> ReferenceEntry<K, V> newEntry(
Segment<K, V> segment, K key, int hash, @Nullable ReferenceEntry<K, V> next);
/**
* Copies an entry, assigning it a new {@code next} entry.
*
* @param original the entry to copy
* @param newNext entry in the same bucket
*/
@GuardedBy("Segment.this")
<K, V> ReferenceEntry<K, V> copyEntry(
Segment<K, V> segment, ReferenceEntry<K, V> original, ReferenceEntry<K, V> newNext) {
return newEntry(segment, original.getKey(), original.getHash(), newNext);
}
@GuardedBy("Segment.this")
<K, V> void copyAccessEntry(ReferenceEntry<K, V> original, ReferenceEntry<K, V> newEntry) {
// TODO(fry): when we link values instead of entries this method can go
// away, as can connectAccessOrder, nullifyAccessOrder.
newEntry.setAccessTime(original.getAccessTime());
connectAccessOrder(original.getPreviousInAccessQueue(), newEntry);
connectAccessOrder(newEntry, original.getNextInAccessQueue());
nullifyAccessOrder(original);
}
@GuardedBy("Segment.this")
<K, V> void copyWriteEntry(ReferenceEntry<K, V> original, ReferenceEntry<K, V> newEntry) {
// TODO(fry): when we link values instead of entries this method can go
// away, as can connectWriteOrder, nullifyWriteOrder.
newEntry.setWriteTime(original.getWriteTime());
connectWriteOrder(original.getPreviousInWriteQueue(), newEntry);
connectWriteOrder(newEntry, original.getNextInWriteQueue());
nullifyWriteOrder(original);
}
}
/**
* A reference to a value.
*/
interface ValueReference<K, V> {
/**
* Returns the value. Does not block or throw exceptions.
*/
@Nullable
V get();
/**
* Waits for a value that may still be loading. Unlike get(), this method can block (in the case of FutureValueReference).
*
* @throws ExecutionException if the loading thread throws an exception
* @throws if the loading thread throws an error
*/
V waitForValue() throws ExecutionException;
/**
* Returns the weight of this entry. This is assumed to be static between calls to setValue.
*/
int getWeight();
/**
* Returns the entry associated with this value reference, or {@code null} if this value reference is independent of any entry.
*/
@Nullable
ReferenceEntry<K, V> getEntry();
/**
* Creates a copy of this reference for the given entry.
*
* <p>{@code value} may be null only for a loading reference.
*/
ValueReference<K, V> copyFor(
ReferenceQueue<V> queue, @Nullable V value, ReferenceEntry<K, V> entry);
/**
* Notifify pending loads that a new value was set. This is only relevant to loading value references.
*/
void notifyNewValue(@Nullable V newValue);
/**
* Returns true if a new value is currently loading, regardless of whether or not there is an existing value. It is assumed that the
* return value of this method is constant for any given ValueReference instance.
*/
boolean isLoading();
/**
* Returns true if this reference contains an active value, meaning one that is still considered present in the cache. Active values
* consist of live values, which are returned by cache lookups, and dead values, which have been evicted but awaiting removal.
* Non-active values consist strictly of loading values, though during refresh a value may be both active and loading.
*/
boolean isActive();
}
/**
* Placeholder. Indicates that the value hasn't been set yet.
*/
static final ValueReference<Object, Object> UNSET = new ValueReference<Object, Object>() {
@Override
public Object get() {
return null;
}
@Override
public int getWeight() {
return 0;
}
@Override
public ReferenceEntry<Object, Object> getEntry() {
return null;
}
@Override
public ValueReference<Object, Object> copyFor(ReferenceQueue<Object> queue,
@Nullable Object value, ReferenceEntry<Object, Object> entry) {
return this;
}
@Override
public boolean isLoading() {
return false;
}
@Override
public boolean isActive() {
return false;
}
@Override
public Object waitForValue() {
return null;
}
@Override
public void notifyNewValue(Object newValue) {}
};
/**
* Singleton placeholder that indicates a value is being loaded.
*/
@SuppressWarnings("unchecked") // impl never uses a parameter or returns any non-null value
static <K, V> ValueReference<K, V> unset() {
return (ValueReference<K, V>) UNSET;
}
/**
* An entry in a reference map.
* <p>
* Entries in the map can be in the following states:
* <p>
* Valid: - Live: valid key/value are set - Loading: loading is pending
* <p>
* Invalid: - Expired: time expired (key/value may still be set) - Collected: key/value was partially collected, but not yet cleaned up
* - Unset: marked as unset, awaiting cleanup or reuse
*/
interface ReferenceEntry<K, V> {
/**
* Returns the value reference from this entry.
*/
ValueReference<K, V> getValueReference();
/**
* Sets the value reference for this entry.
*/
void setValueReference(ValueReference<K, V> valueReference);
/**
* Returns the next entry in the chain.
*/
@Nullable
ReferenceEntry<K, V> getNext();
/**
* Returns the entry's hash.
*/
int getHash();
/**
* Returns the key for this entry.
*/
@Nullable
K getKey();
/*
* Used by entries that use access order. Access entries are maintained in a doubly-linked list.
* New entries are added at the tail of the list at write time; stale entries are expired from
* the head of the list.
*/
/**
* Returns the time that this entry was last accessed, in ns.
*/
long getAccessTime();
/**
* Sets the entry access time in ns.
*/
void setAccessTime(long time);
/**
* Returns the next entry in the access queue.
*/
ReferenceEntry<K, V> getNextInAccessQueue();
/**
* Sets the next entry in the access queue.
*/
void setNextInAccessQueue(ReferenceEntry<K, V> next);
/**
* Returns the previous entry in the access queue.
*/
ReferenceEntry<K, V> getPreviousInAccessQueue();
/**
* Sets the previous entry in the access queue.
*/
void setPreviousInAccessQueue(ReferenceEntry<K, V> previous);
/*
* Implemented by entries that use write order. Write entries are maintained in a
* doubly-linked list. New entries are added at the tail of the list at write time and stale
* entries are expired from the head of the list.
*/
/**
* Returns the time that this entry was last written, in ns.
*/
long getWriteTime();
/**
* Sets the entry write time in ns.
*/
void setWriteTime(long time);
/**
* Returns the next entry in the write queue.
*/
ReferenceEntry<K, V> getNextInWriteQueue();
/**
* Sets the next entry in the write queue.
*/
void setNextInWriteQueue(ReferenceEntry<K, V> next);
/**
* Returns the previous entry in the write queue.
*/
ReferenceEntry<K, V> getPreviousInWriteQueue();
/**
* Sets the previous entry in the write queue.
*/
void setPreviousInWriteQueue(ReferenceEntry<K, V> previous);
}
private enum NullEntry implements ReferenceEntry<Object, Object> {
INSTANCE;
@Override
public ValueReference<Object, Object> getValueReference() {
return null;
}
@Override
public void setValueReference(ValueReference<Object, Object> valueReference) {}
@Override
public ReferenceEntry<Object, Object> getNext() {
return null;
}
@Override
public int getHash() {
return 0;
}
@Override
public Object getKey() {
return null;
}
@Override
public long getAccessTime() {
return 0;
}
@Override
public void setAccessTime(long time) {}
@Override
public ReferenceEntry<Object, Object> getNextInAccessQueue() {
return this;
}
@Override
public void setNextInAccessQueue(ReferenceEntry<Object, Object> next) {}
@Override
public ReferenceEntry<Object, Object> getPreviousInAccessQueue() {
return this;
}
@Override
public void setPreviousInAccessQueue(ReferenceEntry<Object, Object> previous) {}
@Override
public long getWriteTime() {
return 0;
}
@Override
public void setWriteTime(long time) {}
@Override
public ReferenceEntry<Object, Object> getNextInWriteQueue() {
return this;
}
@Override
public void setNextInWriteQueue(ReferenceEntry<Object, Object> next) {}
@Override
public ReferenceEntry<Object, Object> getPreviousInWriteQueue() {
return this;
}
@Override
public void setPreviousInWriteQueue(ReferenceEntry<Object, Object> previous) {}
}
static abstract class AbstractReferenceEntry<K, V> implements ReferenceEntry<K, V> {
@Override
public ValueReference<K, V> getValueReference() {
throw new UnsupportedOperationException();
}
@Override
public void setValueReference(ValueReference<K, V> valueReference) {
throw new UnsupportedOperationException();
}
@Override
public ReferenceEntry<K, V> getNext() {
throw new UnsupportedOperationException();
}
@Override
public int getHash() {
throw new UnsupportedOperationException();
}
@Override
public K getKey() {
throw new UnsupportedOperationException();
}
@Override
public long getAccessTime() {
throw new UnsupportedOperationException();
}
@Override
public void setAccessTime(long time) {
throw new UnsupportedOperationException();
}
@Override
public ReferenceEntry<K, V> getNextInAccessQueue() {
throw new UnsupportedOperationException();
}
@Override
public void setNextInAccessQueue(ReferenceEntry<K, V> next) {
throw new UnsupportedOperationException();
}
@Override
public ReferenceEntry<K, V> getPreviousInAccessQueue() {
throw new UnsupportedOperationException();
}
@Override
public void setPreviousInAccessQueue(ReferenceEntry<K, V> previous) {
throw new UnsupportedOperationException();
}
@Override
public long getWriteTime() {
throw new UnsupportedOperationException();
}
@Override
public void setWriteTime(long time) {
throw new UnsupportedOperationException();
}
@Override
public ReferenceEntry<K, V> getNextInWriteQueue() {
throw new UnsupportedOperationException();
}
@Override
public void setNextInWriteQueue(ReferenceEntry<K, V> next) {
throw new UnsupportedOperationException();
}
@Override
public ReferenceEntry<K, V> getPreviousInWriteQueue() {
throw new UnsupportedOperationException();
}
@Override
public void setPreviousInWriteQueue(ReferenceEntry<K, V> previous) {
throw new UnsupportedOperationException();
}
}
@SuppressWarnings("unchecked") // impl never uses a parameter or returns any non-null value
static <K, V> ReferenceEntry<K, V> nullEntry() {
return (ReferenceEntry<K, V>) NullEntry.INSTANCE;
}
static final Queue<? extends Object> DISCARDING_QUEUE = new AbstractQueue<Object>() {
@Override
public boolean offer(Object o) {
return true;
}
@Override
public Object peek() {
return null;
}
@Override
public Object poll() {
return null;
}
@Override
public int size() {
return 0;
}
@Override
public Iterator<Object> iterator() {
return Iterators.emptyIterator();
}
};
/**
* Queue that discards all elements.
*/
@SuppressWarnings("unchecked") // impl never uses a parameter or returns any non-null value
static <E> Queue<E> discardingQueue() {
return (Queue) DISCARDING_QUEUE;
}
/*
* Note: All of this duplicate code sucks, but it saves a lot of memory. If only Java had mixins!
* To maintain this code, make a change for the strong reference type. Then, cut and paste, and
* replace "Strong" with "Soft" or "Weak" within the pasted text. The primary difference is that
* strong entries store the key reference directly while soft and weak entries delegate to their
* respective superclasses.
*/
/**
* Used for strongly-referenced keys.
*/
static class StrongEntry<K, V> extends AbstractReferenceEntry<K, V> {
final K key;
StrongEntry(K key, int hash, @Nullable ReferenceEntry<K, V> next) {
this.key = key;
this.hash = hash;
this.next = next;
}
@Override
public K getKey() {
return this.key;
}
// The code below is exactly the same for each entry type.
final int hash;
final ReferenceEntry<K, V> next;
volatile ValueReference<K, V> valueReference = unset();
@Override
public ValueReference<K, V> getValueReference() {
return valueReference;
}
@Override
public void setValueReference(ValueReference<K, V> valueReference) {
this.valueReference = valueReference;
}
@Override
public int getHash() {
return hash;
}
@Override
public ReferenceEntry<K, V> getNext() {
return next;
}
}
static final class StrongAccessEntry<K, V> extends StrongEntry<K, V> {
StrongAccessEntry(K key, int hash, @Nullable ReferenceEntry<K, V> next) {
super(key, hash, next);
}
// The code below is exactly the same for each access entry type.
volatile long accessTime = Long.MAX_VALUE;
@Override
public long getAccessTime() {
return accessTime;
}
@Override
public void setAccessTime(long time) {
this.accessTime = time;
}
@GuardedBy("Segment.this")
ReferenceEntry<K, V> nextAccess = nullEntry();
@Override
public ReferenceEntry<K, V> getNextInAccessQueue() {
return nextAccess;
}
@Override
public void setNextInAccessQueue(ReferenceEntry<K, V> next) {
this.nextAccess = next;
}
@GuardedBy("Segment.this")
ReferenceEntry<K, V> previousAccess = nullEntry();
@Override
public ReferenceEntry<K, V> getPreviousInAccessQueue() {
return previousAccess;
}
@Override
public void setPreviousInAccessQueue(ReferenceEntry<K, V> previous) {
this.previousAccess = previous;
}
}
static final class StrongWriteEntry<K, V> extends StrongEntry<K, V> {
StrongWriteEntry(K key, int hash, @Nullable ReferenceEntry<K, V> next) {
super(key, hash, next);
}
// The code below is exactly the same for each write entry type.
volatile long writeTime = Long.MAX_VALUE;
@Override
public long getWriteTime() {
return writeTime;
}
@Override
public void setWriteTime(long time) {
this.writeTime = time;
}
@GuardedBy("Segment.this")
ReferenceEntry<K, V> nextWrite = nullEntry();
@Override
public ReferenceEntry<K, V> getNextInWriteQueue() {
return nextWrite;
}
@Override
public void setNextInWriteQueue(ReferenceEntry<K, V> next) {
this.nextWrite = next;
}
@GuardedBy("Segment.this")
ReferenceEntry<K, V> previousWrite = nullEntry();
@Override
public ReferenceEntry<K, V> getPreviousInWriteQueue() {
return previousWrite;
}
@Override
public void setPreviousInWriteQueue(ReferenceEntry<K, V> previous) {
this.previousWrite = previous;
}
}
static final class StrongAccessWriteEntry<K, V> extends StrongEntry<K, V> {
StrongAccessWriteEntry(K key, int hash, @Nullable ReferenceEntry<K, V> next) {
super(key, hash, next);
}
// The code below is exactly the same for each access entry type.
volatile long accessTime = Long.MAX_VALUE;
@Override
public long getAccessTime() {
return accessTime;
}
@Override
public void setAccessTime(long time) {
this.accessTime = time;
}
@GuardedBy("Segment.this")
ReferenceEntry<K, V> nextAccess = nullEntry();
@Override
public ReferenceEntry<K, V> getNextInAccessQueue() {
return nextAccess;
}
@Override
public void setNextInAccessQueue(ReferenceEntry<K, V> next) {
this.nextAccess = next;
}
@GuardedBy("Segment.this")
ReferenceEntry<K, V> previousAccess = nullEntry();
@Override
public ReferenceEntry<K, V> getPreviousInAccessQueue() {
return previousAccess;
}
@Override
public void setPreviousInAccessQueue(ReferenceEntry<K, V> previous) {
this.previousAccess = previous;
}
// The code below is exactly the same for each write entry type.
volatile long writeTime = Long.MAX_VALUE;
@Override
public long getWriteTime() {
return writeTime;
}
@Override
public void setWriteTime(long time) {
this.writeTime = time;
}
@GuardedBy("Segment.this")
ReferenceEntry<K, V> nextWrite = nullEntry();
@Override
public ReferenceEntry<K, V> getNextInWriteQueue() {
return nextWrite;
}
@Override
public void setNextInWriteQueue(ReferenceEntry<K, V> next) {
this.nextWrite = next;
}
@GuardedBy("Segment.this")
ReferenceEntry<K, V> previousWrite = nullEntry();
@Override
public ReferenceEntry<K, V> getPreviousInWriteQueue() {
return previousWrite;
}
@Override
public void setPreviousInWriteQueue(ReferenceEntry<K, V> previous) {
this.previousWrite = previous;
}
}
/**
* Used for weakly-referenced keys.
*/
static class WeakEntry<K, V> extends WeakReference<K> implements ReferenceEntry<K, V> {
WeakEntry(ReferenceQueue<K> queue, K key, int hash, @Nullable ReferenceEntry<K, V> next) {
super(key, queue);
this.hash = hash;
this.next = next;
}
@Override
public K getKey() {
return get();
}
/*
* It'd be nice to get these for free from AbstractReferenceEntry, but we're already extending
* WeakReference<K>.
*/
// null access
@Override
public long getAccessTime() {
throw new UnsupportedOperationException();
}
@Override
public void setAccessTime(long time) {
throw new UnsupportedOperationException();
}
@Override
public ReferenceEntry<K, V> getNextInAccessQueue() {
throw new UnsupportedOperationException();
}
@Override
public void setNextInAccessQueue(ReferenceEntry<K, V> next) {
throw new UnsupportedOperationException();
}
@Override
public ReferenceEntry<K, V> getPreviousInAccessQueue() {
throw new UnsupportedOperationException();
}
@Override
public void setPreviousInAccessQueue(ReferenceEntry<K, V> previous) {
throw new UnsupportedOperationException();
}
// null write
@Override
public long getWriteTime() {
throw new UnsupportedOperationException();
}
@Override
public void setWriteTime(long time) {
throw new UnsupportedOperationException();
}
@Override
public ReferenceEntry<K, V> getNextInWriteQueue() {
throw new UnsupportedOperationException();
}
@Override
public void setNextInWriteQueue(ReferenceEntry<K, V> next) {
throw new UnsupportedOperationException();
}
@Override
public ReferenceEntry<K, V> getPreviousInWriteQueue() {
throw new UnsupportedOperationException();
}
@Override
public void setPreviousInWriteQueue(ReferenceEntry<K, V> previous) {
throw new UnsupportedOperationException();
}
// The code below is exactly the same for each entry type.
final int hash;
final ReferenceEntry<K, V> next;
volatile ValueReference<K, V> valueReference = unset();
@Override
public ValueReference<K, V> getValueReference() {
return valueReference;
}
@Override
public void setValueReference(ValueReference<K, V> valueReference) {
this.valueReference = valueReference;
}
@Override
public int getHash() {
return hash;
}
@Override
public ReferenceEntry<K, V> getNext() {
return next;
}
}
static final class WeakAccessEntry<K, V> extends WeakEntry<K, V> {
WeakAccessEntry(
ReferenceQueue<K> queue, K key, int hash, @Nullable ReferenceEntry<K, V> next) {
super(queue, key, hash, next);
}
// The code below is exactly the same for each access entry type.
volatile long accessTime = Long.MAX_VALUE;
@Override
public long getAccessTime() {
return accessTime;
}
@Override
public void setAccessTime(long time) {
this.accessTime = time;
}
@GuardedBy("Segment.this")
ReferenceEntry<K, V> nextAccess = nullEntry();
@Override
public ReferenceEntry<K, V> getNextInAccessQueue() {
return nextAccess;
}
@Override
public void setNextInAccessQueue(ReferenceEntry<K, V> next) {
this.nextAccess = next;
}
@GuardedBy("Segment.this")
ReferenceEntry<K, V> previousAccess = nullEntry();
@Override
public ReferenceEntry<K, V> getPreviousInAccessQueue() {
return previousAccess;
}
@Override
public void setPreviousInAccessQueue(ReferenceEntry<K, V> previous) {
this.previousAccess = previous;
}
}
static final class WeakWriteEntry<K, V> extends WeakEntry<K, V> {
WeakWriteEntry(
ReferenceQueue<K> queue, K key, int hash, @Nullable ReferenceEntry<K, V> next) {
super(queue, key, hash, next);
}
// The code below is exactly the same for each write entry type.
volatile long writeTime = Long.MAX_VALUE;
@Override
public long getWriteTime() {
return writeTime;
}
@Override
public void setWriteTime(long time) {
this.writeTime = time;
}
@GuardedBy("Segment.this")
ReferenceEntry<K, V> nextWrite = nullEntry();
@Override
public ReferenceEntry<K, V> getNextInWriteQueue() {
return nextWrite;
}
@Override
public void setNextInWriteQueue(ReferenceEntry<K, V> next) {
this.nextWrite = next;
}
@GuardedBy("Segment.this")
ReferenceEntry<K, V> previousWrite = nullEntry();
@Override
public ReferenceEntry<K, V> getPreviousInWriteQueue() {
return previousWrite;
}
@Override
public void setPreviousInWriteQueue(ReferenceEntry<K, V> previous) {
this.previousWrite = previous;
}
}
static final class WeakAccessWriteEntry<K, V> extends WeakEntry<K, V> {
WeakAccessWriteEntry(
ReferenceQueue<K> queue, K key, int hash, @Nullable ReferenceEntry<K, V> next) {
super(queue, key, hash, next);
}
// The code below is exactly the same for each access entry type.
volatile long accessTime = Long.MAX_VALUE;
@Override
public long getAccessTime() {
return accessTime;
}
@Override
public void setAccessTime(long time) {
this.accessTime = time;
}
@GuardedBy("Segment.this")
ReferenceEntry<K, V> nextAccess = nullEntry();
@Override
public ReferenceEntry<K, V> getNextInAccessQueue() {
return nextAccess;
}
@Override
public void setNextInAccessQueue(ReferenceEntry<K, V> next) {
this.nextAccess = next;
}
@GuardedBy("Segment.this")
ReferenceEntry<K, V> previousAccess = nullEntry();
@Override
public ReferenceEntry<K, V> getPreviousInAccessQueue() {
return previousAccess;
}
@Override
public void setPreviousInAccessQueue(ReferenceEntry<K, V> previous) {
this.previousAccess = previous;
}
// The code below is exactly the same for each write entry type.
volatile long writeTime = Long.MAX_VALUE;
@Override
public long getWriteTime() {
return writeTime;
}
@Override
public void setWriteTime(long time) {
this.writeTime = time;
}
@GuardedBy("Segment.this")
ReferenceEntry<K, V> nextWrite = nullEntry();
@Override
public ReferenceEntry<K, V> getNextInWriteQueue() {
return nextWrite;
}
@Override
public void setNextInWriteQueue(ReferenceEntry<K, V> next) {
this.nextWrite = next;
}
@GuardedBy("Segment.this")
ReferenceEntry<K, V> previousWrite = nullEntry();
@Override
public ReferenceEntry<K, V> getPreviousInWriteQueue() {
return previousWrite;
}
@Override
public void setPreviousInWriteQueue(ReferenceEntry<K, V> previous) {
this.previousWrite = previous;
}
}
/**
* References a weak value.
*/
static class WeakValueReference<K, V>
extends WeakReference<V> implements ValueReference<K, V> {
final ReferenceEntry<K, V> entry;
WeakValueReference(ReferenceQueue<V> queue, V referent, ReferenceEntry<K, V> entry) {
super(referent, queue);
this.entry = entry;
}
@Override
public int getWeight() {
return 1;
}
@Override
public ReferenceEntry<K, V> getEntry() {
return entry;
}
@Override
public void notifyNewValue(V newValue) {}
@Override
public ValueReference<K, V> copyFor(
ReferenceQueue<V> queue, V value, ReferenceEntry<K, V> entry) {
return new WeakValueReference<K, V>(queue, value, entry);
}
@Override
public boolean isLoading() {
return false;
}
@Override
public boolean isActive() {
return true;
}
@Override
public V waitForValue() {
return get();
}
}
/**
* References a soft value.
*/
static class SoftValueReference<K, V>
extends SoftReference<V> implements ValueReference<K, V> {
final ReferenceEntry<K, V> entry;
SoftValueReference(ReferenceQueue<V> queue, V referent, ReferenceEntry<K, V> entry) {
super(referent, queue);
this.entry = entry;
}
@Override
public int getWeight() {
return 1;
}
@Override
public ReferenceEntry<K, V> getEntry() {
return entry;
}
@Override
public void notifyNewValue(V newValue) {}
@Override
public ValueReference<K, V> copyFor(
ReferenceQueue<V> queue, V value, ReferenceEntry<K, V> entry) {
return new SoftValueReference<K, V>(queue, value, entry);
}
@Override
public boolean isLoading() {
return false;
}
@Override
public boolean isActive() {
return true;
}
@Override
public V waitForValue() {
return get();
}
}
/**
* References a strong value.
*/
static class StrongValueReference<K, V> implements ValueReference<K, V> {
final V referent;
StrongValueReference(V referent) {
this.referent = referent;
}
@Override
public V get() {
return referent;
}
@Override
public int getWeight() {
return 1;
}
@Override
public ReferenceEntry<K, V> getEntry() {
return null;
}
@Override
public ValueReference<K, V> copyFor(
ReferenceQueue<V> queue, V value, ReferenceEntry<K, V> entry) {
return this;
}
@Override
public boolean isLoading() {
return false;
}
@Override
public boolean isActive() {
return true;
}
@Override
public V waitForValue() {
return get();
}
@Override
public void notifyNewValue(V newValue) {}
}
/**
* References a weak value.
*/
static final class WeightedWeakValueReference<K, V> extends WeakValueReference<K, V> {
final int weight;
WeightedWeakValueReference(ReferenceQueue<V> queue, V referent, ReferenceEntry<K, V> entry,
int weight) {
super(queue, referent, entry);
this.weight = weight;
}
@Override
public int getWeight() {
return weight;
}
@Override
public ValueReference<K, V> copyFor(
ReferenceQueue<V> queue, V value, ReferenceEntry<K, V> entry) {
return new WeightedWeakValueReference<K, V>(queue, value, entry, weight);
}
}
/**
* References a soft value.
*/
static final class WeightedSoftValueReference<K, V> extends SoftValueReference<K, V> {
final int weight;
WeightedSoftValueReference(ReferenceQueue<V> queue, V referent, ReferenceEntry<K, V> entry,
int weight) {
super(queue, referent, entry);
this.weight = weight;
}
@Override
public int getWeight() {
return weight;
}
@Override
public ValueReference<K, V> copyFor(
ReferenceQueue<V> queue, V value, ReferenceEntry<K, V> entry) {
return new WeightedSoftValueReference<K, V>(queue, value, entry, weight);
}
}
/**
* References a strong value.
*/
static final class WeightedStrongValueReference<K, V> extends StrongValueReference<K, V> {
final int weight;
WeightedStrongValueReference(V referent, int weight) {
super(referent);
this.weight = weight;
}
@Override
public int getWeight() {
return weight;
}
}
/**
* Applies a supplemental hash function to a given hash code, which defends against poor quality hash functions. This is critical when
* the concurrent hash map uses power-of-two length hash tables, that otherwise encounter collisions for hash codes that do not differ
* in lower or upper bits.
*
* @param h hash code
*/
static int rehash(int h) {
// Spread bits to regularize both segment and index locations,
// using variant of single-word Wang/Jenkins hash.
// TODO(kevinb): use Hashing/move this to Hashing?
h += (h << 15) ^ 0xffffcd7d;
h ^= (h >>> 10);
h += (h << 3);
h ^= (h >>> 6);
h += (h << 2) + (h << 14);
return h ^ (h >>> 16);
}
/**
* This method is a convenience for testing. Code should call {@link Segment#newEntry} directly.
*/
@GuardedBy("Segment.this")
@VisibleForTesting
ReferenceEntry<K, V> newEntry(K key, int hash, @Nullable ReferenceEntry<K, V> next) {
return segmentFor(hash).newEntry(key, hash, next);
}
/**
* This method is a convenience for testing. Code should call {@link Segment#copyEntry} directly.
*/
@GuardedBy("Segment.this")
@VisibleForTesting
ReferenceEntry<K, V> copyEntry(ReferenceEntry<K, V> original, ReferenceEntry<K, V> newNext) {
int hash = original.getHash();
return segmentFor(hash).copyEntry(original, newNext);
}
/**
* This method is a convenience for testing. Code should call {@link Segment#setValue} instead.
*/
@GuardedBy("Segment.this")
@VisibleForTesting
ValueReference<K, V> newValueReference(ReferenceEntry<K, V> entry, V value, int weight) {
int hash = entry.getHash();
return valueStrength.referenceValue(segmentFor(hash), entry, checkNotNull(value), weight);
}
int hash(@Nullable Object key) {
int h = keyEquivalence.hash(key);
return rehash(h);
}
void reclaimValue(ValueReference<K, V> valueReference) {
ReferenceEntry<K, V> entry = valueReference.getEntry();
int hash = entry.getHash();
segmentFor(hash).reclaimValue(entry.getKey(), hash, valueReference);
}
void reclaimKey(ReferenceEntry<K, V> entry) {
int hash = entry.getHash();// 这里是存放到ReferenceEntry中的key的hash值
segmentFor(hash).reclaimKey(entry, hash);
}
/**
* This method is a convenience for testing. Code should call {@link Segment#getLiveValue} instead.
*/
@VisibleForTesting
boolean isLive(ReferenceEntry<K, V> entry, long now) {
return segmentFor(entry.getHash()).getLiveValue(entry, now) != null;
}
/**
* Returns the segment that should be used for a key with the given hash.
*
* @param hash the hash code for the key
* @return the segment
*/
Segment<K, V> segmentFor(int hash) {
// TODO(fry): Lazily create segments?
return segments[(hash >>> segmentShift) & segmentMask];
}
Segment<K, V> createSegment(
int initialCapacity, long maxSegmentWeight, StatsCounter statsCounter) {
return new Segment<K, V>(this, initialCapacity, maxSegmentWeight, statsCounter);
}
/**
* Gets the value from an entry. Returns null if the entry is invalid, partially-collected, loading, or expired. Unlike {@link
* Segment#getLiveValue} this method does not attempt to cleanup stale entries. As such it should only be called outside of a segment
* context, such as during iteration.
*/
@Nullable
V getLiveValue(ReferenceEntry<K, V> entry, long now) {
if (entry.getKey() == null) {
return null;
}
V value = entry.getValueReference().get();
if (value == null) {
return null;
}
if (isExpired(entry, now)) {
return null;
}
return value;
}
// expiration
/**
* Returns true if the entry has expired.
*/
boolean isExpired(ReferenceEntry<K, V> entry, long now) {
checkNotNull(entry);
if (expiresAfterAccess()
&& (now - entry.getAccessTime() >= expireAfterAccessNanos)) {
return true;
}
if (expiresAfterWrite()
&& (now - entry.getWriteTime() >= expireAfterWriteNanos)) {
return true;
}
return false;
}
// queues
@GuardedBy("Segment.this")
static <K, V> void connectAccessOrder(ReferenceEntry<K, V> previous, ReferenceEntry<K, V> next) {
previous.setNextInAccessQueue(next);
next.setPreviousInAccessQueue(previous);
}
@GuardedBy("Segment.this")
static <K, V> void nullifyAccessOrder(ReferenceEntry<K, V> nulled) {
ReferenceEntry<K, V> nullEntry = nullEntry();
nulled.setNextInAccessQueue(nullEntry);
nulled.setPreviousInAccessQueue(nullEntry);
}
@GuardedBy("Segment.this")
static <K, V> void connectWriteOrder(ReferenceEntry<K, V> previous, ReferenceEntry<K, V> next) {
previous.setNextInWriteQueue(next);
next.setPreviousInWriteQueue(previous);
}
@GuardedBy("Segment.this")
static <K, V> void nullifyWriteOrder(ReferenceEntry<K, V> nulled) {
ReferenceEntry<K, V> nullEntry = nullEntry();
nulled.setNextInWriteQueue(nullEntry);
nulled.setPreviousInWriteQueue(nullEntry);
}
/**
* Notifies listeners that an entry has been automatically removed due to expiration, eviction, or eligibility for garbage collection.
* This should be called every time expireEntries or evictEntry is called (once the lock is released).
*/
void processPendingNotifications() {
RemovalNotification<K, V> notification;
while ((notification = removalNotificationQueue.poll()) != null) {
try {
removalListener.onRemoval(notification);
} catch (Throwable e) {
logger.log(Level.WARNING, "Exception thrown by removal listener", e);
}
}
}
@SuppressWarnings("unchecked")
final Segment<K, V>[] newSegmentArray(int ssize) {
return new Segment[ssize];
}
// Inner Classes
/**
* Segments are specialized versions of hash tables. This subclass inherits from ReentrantLock opportunistically, just to simplify some
* locking and avoid separate construction.
*/
@SuppressWarnings("serial") // This class is never serialized.
// 这里为啥是集成ReentrantLock,而不是像我们平常用的那样,在Segement中:Lock lock= new ReentrantLock(),然后在需要加锁/释放锁的时候使用lock.lock()/lock.unlock(),区别是啥?
// jdk中的实现很多都是采用了这种集成的方式,而不是组合方式,有啥区别?
/**
* 1.首先在效果上是没有任何区别的,继承的方式不需要显示的去创建ReentrantLock对象,而组合需要。但使用方式都一样,需要在finally块中释放锁。
* 2.这种继承的方式,是不是有点像synchronize锁的方式了:synchronize的锁标志是放在对象头中的;集成方式是放在父类AQS的state字段中的,所以继承ReentrantLock,使用起来有没有一点像synchronize(this){
* //业务逻辑的方式}
*/
static class Segment<K, V> extends ReentrantLock {
/*
* TODO(fry): Consider copying variables (like evictsBySize) from outer class into this class.
* It will require more memory but will reduce indirection.
*/
/*
* Segments maintain a table of entry lists that are ALWAYS kept in a consistent state, so can
* be read without locking. Next fields of nodes are immutable (final). All list additions are
* performed at the front of each bin. This makes it easy to check changes, and also fast to
* traverse. When nodes would otherwise be changed, new nodes are created to replace them. This
* works well for hash tables since the bin lists tend to be short. (The average length is less
* than two.)
*
* Read operations can thus proceed without locking, but rely on selected uses of volatiles to
* ensure that completed write operations performed by other threads are noticed. For most
* purposes, the "count" field, tracking the number of elements, serves as that volatile
* variable ensuring visibility. This is convenient because this field needs to be read in many
* read operations anyway:
*
* - All (unsynchronized) read operations must first read the "count" field, and should not
* look at table entries if it is 0.
*
* - All (synchronized) write operations should write to the "count" field after structurally
* changing any bin. The operations must not take any action that could even momentarily
* cause a concurrent read operation to see inconsistent data. This is made easier by the
* nature of the read operations in Map. For example, no operation can reveal that the table
* has grown but the threshold has not yet been updated, so there are no atomicity requirements
* for this with respect to reads.
*
* As a guide, all critical volatile reads and writes to the count field are marked in code
* comments.
*/
final LocalCache<K, V> map;
/**
* The number of live elements in this segment's region.
*/
volatile int count;
/**
* The weight of the live elements in this segment's region.
*/
@GuardedBy("Segment.this")
int totalWeight;
/**
* Number of updates that alter the size of the table. This is used during bulk-read methods to make sure they see a consistent
* snapshot: If modCounts change during a traversal of segments loading size or checking containsValue, then we might have an
* inconsistent view of state so (usually) must retry.
*/
int modCount;
/**
* The table is expanded when its size exceeds this threshold. (The value of this field is always {@code (int) (capacity * 0.75)}.)
*/
int threshold;
/**
* The per-segment table.
*/
volatile AtomicReferenceArray<ReferenceEntry<K, V>> table;
/**
* The maximum weight of this segment. UNSET_INT if there is no maximum.
*/
final long maxSegmentWeight;
/**
* The key reference queue contains entries whose keys have been garbage collected, and which need to be cleaned up internally.
*/
final ReferenceQueue<K> keyReferenceQueue;
/**
* The value reference queue contains value references whose values have been garbage collected, and which need to be cleaned up
* internally.
*/
final ReferenceQueue<V> valueReferenceQueue;
/**
* The recency queue is used to record which entries were accessed for updating the access list's ordering. It is drained as a batch
* operation when either the DRAIN_THRESHOLD is crossed or a write occurs on the segment.
*/
final Queue<ReferenceEntry<K, V>> recencyQueue;
/**
* A counter of the number of reads since the last write, used to drain queues on a small fraction of read operations.
*/
final AtomicInteger readCount = new AtomicInteger();
/**
* A queue of elements currently in the map, ordered by write time. Elements are added to the tail of the queue on write.
*/
@GuardedBy("Segment.this")
final Queue<ReferenceEntry<K, V>> writeQueue;
/**
* A queue of elements currently in the map, ordered by access time. Elements are added to the tail of the queue on access (note
* that writes count as accesses).
*/
@GuardedBy("Segment.this")
final Queue<ReferenceEntry<K, V>> accessQueue;
/**
* Accumulates cache statistics.
*/
final StatsCounter statsCounter;
Segment(LocalCache<K, V> map, int initialCapacity, long maxSegmentWeight,
StatsCounter statsCounter) {
this.map = map;
this.maxSegmentWeight = maxSegmentWeight;
this.statsCounter = checkNotNull(statsCounter);
initTable(newEntryArray(initialCapacity));
keyReferenceQueue = map.usesKeyReferences()
? new ReferenceQueue<K>() : null;
valueReferenceQueue = map.usesValueReferences()
? new ReferenceQueue<V>() : null;
recencyQueue = map.usesAccessQueue()
? new ConcurrentLinkedQueue<ReferenceEntry<K, V>>()
: LocalCache.<ReferenceEntry<K, V>>discardingQueue();
writeQueue = map.usesWriteQueue()
? new WriteQueue<K, V>()
: LocalCache.<ReferenceEntry<K, V>>discardingQueue();
accessQueue = map.usesAccessQueue()
? new AccessQueue<K, V>()
: LocalCache.<ReferenceEntry<K, V>>discardingQueue();
}
AtomicReferenceArray<ReferenceEntry<K, V>> newEntryArray(int size) {
return new AtomicReferenceArray<ReferenceEntry<K, V>>(size);
}
void initTable(AtomicReferenceArray<ReferenceEntry<K, V>> newTable) {
this.threshold = newTable.length() * 3 / 4; // 0.75
if (!map.customWeigher() && this.threshold == maxSegmentWeight) {
// prevent spurious expansion before eviction
this.threshold++;
}
this.table = newTable;
}
@GuardedBy("Segment.this")
ReferenceEntry<K, V> newEntry(K key, int hash, @Nullable ReferenceEntry<K, V> next) {
return map.entryFactory.newEntry(this, checkNotNull(key), hash, next);
}
/**
* Copies {@code original} into a new entry chained to {@code newNext}. Returns the new entry, or {@code null} if {@code original}
* was already garbage collected.
*/
@GuardedBy("Segment.this")
ReferenceEntry<K, V> copyEntry(ReferenceEntry<K, V> original, ReferenceEntry<K, V> newNext) {
if (original.getKey() == null) {
// key collected
return null;
}
ValueReference<K, V> valueReference = original.getValueReference();
V value = valueReference.get();
if ((value == null) && valueReference.isActive()) {
// value collected
return null;
}
ReferenceEntry<K, V> newEntry = map.entryFactory.copyEntry(this, original, newNext);
newEntry.setValueReference(valueReference.copyFor(this.valueReferenceQueue, value, newEntry));
return newEntry;
}
/**
* Sets a new value of an entry. Adds newly created entries at the end of the access queue.
*/
@GuardedBy("Segment.this")
void setValue(ReferenceEntry<K, V> entry, K key, V value, long now) {
ValueReference<K, V> previous = entry.getValueReference();
int weight = map.weigher.weigh(key, value);
checkState(weight >= 0, "Weights must be non-negative");
ValueReference<K, V> valueReference =
map.valueStrength.referenceValue(this, entry, value, weight);
entry.setValueReference(valueReference);
recordWrite(entry, weight, now);
previous.notifyNewValue(value);
}
// loading
V get(K key, int hash, CacheLoader<? super K, V> loader) throws ExecutionException {
checkNotNull(key);
checkNotNull(loader);
try {
if (count != 0) { // read-volatile
// don't call getLiveEntry, which would ignore loading values
ReferenceEntry<K, V> e = getEntry(key, hash);
if (e != null) {
long now = map.ticker.read();
V value = getLiveValue(e, now);
if (value != null) {
recordRead(e, now);
statsCounter.recordHits(1);
// scheduleRefresh()这个地方首先,如果需要reload()就返回reload的值;否则返回入参value
//这个方法的作用就是:如果设置了refreshAfterWrite(3, TimeUnit.SECONDS),那么这里就会去检查,上次写入时间举例现在是否超过了3s
// 如果超过了,那就去调用CacheLoader去重新加载更新一遍数据。注意:虽然这里些的是scheduleRefresh(),但是guava27版本的实现中其实都还是同步的
// 并没有一部实现。
return scheduleRefresh(e, key, hash, value, now, loader);
}
ValueReference<K, V> valueReference = e.getValueReference();
if (valueReference.isLoading()) {
return waitForLoadingValue(e, key, valueReference);
}
}
}
// 缓存中不存在的时候,调用CacheLoader去重新加载进缓存
return lockedGetOrLoad(key, hash, loader);
} catch (ExecutionException ee) {
Throwable cause = ee.getCause();
if (cause instanceof Error) {
throw new ExecutionError((Error) cause);
} else if (cause instanceof RuntimeException) {
throw new UncheckedExecutionException(cause);
}
throw ee;
} finally {
postReadCleanup();
}
}
V lockedGetOrLoad(K key, int hash, CacheLoader<? super K, V> loader)
throws ExecutionException {
ReferenceEntry<K, V> e;
ValueReference<K, V> valueReference = null;
LoadingValueReference<K, V> loadingValueReference = null;
boolean createNewEntry = true;
lock();// 加锁,即要获得Segement上的锁。
try {
// re-read ticker once inside the lock
long now = map.ticker.read();
preWriteCleanup(now);
int newCount = this.count - 1;
AtomicReferenceArray<ReferenceEntry<K, V>> table = this.table;
int index = hash & (table.length() - 1);
ReferenceEntry<K, V> first = table.get(index);
for (e = first; e != null; e = e.getNext()) {
K entryKey = e.getKey();
if (e.getHash() == hash && entryKey != null && map.keyEquivalence.equivalent(key, entryKey)) {
valueReference = e.getValueReference();
if (valueReference.isLoading()) {
createNewEntry = false;
} else {
V value = valueReference.get();
if (value == null) {
enqueueNotification(entryKey, hash, valueReference, RemovalCause.COLLECTED);
} else if (map.isExpired(e, now)) {
// This is a duplicate check, as preWriteCleanup already purged expired
// entries, but let's accomodate an incorrect expiration queue.
enqueueNotification(entryKey, hash, valueReference, RemovalCause.EXPIRED);
} else {
recordLockedRead(e, now);
statsCounter.recordHits(1);
// we were concurrent with loading; don't consider refresh
return value;
}
// immediately reuse invalid entries
writeQueue.remove(e);
accessQueue.remove(e);
this.count = newCount; // write-volatile
}
break;
}
}
if (createNewEntry) {
loadingValueReference = new LoadingValueReference<K, V>();
if (e == null) {
e = newEntry(key, hash, first);
e.setValueReference(loadingValueReference);
table.set(index, e);
} else {
e.setValueReference(loadingValueReference);
}
}
} finally {
unlock();
postWriteCleanup();
}
if (createNewEntry) {
try {
// Synchronizes on the entry to allow failing fast when a recursive load is
// detected. This may be circumvented when an entry is copied, but will fail fast most
// of the time.
synchronized (e) {
return loadSync(key, hash, loadingValueReference, loader);
}
} finally {
statsCounter.recordMisses(1);
}
} else {
// The entry already exists. Wait for loading.
return waitForLoadingValue(e, key, valueReference);
}
}
V waitForLoadingValue(ReferenceEntry<K, V> e, K key, ValueReference<K, V> valueReference)
throws ExecutionException {
if (!valueReference.isLoading()) {
throw new AssertionError();
}
checkState(!Thread.holdsLock(e), "Recursive load");
// don't consider expiration as we're concurrent with loading
try {
V value = valueReference.waitForValue();
if (value == null) {
throw new InvalidCacheLoadException("CacheLoader returned null for key " + key + ".");
}
// re-read ticker now that loading has completed
long now = map.ticker.read();
recordRead(e, now);
return value;
} finally {
statsCounter.recordMisses(1);
}
}
// at most one of loadSync/loadAsync may be called for any given LoadingValueReference
V loadSync(K key, int hash, LoadingValueReference<K, V> loadingValueReference,
CacheLoader<? super K, V> loader) throws ExecutionException {
ListenableFuture<V> loadingFuture = loadingValueReference.loadFuture(key, loader);
return getAndRecordStats(key, hash, loadingValueReference, loadingFuture);
}
ListenableFuture<V> loadAsync(final K key, final int hash, final LoadingValueReference<K, V> loadingValueReference, CacheLoader<? super K, V> loader) {
// 实际去调用loader重新加载数据的。
final ListenableFuture<V> loadingFuture = loadingValueReference.loadFuture(key, loader);
loadingFuture.addListener(
new Runnable() {
@Override
public void run() {
try {
V newValue = getAndRecordStats(key, hash, loadingValueReference, loadingFuture);
} catch (Throwable t) {
logger.log(Level.WARNING, "Exception thrown during refresh", t);
loadingValueReference.setException(t);
}
}
}, sameThreadExecutor);
return loadingFuture;
}
/**
* Waits uninterruptibly for {@code newValue} to be loaded, and then records loading stats.
*/
V getAndRecordStats(K key, int hash, LoadingValueReference<K, V> loadingValueReference,
ListenableFuture<V> newValue) throws ExecutionException {
V value = null;
try {
value = getUninterruptibly(newValue);
if (value == null) {
throw new InvalidCacheLoadException("CacheLoader returned null for key " + key + ".");
}
statsCounter.recordLoadSuccess(loadingValueReference.elapsedNanos());
storeLoadedValue(key, hash, loadingValueReference, value);
return value;
} finally {
if (value == null) {
statsCounter.recordLoadException(loadingValueReference.elapsedNanos());
removeLoadingValue(key, hash, loadingValueReference);
}
}
}
V scheduleRefresh(ReferenceEntry<K, V> entry, K key, int hash, V oldValue, long now, CacheLoader<? super K, V> loader) {
// 设置了refreshAfterWrite() 并且上次写入时间离当前时间大于了指定时间 并且value没有处于loading中
// (除了LoadingValueReference返回true外,其他都返回false,因为Loading过程中,会用LoadingValueReference来封装一个ValueReference)
if (map.refreshes() && (now - entry.getWriteTime() > map.refreshNanos) && !entry.getValueReference().isLoading()) {
V newValue = refresh(key, hash, loader, true);
if (newValue != null) {
return newValue;
}
}
return oldValue;
}
/**
* Refreshes the value associated with {@code key}, unless another thread is already doing so. Returns the newly refreshed value
* associated with {@code key} if it was refreshed inline, or {@code null} if another thread is performing the refresh or if an
* error occurs during refresh.
*/
@Nullable
V refresh(K key, int hash, CacheLoader<? super K, V> loader, boolean checkTime) {
// 根据key找到要重新加载的ReferenceEntry,从而就知道了这个key对应的value引用:ValueReferfence,只是这里用LoadingValueReference封装了一下。
final LoadingValueReference<K, V> loadingValueReference = insertLoadingValueReference(key, hash, checkTime);
if (loadingValueReference == null) {
return null;
}
// 开始重新加载对应的key,这里虽然写的是异步,但默认实现是同步的。ps:异步线程和当前线程一样,那不就是同步么
ListenableFuture<V> result = loadAsync(key, hash, loadingValueReference, loader);
// 即使实现了异步,这里要注意,如果到这里异步reload()还没执行完,这里相当于就把reload()的结果给丢掉了,返回null。在调用放看来就是缓存中没有。
if (result.isDone()) {
try {
return Uninterruptibles.getUninterruptibly(result);
} catch (Throwable t) {
// don't let refresh exceptions propagate; error was already logged
}
}
return null;
}
/**
* Returns a newly inserted {@code LoadingValueReference}, or null if the live value reference is already loading.
*/
@Nullable
LoadingValueReference<K, V> insertLoadingValueReference(final K key, final int hash,
boolean checkTime) {
ReferenceEntry<K, V> e = null;
lock();
try {
long now = map.ticker.read();
preWriteCleanup(now);
AtomicReferenceArray<ReferenceEntry<K, V>> table = this.table;
int index = hash & (table.length() - 1);
ReferenceEntry<K, V> first = table.get(index);
// Look for an existing entry.
for (e = first; e != null; e = e.getNext()) {
K entryKey = e.getKey();
if (e.getHash() == hash && entryKey != null
&& map.keyEquivalence.equivalent(key, entryKey)) {
// We found an existing entry.
ValueReference<K, V> valueReference = e.getValueReference();
if (valueReference.isLoading()
|| (checkTime && (now - e.getWriteTime() < map.refreshNanos))) {
// refresh is a no-op if loading is pending
// if checkTime, we want to check *after* acquiring the lock if refresh still needs
// to be scheduled
return null;
}
// continue returning old value while loading
++modCount;
LoadingValueReference<K, V> loadingValueReference = new LoadingValueReference<K, V>(valueReference);
e.setValueReference(loadingValueReference);
return loadingValueReference;
}
}
++modCount;
LoadingValueReference<K, V> loadingValueReference = new LoadingValueReference<K, V>();
e = newEntry(key, hash, first);
e.setValueReference(loadingValueReference);
table.set(index, e);
return loadingValueReference;
} finally {
unlock();
postWriteCleanup();
}
}
// reference queues, for garbage collection cleanup
/**
* Cleanup collected entries when the lock is available.
*/
void tryDrainReferenceQueues() {
if (tryLock()) {
try {
drainReferenceQueues();
} finally {
unlock();
}
}
}
/**
* Drain the key and value reference queues, cleaning up internal entries containing garbage collected keys or values.
*/
@GuardedBy("Segment.this")
void drainReferenceQueues() {
// 如果key不是强引用,则回收那些key实际内容被gc掉了的缓存项目
if (map.usesKeyReferences()) {//keyStrength != Strength.STRONG;
drainKeyReferenceQueue();
}
// 如果value不是强引用,则回收那些value实际内容被gc掉了的缓存项目
if (map.usesValueReferences()) {//valueStrength != Strength.STRONG;
drainValueReferenceQueue();
}
}
@GuardedBy("Segment.this")
void drainKeyReferenceQueue() {
Reference<? extends K> ref;
int i = 0;
// 如果keyStrength!=Strong,即key的引用你是WeakReference或者SoftReference,在gc的时候,可能会把引用中对应的值给回收掉,
// 只剩下WeakReference对象本身。在WeakReference实现的时候,会传入一个ReferenceQueue,gc的时候,jvm会将被回收了实际值的WeakReference放到这个队列中
// 以便通知用户。在Segement的实现中,保留了传个WeakReference的这个ReferenceQueue,这个地方就是检查这个Queue,如果Queue不为空,说明被回收掉了
// 那就将对应的缓存ReferenceEntry从缓存中删除。
while ((ref = keyReferenceQueue.poll()) != null) {
@SuppressWarnings("unchecked")
ReferenceEntry<K, V> entry = (ReferenceEntry<K, V>) ref;
// 这里就是找到entry所在的链表,然后将entry从链表中删除。
map.reclaimKey(entry);
if (++i == DRAIN_MAX) {
break;
}
}
}
@GuardedBy("Segment.this")
void drainValueReferenceQueue() {
Reference<? extends V> ref;
int i = 0;
while ((ref = valueReferenceQueue.poll()) != null) {
@SuppressWarnings("unchecked")
ValueReference<K, V> valueReference = (ValueReference<K, V>) ref;
map.reclaimValue(valueReference);
if (++i == DRAIN_MAX) {
break;
}
}
}
/**
* Clears all entries from the key and value reference queues.
*/
void clearReferenceQueues() {
if (map.usesKeyReferences()) {
clearKeyReferenceQueue();
}
if (map.usesValueReferences()) {
clearValueReferenceQueue();
}
}
void clearKeyReferenceQueue() {
while (keyReferenceQueue.poll() != null) {}
}
void clearValueReferenceQueue() {
while (valueReferenceQueue.poll() != null) {}
}
// recency queue, shared by expiration and eviction
/**
* Records the relative order in which this read was performed by adding {@code entry} to the recency queue. At write-time, or when
* the queue is full past the threshold, the queue will be drained and the entries therein processed.
*
* <p>Note: locked reads should use {@link #recordLockedRead}.
*/
void recordRead(ReferenceEntry<K, V> entry, long now) {
if (map.recordsAccess()) {
entry.setAccessTime(now);
}
recencyQueue.add(entry);
}
/**
* Updates the eviction metadata that {@code entry} was just read. This currently amounts to adding {@code entry} to relevant
* eviction lists.
*
* <p>Note: this method should only be called under lock, as it directly manipulates the
* eviction queues. Unlocked reads should use {@link #recordRead}.
*/
@GuardedBy("Segment.this")
void recordLockedRead(ReferenceEntry<K, V> entry, long now) {
if (map.recordsAccess()) {
entry.setAccessTime(now);
}
accessQueue.add(entry);
}
/**
* Updates eviction metadata that {@code entry} was just written. This currently amounts to adding {@code entry} to relevant
* eviction lists.
*/
@GuardedBy("Segment.this")
void recordWrite(ReferenceEntry<K, V> entry, int weight, long now) {
// we are already under lock, so drain the recency queue immediately
drainRecencyQueue();
totalWeight += weight;
if (map.recordsAccess()) {
entry.setAccessTime(now);
}
if (map.recordsWrite()) {
entry.setWriteTime(now);
}
// accessQueue是用来实现LRU的,每次put()/get()都将对应的ReferenceEntry放到了accessQueeu的队尾,
// 然后在淘汰的时候,如果缓存个数大于规定容量,就从accessQueue中拿出来一个,从缓存中删除
accessQueue.add(entry);
writeQueue.add(entry);
}
/**
* Drains the recency queue, updating eviction metadata that the entries therein were read in the specified relative order. This
* currently amounts to adding them to relevant eviction lists (accounting for the fact that they could have been removed from the
* map since being added to the recency queue).
*/
@GuardedBy("Segment.this")
void drainRecencyQueue() {
ReferenceEntry<K, V> e;
// recencyQueue 啥时候往里放?
while ((e = recencyQueue.poll()) != null) {
// An entry may be in the recency queue despite it being removed from
// the map . This can occur when the entry was concurrently read while a
// writer is removing it from the segment or after a clear has removed
// all of the segment's entries.
/**
* guava cache实现LRU是依靠accessQueue,相当于每次访问都将访问的Entry放到这个队列的尾部,这样在put()的时候就会判断,如果缓存中元素超过了最大容量
* ,就会从accessQueue队列中直接出队元素,然后从缓存中删除这个元素,以实现LRU算法。
* 但是有个问题:accessQueue是线程不安全的,所以将元素移动到队头需要获取Segment锁,然后才能移动元素到队尾。那如果每次get()都要去获得一次锁,如果有竞争,就会阻塞查询。
* 所以,guava就有了recencyQueue,它是一个jdk中线程安全的Queue(ConcurrentLinkedQueue),每次get()的时候,都将查询到的Entry往这个队列中放,
* 然后在查询的最后tryLock(),如果没有获得锁,那么就会调用这个方法,然后将recencyQueue清空,然后将recencyQueue的元素都放到accessQueue的队尾。
*/
if (accessQueue.contains(e)) {// 这里这么判断一下的原因,就是有可能recencyQueue中的元素已经删除了,因为元素删除/过期等都不会去处理recencyQueue。
// 这里accessQueue是LocalCache中自己实现的,add()方法:如果e已经在队列中存在,就是把对应的e移动到队尾;如果不存在就加到队尾
accessQueue.add(e);
}
}
}
// expiration
/**
* Cleanup expired entries when the lock is available.
*/
void tryExpireEntries(long now) {
if (tryLock()) {
try {
expireEntries(now);
} finally {
unlock();
// don't call postWriteCleanup as we're in a read
}
}
}
@GuardedBy("Segment.this")
void expireEntries(long now) {
// recencyQueue暂下的一批读取过的ReferenceEntry,依次将他们在accessQueue中放到队尾去
drainRecencyQueue();
ReferenceEntry<K, V> e;
// 清除掉那些最近写时间过期的缓存项。
while ((e = writeQueue.peek()) != null && map.isExpired(e, now)) {
if (!removeEntry(e, e.getHash(), RemovalCause.EXPIRED)) {
throw new AssertionError();
}
}
// 清除掉那些最近访问时间过期的缓存项。
while ((e = accessQueue.peek()) != null && map.isExpired(e, now)) {
if (!removeEntry(e, e.getHash(), RemovalCause.EXPIRED)) {
throw new AssertionError();
}
}
}
// eviction
@GuardedBy("Segment.this")
void enqueueNotification(ReferenceEntry<K, V> entry, RemovalCause cause) {
enqueueNotification(entry.getKey(), entry.getHash(), entry.getValueReference(), cause);
}
@GuardedBy("Segment.this")
void enqueueNotification(@Nullable K key, int hash, ValueReference<K, V> valueReference,
RemovalCause cause) {
totalWeight -= valueReference.getWeight();
if (cause.wasEvicted()) {
statsCounter.recordEviction();
}
if (map.removalNotificationQueue != DISCARDING_QUEUE) {
V value = valueReference.get();
RemovalNotification<K, V> notification = new RemovalNotification<K, V>(key, value, cause);
map.removalNotificationQueue.offer(notification);
}
}
/**
* Performs eviction if the segment is full. This should only be called prior to adding a new entry and increasing {@code count}.
*/
@GuardedBy("Segment.this")
void evictEntries() {
if (!map.evictsBySize()) {
return;
}
drainRecencyQueue();
// totalWeight是当前Segement中的ReferenceEntry的个数,maxSegmentWeight是当前Segement最多才能出的Segement个数。
// maxSegmentWeight计算逻辑?
while (totalWeight > maxSegmentWeight) {
// getNextEvictable()这个就是在从accessQueue中出队
ReferenceEntry<K, V> e = getNextEvictable();
if (!removeEntry(e, e.getHash(), RemovalCause.SIZE)) {
throw new AssertionError();
}
}
}
// TODO(fry): instead implement this with an eviction head
ReferenceEntry<K, V> getNextEvictable() {
for (ReferenceEntry<K, V> e : accessQueue) {
int weight = e.getValueReference().getWeight();
if (weight > 0) {
return e;
}
}
throw new AssertionError();
}
/**
* Returns first entry of bin for given hash.
*/
ReferenceEntry<K, V> getFirst(int hash) {
// read this volatile field only once
AtomicReferenceArray<ReferenceEntry<K, V>> table = this.table;
return table.get(hash & (table.length() - 1));
}
// Specialized implementations of map methods
@Nullable
ReferenceEntry<K, V> getEntry(Object key, int hash) {
for (ReferenceEntry<K, V> e = getFirst(hash); e != null; e = e.getNext()) {
if (e.getHash() != hash) {
continue;
}
K entryKey = e.getKey();
if (entryKey == null) {
tryDrainReferenceQueues();
continue;
}
if (map.keyEquivalence.equivalent(key, entryKey)) {
return e;
}
}
return null;
}
@Nullable
ReferenceEntry<K, V> getLiveEntry(Object key, int hash, long now) {
ReferenceEntry<K, V> e = getEntry(key, hash);
if (e == null) {
return null;
} else if (map.isExpired(e, now)) {
tryExpireEntries(now);
return null;
}
return e;
}
/**
* Gets the value from an entry. Returns null if the entry is invalid, partially-collected, loading, or expired.
*/
V getLiveValue(ReferenceEntry<K, V> entry, long now) {
if (entry.getKey() == null) {
tryDrainReferenceQueues();
return null;
}
V value = entry.getValueReference().get();
if (value == null) {
tryDrainReferenceQueues();
return null;
}
if (map.isExpired(entry, now)) {
tryExpireEntries(now);
return null;
}
return value;
}
@Nullable
V get(Object key, int hash) {
try {
if (count != 0) { // read-volatile
long now = map.ticker.read();
ReferenceEntry<K, V> e = getLiveEntry(key, hash, now);
if (e == null) {
return null;
}
V value = e.getValueReference().get();
if (value != null) {
recordRead(e, now);
// scheduleRefresh()这个地方首先,如果需要reload()就返回reload的值;否则返回入参value
//这个方法的作用就是:如果设置了refreshAfterWrite(3, TimeUnit.SECONDS),那么这里就会去检查,上次写入时间举例现在是否超过了3s
// 如果超过了,那就去调用CacheLoader去重新加载更新一遍数据。注意:虽然这里些的是scheduleRefresh(),但是guava27版本的实现中其实都还是同步的
// 并没有一部实现。
return scheduleRefresh(e, e.getKey(), hash, value, now, map.defaultLoader);
}
tryDrainReferenceQueues();
}
return null;
} finally {
// 这个就是尝试加锁,如果加锁成功将recencyQueue清空,然后将对应的ReferenceEntry一次放到了accessQueue的队头
postReadCleanup();
}
}
boolean containsKey(Object key, int hash) {
try {
if (count != 0) { // read-volatile
long now = map.ticker.read();
ReferenceEntry<K, V> e = getLiveEntry(key, hash, now);
if (e == null) {
return false;
}
return e.getValueReference().get() != null;
}
return false;
} finally {
postReadCleanup();
}
}
/**
* This method is a convenience for testing. Code should call {@link LocalCache#containsValue} directly.
*/
@VisibleForTesting
boolean containsValue(Object value) {
try {
if (count != 0) { // read-volatile
long now = map.ticker.read();
AtomicReferenceArray<ReferenceEntry<K, V>> table = this.table;
int length = table.length();
for (int i = 0; i < length; ++i) {
for (ReferenceEntry<K, V> e = table.get(i); e != null; e = e.getNext()) {
V entryValue = getLiveValue(e, now);
if (entryValue == null) {
continue;
}
if (map.valueEquivalence.equivalent(value, entryValue)) {
return true;
}
}
}
}
return false;
} finally {
postReadCleanup();
}
}
@Nullable
V put(K key, int hash, V value, boolean onlyIfAbsent) {
lock();
try {
long now = map.ticker.read();
// 这个地方会清理另种情况的缓存项:
// 1. 如果key或者value的引用类型不是强引用,那么key或者value任意一个的具体内容被清除了,这个方法就会将对应的entry从缓存中删除。
// 2. 过期时间自动删除:比如设置了expireAfterWrite()/expireAfterAccess(),那么超过这个时间没有访问,对应的缓存项就会被删除。这个会在这里作一次清理。
preWriteCleanup(now);
int newCount = this.count + 1;
if (newCount > this.threshold) {
expand();// 对table数组扩容。
newCount = this.count + 1;
}
// first就是一个table数组中链表的头结点
AtomicReferenceArray<ReferenceEntry<K, V>> table = this.table;
int index = hash & (table.length() - 1);
ReferenceEntry<K, V> first = table.get(index);
// Look for an existing entry.
for (ReferenceEntry<K, V> e = first; e != null; e = e.getNext()) {
K entryKey = e.getKey();
// 这个if中条件=true,说明put(key,value)对应的缓存项已经存在。
if (e.getHash() == hash && entryKey != null && map.keyEquivalence.equivalent(key, entryKey)) {
// We found an existing entry.
ValueReference<K, V> valueReference = e.getValueReference();
V entryValue = valueReference.get();
// 如果设置了softValue()/weakValue(),那么缓存的key-value中的value就不是强引用,那就可能由于内存不够发生gc的时候,将实际的数据回收掉了
// 只是剩下引用对象本身,所以这个地方entryValue==null就会成立。
if (entryValue == null) {
++modCount;
if (valueReference.isActive()) {
enqueueNotification(key, hash, valueReference, RemovalCause.COLLECTED);
setValue(e, key, value, now);
newCount = this.count; // count remains unchanged
} else {
setValue(e, key, value, now);
newCount = this.count + 1;
}
this.count = newCount; // write-volatile
// LRU淘汰,超过缓存大小,淘汰。
evictEntries();
return null;
} else if (onlyIfAbsent) {
// Mimic
// "if (!map.containsKey(key)) ...
// else return map.get(key);
recordLockedRead(e, now);
return entryValue;
} else {
// clobber existing entry, count remains unchanged
++modCount;
enqueueNotification(key, hash, valueReference, RemovalCause.REPLACED);
setValue(e, key, value, now);
evictEntries();
return entryValue;
}
}
}
// Create a new entry.
++modCount;
ReferenceEntry<K, V> newEntry = newEntry(key, hash, first);
setValue(newEntry, key, value, now);
table.set(index, newEntry);
newCount = this.count + 1;
this.count = newCount; // write-volatile
// LRU缓存淘汰:guava cache的LRU策略是依赖Segement#accessQueue和recencyQueue来实现的:
// 1. 每次put()的时候,如果对应的key存在,则将这个key对应的ReferenceEntry移动到accessQueue的队尾;如果不存在,新增一个ReferenceEntry,也会放到accessQueue的队尾
// 2. 没测get()的时候,都会将查询到的这个ReferenceEntry放到recencyQueue的队尾。
evictEntries();
return null;
} finally {
unlock();
postWriteCleanup();
}
}
/**
* Expands the table if possible.
*/
@GuardedBy("Segment.this")
void expand() {
AtomicReferenceArray<ReferenceEntry<K, V>> oldTable = table;
int oldCapacity = oldTable.length();
if (oldCapacity >= MAXIMUM_CAPACITY) {
return;
}
/*
* Reclassify nodes in each list to new Map. Because we are using power-of-two expansion, the
* elements from each bin must either stay at same index, or move with a power of two offset.
* We eliminate unnecessary node creation by catching cases where old nodes can be reused
* because their next fields won't change. Statistically, at the default threshold, only
* about one-sixth of them need cloning when a table doubles. The nodes they replace will be
* garbage collectable as soon as they are no longer referenced by any reader thread that may
* be in the midst of traversing table right now.
*/
int newCount = count;
AtomicReferenceArray<ReferenceEntry<K, V>> newTable = newEntryArray(oldCapacity << 1);
threshold = newTable.length() * 3 / 4;
int newMask = newTable.length() - 1;
for (int oldIndex = 0; oldIndex < oldCapacity; ++oldIndex) {
// We need to guarantee that any existing reads of old Map can
// proceed. So we cannot yet null out each bin.
ReferenceEntry<K, V> head = oldTable.get(oldIndex);
if (head != null) {
ReferenceEntry<K, V> next = head.getNext();
int headIndex = head.getHash() & newMask;
// Single node on list
if (next == null) {
newTable.set(headIndex, head);
} else {
// Reuse the consecutive sequence of nodes with the same target
// index from the end of the list. tail points to the first
// entry in the reusable list.
ReferenceEntry<K, V> tail = head;
int tailIndex = headIndex;
for (ReferenceEntry<K, V> e = next; e != null; e = e.getNext()) {
int newIndex = e.getHash() & newMask;
if (newIndex != tailIndex) {
// The index changed. We'll need to copy the previous entry.
tailIndex = newIndex;
tail = e;
}
}
newTable.set(tailIndex, tail);
// Clone nodes leading up to the tail.
for (ReferenceEntry<K, V> e = head; e != tail; e = e.getNext()) {
int newIndex = e.getHash() & newMask;
ReferenceEntry<K, V> newNext = newTable.get(newIndex);
ReferenceEntry<K, V> newFirst = copyEntry(e, newNext);
if (newFirst != null) {
newTable.set(newIndex, newFirst);
} else {
removeCollectedEntry(e);
newCount--;
}
}
}
}
}
table = newTable;
this.count = newCount;
}
boolean replace(K key, int hash, V oldValue, V newValue) {
lock();
try {
long now = map.ticker.read();
preWriteCleanup(now);
AtomicReferenceArray<ReferenceEntry<K, V>> table = this.table;
int index = hash & (table.length() - 1);
ReferenceEntry<K, V> first = table.get(index);
for (ReferenceEntry<K, V> e = first; e != null; e = e.getNext()) {
K entryKey = e.getKey();
if (e.getHash() == hash && entryKey != null
&& map.keyEquivalence.equivalent(key, entryKey)) {
ValueReference<K, V> valueReference = e.getValueReference();
V entryValue = valueReference.get();
if (entryValue == null) {
if (valueReference.isActive()) {
// If the value disappeared, this entry is partially collected.
int newCount = this.count - 1;
++modCount;
ReferenceEntry<K, V> newFirst = removeValueFromChain(
first, e, entryKey, hash, valueReference, RemovalCause.COLLECTED);
newCount = this.count - 1;
table.set(index, newFirst);
this.count = newCount; // write-volatile
}
return false;
}
if (map.valueEquivalence.equivalent(oldValue, entryValue)) {
++modCount;
enqueueNotification(key, hash, valueReference, RemovalCause.REPLACED);
setValue(e, key, newValue, now);
evictEntries();
return true;
} else {
// Mimic
// "if (map.containsKey(key) && map.get(key).equals(oldValue))..."
recordLockedRead(e, now);
return false;
}
}
}
return false;
} finally {
unlock();
postWriteCleanup();
}
}
@Nullable
V replace(K key, int hash, V newValue) {
lock();
try {
long now = map.ticker.read();
preWriteCleanup(now);
AtomicReferenceArray<ReferenceEntry<K, V>> table = this.table;
int index = hash & (table.length() - 1);
ReferenceEntry<K, V> first = table.get(index);
for (ReferenceEntry<K, V> e = first; e != null; e = e.getNext()) {
K entryKey = e.getKey();
if (e.getHash() == hash && entryKey != null
&& map.keyEquivalence.equivalent(key, entryKey)) {
ValueReference<K, V> valueReference = e.getValueReference();
V entryValue = valueReference.get();
if (entryValue == null) {
if (valueReference.isActive()) {
// If the value disappeared, this entry is partially collected.
int newCount = this.count - 1;
++modCount;
ReferenceEntry<K, V> newFirst = removeValueFromChain(
first, e, entryKey, hash, valueReference, RemovalCause.COLLECTED);
newCount = this.count - 1;
table.set(index, newFirst);
this.count = newCount; // write-volatile
}
return null;
}
++modCount;
enqueueNotification(key, hash, valueReference, RemovalCause.REPLACED);
setValue(e, key, newValue, now);
evictEntries();
return entryValue;
}
}
return null;
} finally {
unlock();
postWriteCleanup();
}
}
@Nullable
V remove(Object key, int hash) {
lock();
try {
long now = map.ticker.read();
preWriteCleanup(now);
int newCount = this.count - 1;
AtomicReferenceArray<ReferenceEntry<K, V>> table = this.table;
int index = hash & (table.length() - 1);
ReferenceEntry<K, V> first = table.get(index);
for (ReferenceEntry<K, V> e = first; e != null; e = e.getNext()) {
K entryKey = e.getKey();
if (e.getHash() == hash && entryKey != null
&& map.keyEquivalence.equivalent(key, entryKey)) {
ValueReference<K, V> valueReference = e.getValueReference();
V entryValue = valueReference.get();
RemovalCause cause;
if (entryValue != null) {
cause = RemovalCause.EXPLICIT;
} else if (valueReference.isActive()) {
cause = RemovalCause.COLLECTED;
} else {
// currently loading
return null;
}
++modCount;
ReferenceEntry<K, V> newFirst = removeValueFromChain(
first, e, entryKey, hash, valueReference, cause);
newCount = this.count - 1;
table.set(index, newFirst);
this.count = newCount; // write-volatile
return entryValue;
}
}
return null;
} finally {
unlock();
postWriteCleanup();
}
}
boolean storeLoadedValue(K key, int hash, LoadingValueReference<K, V> oldValueReference,
V newValue) {
lock();
try {
long now = map.ticker.read();
preWriteCleanup(now);
int newCount = this.count + 1;
if (newCount > this.threshold) { // ensure capacity
expand();
newCount = this.count + 1;
}
AtomicReferenceArray<ReferenceEntry<K, V>> table = this.table;
int index = hash & (table.length() - 1);
ReferenceEntry<K, V> first = table.get(index);
for (ReferenceEntry<K, V> e = first; e != null; e = e.getNext()) {
K entryKey = e.getKey();
if (e.getHash() == hash && entryKey != null
&& map.keyEquivalence.equivalent(key, entryKey)) {
ValueReference<K, V> valueReference = e.getValueReference();
V entryValue = valueReference.get();
// replace the old LoadingValueReference if it's live, otherwise
// perform a putIfAbsent
if (oldValueReference == valueReference
|| (entryValue == null && valueReference != UNSET)) {
++modCount;
if (oldValueReference.isActive()) {
RemovalCause cause =
(entryValue == null) ? RemovalCause.COLLECTED : RemovalCause.REPLACED;
enqueueNotification(key, hash, oldValueReference, cause);
newCount--;
}
setValue(e, key, newValue, now);
this.count = newCount; // write-volatile
evictEntries();
return true;
}
// the loaded value was already clobbered
valueReference = new WeightedStrongValueReference<K, V>(newValue, 0);
enqueueNotification(key, hash, valueReference, RemovalCause.REPLACED);
return false;
}
}
++modCount;
ReferenceEntry<K, V> newEntry = newEntry(key, hash, first);
setValue(newEntry, key, newValue, now);
table.set(index, newEntry);
this.count = newCount; // write-volatile
evictEntries();
return true;
} finally {
unlock();
postWriteCleanup();
}
}
boolean remove(Object key, int hash, Object value) {
lock();
try {
long now = map.ticker.read();
preWriteCleanup(now);
int newCount = this.count - 1;
AtomicReferenceArray<ReferenceEntry<K, V>> table = this.table;
int index = hash & (table.length() - 1);
ReferenceEntry<K, V> first = table.get(index);
for (ReferenceEntry<K, V> e = first; e != null; e = e.getNext()) {
K entryKey = e.getKey();
if (e.getHash() == hash && entryKey != null
&& map.keyEquivalence.equivalent(key, entryKey)) {
ValueReference<K, V> valueReference = e.getValueReference();
V entryValue = valueReference.get();
RemovalCause cause;
if (map.valueEquivalence.equivalent(value, entryValue)) {
cause = RemovalCause.EXPLICIT;
} else if (entryValue == null && valueReference.isActive()) {
cause = RemovalCause.COLLECTED;
} else {
// currently loading
return false;
}
++modCount;
ReferenceEntry<K, V> newFirst = removeValueFromChain(
first, e, entryKey, hash, valueReference, cause);
newCount = this.count - 1;
table.set(index, newFirst);
this.count = newCount; // write-volatile
return (cause == RemovalCause.EXPLICIT);
}
}
return false;
} finally {
unlock();
postWriteCleanup();
}
}
void clear() {
if (count != 0) { // read-volatile
lock();
try {
AtomicReferenceArray<ReferenceEntry<K, V>> table = this.table;
for (int i = 0; i < table.length(); ++i) {
for (ReferenceEntry<K, V> e = table.get(i); e != null; e = e.getNext()) {
// Loading references aren't actually in the map yet.
if (e.getValueReference().isActive()) {
enqueueNotification(e, RemovalCause.EXPLICIT);
}
}
}
for (int i = 0; i < table.length(); ++i) {
table.set(i, null);
}
clearReferenceQueues();
writeQueue.clear();
accessQueue.clear();
readCount.set(0);
++modCount;
count = 0; // write-volatile
} finally {
unlock();
postWriteCleanup();
}
}
}
// 删除指定entry,first是这个entry所在链表,key/hash/valueReference就是这个entry中的内容,其实这里不传也是ok的。
@GuardedBy("Segment.this")
@Nullable
ReferenceEntry<K, V> removeValueFromChain(ReferenceEntry<K, V> first,
ReferenceEntry<K, V> entry, @Nullable K key, int hash,
ValueReference<K, V> valueReference,
RemovalCause cause) {
// 发布删除时间,RemovalListener会监听这个事件。
enqueueNotification(key, hash, valueReference, cause);
writeQueue.remove(entry);
accessQueue.remove(entry);
if (valueReference.isLoading()) {
valueReference.notifyNewValue(null);
return first;
} else {
return removeEntryFromChain(first, entry);
}
}
// 从first为头节点的链表中删除指定的entry,返回的是删除entry后的头结点
@GuardedBy("Segment.this")
@Nullable
ReferenceEntry<K, V> removeEntryFromChain(ReferenceEntry<K, V> first, ReferenceEntry<K, V> entry) {
int newCount = count;
ReferenceEntry<K, V> newFirst = entry.getNext();
for (ReferenceEntry<K, V> e = first; e != entry; e = e.getNext()) {
ReferenceEntry<K, V> next = copyEntry(e, newFirst);
if (next != null) {
newFirst = next;
} else {
removeCollectedEntry(e);
newCount--;
}
}
this.count = newCount;
return newFirst;
}
@GuardedBy("Segment.this")
void removeCollectedEntry(ReferenceEntry<K, V> entry) {
enqueueNotification(entry, RemovalCause.COLLECTED);
writeQueue.remove(entry);
accessQueue.remove(entry);
}
/**
* Removes an entry whose key has been garbage collected.
*/
boolean reclaimKey(ReferenceEntry<K, V> entry, int hash) {
lock();
try {
int newCount = count - 1;
// first是entry所在的table的坑位上的链表的头结点。
AtomicReferenceArray<ReferenceEntry<K, V>> table = this.table;
int index = hash & (table.length() - 1);
ReferenceEntry<K, V> first = table.get(index);
// 遍历链表,找到入参的entry。
for (ReferenceEntry<K, V> e = first; e != null; e = e.getNext()) {
if (e == entry) {
++modCount;
ReferenceEntry<K, V> newFirst = removeValueFromChain(first, e, e.getKey(), hash, e.getValueReference(),
RemovalCause.COLLECTED);
newCount = this.count - 1;
table.set(index, newFirst);
this.count = newCount; // write-volatile
return true;
}
}
return false;
} finally {
unlock();
postWriteCleanup();
}
}
/**
* Removes an entry whose value has been garbage collected.
*/
boolean reclaimValue(K key, int hash, ValueReference<K, V> valueReference) {
lock();
try {
int newCount = this.count - 1;
AtomicReferenceArray<ReferenceEntry<K, V>> table = this.table;
int index = hash & (table.length() - 1);
ReferenceEntry<K, V> first = table.get(index);
for (ReferenceEntry<K, V> e = first; e != null; e = e.getNext()) {
K entryKey = e.getKey();
if (e.getHash() == hash && entryKey != null
&& map.keyEquivalence.equivalent(key, entryKey)) {
ValueReference<K, V> v = e.getValueReference();
if (v == valueReference) {
++modCount;
ReferenceEntry<K, V> newFirst = removeValueFromChain(
first, e, entryKey, hash, valueReference, RemovalCause.COLLECTED);
newCount = this.count - 1;
table.set(index, newFirst);
this.count = newCount; // write-volatile
return true;
}
return false;
}
}
return false;
} finally {
unlock();
if (!isHeldByCurrentThread()) { // don't cleanup inside of put
postWriteCleanup();
}
}
}
boolean removeLoadingValue(K key, int hash, LoadingValueReference<K, V> valueReference) {
lock();
try {
AtomicReferenceArray<ReferenceEntry<K, V>> table = this.table;
int index = hash & (table.length() - 1);
ReferenceEntry<K, V> first = table.get(index);
for (ReferenceEntry<K, V> e = first; e != null; e = e.getNext()) {
K entryKey = e.getKey();
if (e.getHash() == hash && entryKey != null
&& map.keyEquivalence.equivalent(key, entryKey)) {
ValueReference<K, V> v = e.getValueReference();
if (v == valueReference) {
if (valueReference.isActive()) {
e.setValueReference(valueReference.getOldValue());
} else {
ReferenceEntry<K, V> newFirst = removeEntryFromChain(first, e);
table.set(index, newFirst);
}
return true;
}
return false;
}
}
return false;
} finally {
unlock();
postWriteCleanup();
}
}
// 删除指定entry,并发布一个删除事件。
@GuardedBy("Segment.this")
boolean removeEntry(ReferenceEntry<K, V> entry, int hash, RemovalCause cause) {
int newCount = this.count - 1;
AtomicReferenceArray<ReferenceEntry<K, V>> table = this.table;
int index = hash & (table.length() - 1);
ReferenceEntry<K, V> first = table.get(index);
for (ReferenceEntry<K, V> e = first; e != null; e = e.getNext()) {
if (e == entry) {
++modCount;
ReferenceEntry<K, V> newFirst = removeValueFromChain(
first, e, e.getKey(), hash, e.getValueReference(), cause);
newCount = this.count - 1;
table.set(index, newFirst);
this.count = newCount; // write-volatile
return true;
}
}
return false;
}
/**
* Performs routine cleanup following a read. Normally cleanup happens during writes. If cleanup is not observed after a sufficient
* number of reads, try cleaning up from the read thread.
*/
void postReadCleanup() {
// DRAIN_THRESHOLD=63,这个if就是看读取次数有没有到了63。这也是在debug的时候会发现recencyQueue命名是在不断往里add(),但是这个队列的总个数"始终"没有超过63的原因
// 这里不是说recencyQueue真的不会超过63,是因为debug的时候没有什么竞争,一到了63个的时候,tryLock()能够获得锁,所以就给清除了,如果有竞争的情况下,这里tryLock()不成功,是完全有可能超过63的
if ((readCount.incrementAndGet() & DRAIN_THRESHOLD) == 0) {
cleanUp();
}
}
/**
* Performs routine cleanup prior to executing a write. This should be called every time a write thread acquires the segment lock,
* immediately after acquiring the lock.
*
* <p>Post-condition: expireEntries has been run.
*/
@GuardedBy("Segment.this")
void preWriteCleanup(long now) {
runLockedCleanup(now);
}
/**
* Performs routine cleanup following a write.
*/
void postWriteCleanup() {
runUnlockedCleanup();
}
void cleanUp() {
long now = map.ticker.read();
runLockedCleanup(now);
runUnlockedCleanup();
}
void runLockedCleanup(long now) {
// 这里是tryLock(),而不是lock(),目的就是当有竞争你的时候不会阻塞:拿到所就做下面的事情,拿不到就不做
if (tryLock()) {
try {
// 如果key或者value的引用不是强引用,这个方法就是将那些实际内容被gc回收了的key/value对应的ReferenceEntry从链表中删除。
drainReferenceQueues();
// 1. 清空recencyQueue,去改变accessQueue
// 2.清除根据最近写/最近访问时间,已经过期的缓存项,比如设置了accessAfter(5s),则一个key最近访问5s后还没有访问,这里就会将其从缓存删除。
expireEntries(now); // calls drainRecencyQueue
// readCount这个变量的作用就是控制recencyQueue批量的大小的,没有其他的作用,这里已经清空了recencyQueue,这个变量就可以归零了。
readCount.set(0);
} finally {
unlock();
}
}
}
void runUnlockedCleanup() {
// locked cleanup may generate notifications we can send unlocked
if (!isHeldByCurrentThread()) {
map.processPendingNotifications();
}
}
}
static class LoadingValueReference<K, V> implements ValueReference<K, V> {
volatile ValueReference<K, V> oldValue;
// TODO(fry): rename get, then extend AbstractFuture instead of containing SettableFuture
final SettableFuture<V> futureValue = SettableFuture.create();
final Stopwatch stopwatch = Stopwatch.createUnstarted();
public LoadingValueReference() {
this(LocalCache.<K, V>unset());
}
public LoadingValueReference(ValueReference<K, V> oldValue) {
this.oldValue = oldValue;
}
@Override
public boolean isLoading() {
return true;
}
@Override
public boolean isActive() {
return oldValue.isActive();
}
@Override
public int getWeight() {
return oldValue.getWeight();
}
public boolean set(@Nullable V newValue) {
return futureValue.set(newValue);
}
public boolean setException(Throwable t) {
return futureValue.setException(t);
}
private ListenableFuture<V> fullyFailedFuture(Throwable t) {
return Futures.immediateFailedFuture(t);
}
@Override
public void notifyNewValue(@Nullable V newValue) {
if (newValue != null) {
// The pending load was clobbered by a manual write.
// Unblock all pending gets, and have them return the new value.
set(newValue);
} else {
// The pending load was removed. Delay notifications until loading completes.
oldValue = unset();
}
// TODO(fry): could also cancel loading if we had a handle on its future
}
public ListenableFuture<V> loadFuture(K key, CacheLoader<? super K, V> loader) {
stopwatch.start();
V previousValue = oldValue.get();
try {
// 如果老的值已经没有了,那其实跟缓存中没有,去加载逻辑是一样的。
if (previousValue == null) {
V newValue = loader.load(key);
return set(newValue) ? futureValue : Futures.immediateFuture(newValue);
}
// 这里是缓存中的值存在,去重新加载的逻辑。其内部逻辑实际上就是直接去调用了CacheLoader#load()方法,所以这里其实是同步的。但是我们可以重写reload()方法,变成异步的。
ListenableFuture<V> newValue = loader.reload(key, previousValue);
if (newValue == null) {
return Futures.immediateFuture(null);
}
// To avoid a race, make sure the refreshed value is set into loadingValueReference
// *before* returning newValue from the cache query.
return Futures.transform(newValue, new Function<V, V>() {
@Override
public V apply(V newValue) {
LoadingValueReference.this.set(newValue);
return newValue;
}
});
} catch (Throwable t) {
if (t instanceof InterruptedException) {
Thread.currentThread().interrupt();
}
return setException(t) ? futureValue : fullyFailedFuture(t);
}
}
public long elapsedNanos() {
return stopwatch.elapsed(NANOSECONDS);
}
@Override
public V waitForValue() throws ExecutionException {
return getUninterruptibly(futureValue);
}
@Override
public V get() {
return oldValue.get();
}
public ValueReference<K, V> getOldValue() {
return oldValue;
}
@Override
public ReferenceEntry<K, V> getEntry() {
return null;
}
@Override
public ValueReference<K, V> copyFor(
ReferenceQueue<V> queue, @Nullable V value, ReferenceEntry<K, V> entry) {
return this;
}
}
// Queues
/**
* A custom queue for managing eviction order. Note that this is tightly integrated with {@code ReferenceEntry}, upon which it relies to
* perform its linking.
*
* <p>Note that this entire implementation makes the assumption that all elements which are in
* the map are also in this queue, and that all elements not in the queue are not in the map.
*
* <p>The benefits of creating our own queue are that (1) we can replace elements in the middle
* of the queue as part of copyWriteEntry, and (2) the contains method is highly optimized for the current model.
*/
static final class WriteQueue<K, V> extends AbstractQueue<ReferenceEntry<K, V>> {
final ReferenceEntry<K, V> head = new AbstractReferenceEntry<K, V>() {
@Override
public long getWriteTime() {
return Long.MAX_VALUE;
}
@Override
public void setWriteTime(long time) {}
ReferenceEntry<K, V> nextWrite = this;
@Override
public ReferenceEntry<K, V> getNextInWriteQueue() {
return nextWrite;
}
@Override
public void setNextInWriteQueue(ReferenceEntry<K, V> next) {
this.nextWrite = next;
}
ReferenceEntry<K, V> previousWrite = this;
@Override
public ReferenceEntry<K, V> getPreviousInWriteQueue() {
return previousWrite;
}
@Override
public void setPreviousInWriteQueue(ReferenceEntry<K, V> previous) {
this.previousWrite = previous;
}
};
// implements Queue
@Override
public boolean offer(ReferenceEntry<K, V> entry) {
// unlink
connectWriteOrder(entry.getPreviousInWriteQueue(), entry.getNextInWriteQueue());
// add to tail
connectWriteOrder(head.getPreviousInWriteQueue(), entry);
connectWriteOrder(entry, head);
return true;
}
@Override
public ReferenceEntry<K, V> peek() {
ReferenceEntry<K, V> next = head.getNextInWriteQueue();
return (next == head) ? null : next;
}
@Override
public ReferenceEntry<K, V> poll() {
ReferenceEntry<K, V> next = head.getNextInWriteQueue();
if (next == head) {
return null;
}
remove(next);
return next;
}
@Override
@SuppressWarnings("unchecked")
public boolean remove(Object o) {
ReferenceEntry<K, V> e = (ReferenceEntry) o;
ReferenceEntry<K, V> previous = e.getPreviousInWriteQueue();
ReferenceEntry<K, V> next = e.getNextInWriteQueue();
connectWriteOrder(previous, next);
nullifyWriteOrder(e);
return next != NullEntry.INSTANCE;
}
@Override
@SuppressWarnings("unchecked")
public boolean contains(Object o) {
ReferenceEntry<K, V> e = (ReferenceEntry) o;
return e.getNextInWriteQueue() != NullEntry.INSTANCE;
}
@Override
public boolean isEmpty() {
return head.getNextInWriteQueue() == head;
}
@Override
public int size() {
int size = 0;
for (ReferenceEntry<K, V> e = head.getNextInWriteQueue(); e != head;
e = e.getNextInWriteQueue()) {
size++;
}
return size;
}
@Override
public void clear() {
ReferenceEntry<K, V> e = head.getNextInWriteQueue();
while (e != head) {
ReferenceEntry<K, V> next = e.getNextInWriteQueue();
nullifyWriteOrder(e);
e = next;
}
head.setNextInWriteQueue(head);
head.setPreviousInWriteQueue(head);
}
@Override
public Iterator<ReferenceEntry<K, V>> iterator() {
return new AbstractSequentialIterator<ReferenceEntry<K, V>>(peek()) {
@Override
protected ReferenceEntry<K, V> computeNext(ReferenceEntry<K, V> previous) {
ReferenceEntry<K, V> next = previous.getNextInWriteQueue();
return (next == head) ? null : next;
}
};
}
}
/**
* A custom queue for managing access order. Note that this is tightly integrated with {@code ReferenceEntry}, upon which it reliese to
* perform its linking.
*
* <p>Note that this entire implementation makes the assumption that all elements which are in
* the map are also in this queue, and that all elements not in the queue are not in the map.
*
* <p>The benefits of creating our own queue are that (1) we can replace elements in the middle
* of the queue as part of copyWriteEntry, and (2) the contains method is highly optimized for the current model.
*/
static final class AccessQueue<K, V> extends AbstractQueue<ReferenceEntry<K, V>> {
final ReferenceEntry<K, V> head = new AbstractReferenceEntry<K, V>() {
@Override
public long getAccessTime() {
return Long.MAX_VALUE;
}
@Override
public void setAccessTime(long time) {}
ReferenceEntry<K, V> nextAccess = this;
@Override
public ReferenceEntry<K, V> getNextInAccessQueue() {
return nextAccess;
}
@Override
public void setNextInAccessQueue(ReferenceEntry<K, V> next) {
this.nextAccess = next;
}
ReferenceEntry<K, V> previousAccess = this;
@Override
public ReferenceEntry<K, V> getPreviousInAccessQueue() {
return previousAccess;
}
@Override
public void setPreviousInAccessQueue(ReferenceEntry<K, V> previous) {
this.previousAccess = previous;
}
};
// implements Queue
@Override
public boolean offer(ReferenceEntry<K, V> entry) {
// unlink
connectAccessOrder(entry.getPreviousInAccessQueue(), entry.getNextInAccessQueue());
// add to tail
connectAccessOrder(head.getPreviousInAccessQueue(), entry);
connectAccessOrder(entry, head);
return true;
}
@Override
public ReferenceEntry<K, V> peek() {
ReferenceEntry<K, V> next = head.getNextInAccessQueue();
return (next == head) ? null : next;
}
@Override
public ReferenceEntry<K, V> poll() {
ReferenceEntry<K, V> next = head.getNextInAccessQueue();
if (next == head) {
return null;
}
remove(next);
return next;
}
@Override
@SuppressWarnings("unchecked")
public boolean remove(Object o) {
ReferenceEntry<K, V> e = (ReferenceEntry) o;
ReferenceEntry<K, V> previous = e.getPreviousInAccessQueue();
ReferenceEntry<K, V> next = e.getNextInAccessQueue();
connectAccessOrder(previous, next);
nullifyAccessOrder(e);
return next != NullEntry.INSTANCE;
}
@Override
@SuppressWarnings("unchecked")
public boolean contains(Object o) {
ReferenceEntry<K, V> e = (ReferenceEntry) o;
return e.getNextInAccessQueue() != NullEntry.INSTANCE;
}
@Override
public boolean isEmpty() {
return head.getNextInAccessQueue() == head;
}
@Override
public int size() {
int size = 0;
for (ReferenceEntry<K, V> e = head.getNextInAccessQueue(); e != head;
e = e.getNextInAccessQueue()) {
size++;
}
return size;
}
@Override
public void clear() {
ReferenceEntry<K, V> e = head.getNextInAccessQueue();
while (e != head) {
ReferenceEntry<K, V> next = e.getNextInAccessQueue();
nullifyAccessOrder(e);
e = next;
}
head.setNextInAccessQueue(head);
head.setPreviousInAccessQueue(head);
}
@Override
public Iterator<ReferenceEntry<K, V>> iterator() {
return new AbstractSequentialIterator<ReferenceEntry<K, V>>(peek()) {
@Override
protected ReferenceEntry<K, V> computeNext(ReferenceEntry<K, V> previous) {
ReferenceEntry<K, V> next = previous.getNextInAccessQueue();
return (next == head) ? null : next;
}
};
}
}
// Cache support
public void cleanUp() {
for (Segment<?, ?> segment : segments) {
segment.cleanUp();
}
}
// ConcurrentMap methods
@Override
public boolean isEmpty() {
/*
* Sum per-segment modCounts to avoid mis-reporting when elements are concurrently added and
* removed in one segment while checking another, in which case the table was never actually
* empty at any point. (The sum ensures accuracy up through at least 1<<31 per-segment
* modifications before recheck.) Method containsValue() uses similar constructions for
* stability checks.
*/
long sum = 0L;
Segment<K, V>[] segments = this.segments;
for (int i = 0; i < segments.length; ++i) {
if (segments[i].count != 0) {
return false;
}
sum += segments[i].modCount;
}
if (sum != 0L) { // recheck unless no modifications
for (int i = 0; i < segments.length; ++i) {
if (segments[i].count != 0) {
return false;
}
sum -= segments[i].modCount;
}
if (sum != 0L) {
return false;
}
}
return true;
}
long longSize() {
Segment<K, V>[] segments = this.segments;
long sum = 0;
for (int i = 0; i < segments.length; ++i) {
sum += segments[i].count;
}
return sum;
}
@Override
public int size() {
return Ints.saturatedCast(longSize());
}
@Override
@Nullable
public V get(@Nullable Object key) {
if (key == null) {
return null;
}
int hash = hash(key);
return segmentFor(hash).get(key, hash);
}
@Nullable
public V getIfPresent(Object key) {
int hash = hash(checkNotNull(key));
V value = segmentFor(hash).get(key, hash);
if (value == null) {
globalStatsCounter.recordMisses(1);
} else {
globalStatsCounter.recordHits(1);
}
return value;
}
V get(K key, CacheLoader<? super K, V> loader) throws ExecutionException {
int hash = hash(checkNotNull(key));
return segmentFor(hash).get(key, hash, loader);
}
V getOrLoad(K key) throws ExecutionException {
return get(key, defaultLoader);
}
ImmutableMap<K, V> getAllPresent(Iterable<?> keys) {
int hits = 0;
int misses = 0;
Map<K, V> result = Maps.newLinkedHashMap();
for (Object key : keys) {
V value = get(key);
if (value == null) {
misses++;
} else {
// TODO(fry): store entry key instead of query key
@SuppressWarnings("unchecked")
K castKey = (K) key;
result.put(castKey, value);
hits++;
}
}
globalStatsCounter.recordHits(hits);
globalStatsCounter.recordMisses(misses);
return ImmutableMap.copyOf(result);
}
ImmutableMap<K, V> getAll(Iterable<? extends K> keys) throws ExecutionException {
int hits = 0;
int misses = 0;
Map<K, V> result = Maps.newLinkedHashMap();
Set<K> keysToLoad = Sets.newLinkedHashSet();
for (K key : keys) {
V value = get(key);
if (!result.containsKey(key)) {
result.put(key, value);
if (value == null) {
misses++;
keysToLoad.add(key);
} else {
hits++;
}
}
}
try {
if (!keysToLoad.isEmpty()) {
try {
Map<K, V> newEntries = loadAll(keysToLoad, defaultLoader);
for (K key : keysToLoad) {
V value = newEntries.get(key);
if (value == null) {
throw new InvalidCacheLoadException("loadAll failed to return a value for " + key);
}
result.put(key, value);
}
} catch (UnsupportedLoadingOperationException e) {
// loadAll not implemented, fallback to load
for (K key : keysToLoad) {
misses--; // get will count this miss
result.put(key, get(key, defaultLoader));
}
}
}
return ImmutableMap.copyOf(result);
} finally {
globalStatsCounter.recordHits(hits);
globalStatsCounter.recordMisses(misses);
}
}
/**
* Returns the result of calling {@link CacheLoader#loadAll}, or null if {@code loader} doesn't implement {@code loadAll}.
*/
@Nullable
Map<K, V> loadAll(Set<? extends K> keys, CacheLoader<? super K, V> loader)
throws ExecutionException {
checkNotNull(loader);
checkNotNull(keys);
Stopwatch stopwatch = Stopwatch.createStarted();
Map<K, V> result;
boolean success = false;
try {
@SuppressWarnings("unchecked") // safe since all keys extend K
Map<K, V> map = (Map<K, V>) loader.loadAll(keys);
result = map;
success = true;
} catch (com.zj.cache.guavacache.CacheLoader.UnsupportedLoadingOperationException e) {
success = true;
throw e;
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
throw new ExecutionException(e);
} catch (RuntimeException e) {
throw new UncheckedExecutionException(e);
} catch (Exception e) {
throw new ExecutionException(e);
} catch (Error e) {
throw new ExecutionError(e);
} finally {
if (!success) {
globalStatsCounter.recordLoadException(stopwatch.elapsed(NANOSECONDS));
}
}
if (result == null) {
globalStatsCounter.recordLoadException(stopwatch.elapsed(NANOSECONDS));
throw new InvalidCacheLoadException(loader + " returned null map from loadAll");
}
stopwatch.stop();
// TODO(fry): batch by segment
boolean nullsPresent = false;
for (Entry<K, V> entry : result.entrySet()) {
K key = entry.getKey();
V value = entry.getValue();
if (key == null || value == null) {
// delay failure until non-null entries are stored
nullsPresent = true;
} else {
put(key, value);
}
}
if (nullsPresent) {
globalStatsCounter.recordLoadException(stopwatch.elapsed(NANOSECONDS));
throw new InvalidCacheLoadException(loader + " returned null keys or values from loadAll");
}
// TODO(fry): record count of loaded entries
globalStatsCounter.recordLoadSuccess(stopwatch.elapsed(NANOSECONDS));
return result;
}
/**
* Returns the internal entry for the specified key. The entry may be loading, expired, or partially collected.
*/
ReferenceEntry<K, V> getEntry(@Nullable Object key) {
// does not impact recency ordering
if (key == null) {
return null;
}
int hash = hash(key);
return segmentFor(hash).getEntry(key, hash);
}
void refresh(K key) {
int hash = hash(checkNotNull(key));
segmentFor(hash).refresh(key, hash, defaultLoader, false);
}
@Override
public boolean containsKey(@Nullable Object key) {
// does not impact recency ordering
if (key == null) {
return false;
}
int hash = hash(key);
return segmentFor(hash).containsKey(key, hash);
}
@Override
public boolean containsValue(@Nullable Object value) {
// does not impact recency ordering
if (value == null) {
return false;
}
// This implementation is patterned after ConcurrentHashMap, but without the locking. The only
// way for it to return a false negative would be for the target value to jump around in the map
// such that none of the subsequent iterations observed it, despite the fact that at every point
// in time it was present somewhere int the map. This becomes increasingly unlikely as
// CONTAINS_VALUE_RETRIES increases, though without locking it is theoretically possible.
long now = ticker.read();
final Segment<K, V>[] segments = this.segments;
long last = -1L;
for (int i = 0; i < CONTAINS_VALUE_RETRIES; i++) {
long sum = 0L;
for (Segment<K, V> segment : segments) {
// ensure visibility of most recent completed write
@SuppressWarnings({"UnusedDeclaration", "unused"})
int c = segment.count; // read-volatile
AtomicReferenceArray<ReferenceEntry<K, V>> table = segment.table;
for (int j = 0; j < table.length(); j++) {
for (ReferenceEntry<K, V> e = table.get(j); e != null; e = e.getNext()) {
V v = segment.getLiveValue(e, now);
if (v != null && valueEquivalence.equivalent(value, v)) {
return true;
}
}
}
sum += segment.modCount;
}
if (sum == last) {
break;
}
last = sum;
}
return false;
}
@Override
public V put(K key, V value) {
checkNotNull(key);
checkNotNull(value);
int hash = hash(key);
return segmentFor(hash).put(key, hash, value, false);
}
@Override
public V putIfAbsent(K key, V value) {
checkNotNull(key);
checkNotNull(value);
int hash = hash(key);
return segmentFor(hash).put(key, hash, value, true);
}
@Override
public void putAll(Map<? extends K, ? extends V> m) {
for (Entry<? extends K, ? extends V> e : m.entrySet()) {
put(e.getKey(), e.getValue());
}
}
@Override
public V remove(@Nullable Object key) {
if (key == null) {
return null;
}
int hash = hash(key);
return segmentFor(hash).remove(key, hash);
}
@Override
public boolean remove(@Nullable Object key, @Nullable Object value) {
if (key == null || value == null) {
return false;
}
int hash = hash(key);
return segmentFor(hash).remove(key, hash, value);
}
@Override
public boolean replace(K key, @Nullable V oldValue, V newValue) {
checkNotNull(key);
checkNotNull(newValue);
if (oldValue == null) {
return false;
}
int hash = hash(key);
return segmentFor(hash).replace(key, hash, oldValue, newValue);
}
@Override
public V replace(K key, V value) {
checkNotNull(key);
checkNotNull(value);
int hash = hash(key);
return segmentFor(hash).replace(key, hash, value);
}
@Override
public void clear() {
for (Segment<K, V> segment : segments) {
segment.clear();
}
}
void invalidateAll(Iterable<?> keys) {
// TODO(fry): batch by segment
for (Object key : keys) {
remove(key);
}
}
Set<K> keySet;
@Override
public Set<K> keySet() {
// does not impact recency ordering
Set<K> ks = keySet;
return (ks != null) ? ks : (keySet = new KeySet(this));
}
Collection<V> values;
@Override
public Collection<V> values() {
// does not impact recency ordering
Collection<V> vs = values;
return (vs != null) ? vs : (values = new Values(this));
}
Set<Entry<K, V>> entrySet;
@Override
@GwtIncompatible("Not supported.")
public Set<Entry<K, V>> entrySet() {
// does not impact recency ordering
Set<Entry<K, V>> es = entrySet;
return (es != null) ? es : (entrySet = new EntrySet(this));
}
// Iterator Support
abstract class HashIterator<T> implements Iterator<T> {
int nextSegmentIndex;
int nextTableIndex;
Segment<K, V> currentSegment;
AtomicReferenceArray<ReferenceEntry<K, V>> currentTable;
ReferenceEntry<K, V> nextEntry;
WriteThroughEntry nextExternal;
WriteThroughEntry lastReturned;
HashIterator() {
nextSegmentIndex = segments.length - 1;
nextTableIndex = -1;
advance();
}
@Override
public abstract T next();
final void advance() {
nextExternal = null;
if (nextInChain()) {
return;
}
if (nextInTable()) {
return;
}
while (nextSegmentIndex >= 0) {
currentSegment = segments[nextSegmentIndex--];
if (currentSegment.count != 0) {
currentTable = currentSegment.table;
nextTableIndex = currentTable.length() - 1;
if (nextInTable()) {
return;
}
}
}
}
/**
* Finds the next entry in the current chain. Returns true if an entry was found.
*/
boolean nextInChain() {
if (nextEntry != null) {
for (nextEntry = nextEntry.getNext(); nextEntry != null; nextEntry = nextEntry.getNext()) {
if (advanceTo(nextEntry)) {
return true;
}
}
}
return false;
}
/**
* Finds the next entry in the current table. Returns true if an entry was found.
*/
boolean nextInTable() {
while (nextTableIndex >= 0) {
if ((nextEntry = currentTable.get(nextTableIndex--)) != null) {
if (advanceTo(nextEntry) || nextInChain()) {
return true;
}
}
}
return false;
}
/**
* Advances to the given entry. Returns true if the entry was valid, false if it should be skipped.
*/
boolean advanceTo(ReferenceEntry<K, V> entry) {
try {
long now = ticker.read();
K key = entry.getKey();
V value = getLiveValue(entry, now);
if (value != null) {
nextExternal = new WriteThroughEntry(key, value);
return true;
} else {
// Skip stale entry.
return false;
}
} finally {
currentSegment.postReadCleanup();
}
}
@Override
public boolean hasNext() {
return nextExternal != null;
}
WriteThroughEntry nextEntry() {
if (nextExternal == null) {
throw new NoSuchElementException();
}
lastReturned = nextExternal;
advance();
return lastReturned;
}
@Override
public void remove() {
checkState(lastReturned != null);
LocalCache.this.remove(lastReturned.getKey());
lastReturned = null;
}
}
final class KeyIterator extends HashIterator<K> {
@Override
public K next() {
return nextEntry().getKey();
}
}
final class ValueIterator extends HashIterator<V> {
@Override
public V next() {
return nextEntry().getValue();
}
}
/**
* Custom Entry class used by EntryIterator.next(), that relays setValue changes to the underlying map.
*/
final class WriteThroughEntry implements Entry<K, V> {
final K key; // non-null
V value; // non-null
WriteThroughEntry(K key, V value) {
this.key = key;
this.value = value;
}
@Override
public K getKey() {
return key;
}
@Override
public V getValue() {
return value;
}
@Override
public boolean equals(@Nullable Object object) {
// Cannot use key and value equivalence
if (object instanceof Entry) {
Entry<?, ?> that = (Entry<?, ?>) object;
return key.equals(that.getKey()) && value.equals(that.getValue());
}
return false;
}
@Override
public int hashCode() {
// Cannot use key and value equivalence
return key.hashCode() ^ value.hashCode();
}
@Override
public V setValue(V newValue) {
throw new UnsupportedOperationException();
}
/**
* Returns a string representation of the form <code>{key}={value}</code>.
*/
@Override
public String toString() {
return getKey() + "=" + getValue();
}
}
final class EntryIterator extends HashIterator<Entry<K, V>> {
@Override
public Entry<K, V> next() {
return nextEntry();
}
}
abstract class AbstractCacheSet<T> extends AbstractSet<T> {
final ConcurrentMap<?, ?> map;
AbstractCacheSet(ConcurrentMap<?, ?> map) {
this.map = map;
}
@Override
public int size() {
return map.size();
}
@Override
public boolean isEmpty() {
return map.isEmpty();
}
@Override
public void clear() {
map.clear();
}
}
final class KeySet extends AbstractCacheSet<K> {
KeySet(ConcurrentMap<?, ?> map) {
super(map);
}
@Override
public Iterator<K> iterator() {
return new KeyIterator();
}
@Override
public boolean contains(Object o) {
return map.containsKey(o);
}
@Override
public boolean remove(Object o) {
return map.remove(o) != null;
}
}
final class Values extends AbstractCacheSet<V> {
Values(ConcurrentMap<?, ?> map) {
super(map);
}
@Override
public Iterator<V> iterator() {
return new ValueIterator();
}
@Override
public boolean contains(Object o) {
return map.containsValue(o);
}
}
final class EntrySet extends AbstractCacheSet<Entry<K, V>> {
EntrySet(ConcurrentMap<?, ?> map) {
super(map);
}
@Override
public Iterator<Entry<K, V>> iterator() {
return new EntryIterator();
}
@Override
public boolean contains(Object o) {
if (!(o instanceof Entry)) {
return false;
}
Entry<?, ?> e = (Entry<?, ?>) o;
Object key = e.getKey();
if (key == null) {
return false;
}
V v = LocalCache.this.get(key);
return v != null && valueEquivalence.equivalent(e.getValue(), v);
}
@Override
public boolean remove(Object o) {
if (!(o instanceof Entry)) {
return false;
}
Entry<?, ?> e = (Entry<?, ?>) o;
Object key = e.getKey();
return key != null && LocalCache.this.remove(key, e.getValue());
}
}
// Serialization Support
/**
* Serializes the configuration of a LocalCache, reconsitituting it as a Cache using CacheBuilder upon deserialization. An instance of
* this class is fit for use by the writeReplace of LocalManualCache.
* <p>
* Unfortunately, readResolve() doesn't get called when a circular dependency is present, so the proxy must be able to behave as the
* cache itself.
*/
static class ManualSerializationProxy<K, V>
extends ForwardingCache<K, V> implements Serializable {
private static final long serialVersionUID = 1;
final Strength keyStrength;
final Strength valueStrength;
final Equivalence<Object> keyEquivalence;
final Equivalence<Object> valueEquivalence;
final long expireAfterWriteNanos;
final long expireAfterAccessNanos;
final long maxWeight;
final Weigher<K, V> weigher;
final int concurrencyLevel;
final RemovalListener<? super K, ? super V> removalListener;
final Ticker ticker;
final CacheLoader<? super K, V> loader;
transient Cache<K, V> delegate;
ManualSerializationProxy(LocalCache<K, V> cache) {
this(
cache.keyStrength,
cache.valueStrength,
cache.keyEquivalence,
cache.valueEquivalence,
cache.expireAfterWriteNanos,
cache.expireAfterAccessNanos,
cache.maxWeight,
cache.weigher,
cache.concurrencyLevel,
cache.removalListener,
cache.ticker,
cache.defaultLoader);
}
private ManualSerializationProxy(
Strength keyStrength, Strength valueStrength,
Equivalence<Object> keyEquivalence, Equivalence<Object> valueEquivalence,
long expireAfterWriteNanos, long expireAfterAccessNanos, long maxWeight,
Weigher<K, V> weigher, int concurrencyLevel,
RemovalListener<? super K, ? super V> removalListener,
Ticker ticker, CacheLoader<? super K, V> loader) {
this.keyStrength = keyStrength;
this.valueStrength = valueStrength;
this.keyEquivalence = keyEquivalence;
this.valueEquivalence = valueEquivalence;
this.expireAfterWriteNanos = expireAfterWriteNanos;
this.expireAfterAccessNanos = expireAfterAccessNanos;
this.maxWeight = maxWeight;
this.weigher = weigher;
this.concurrencyLevel = concurrencyLevel;
this.removalListener = removalListener;
this.ticker = (ticker == Ticker.systemTicker() || ticker == NULL_TICKER)
? null : ticker;
this.loader = loader;
}
CacheBuilder<K, V> recreateCacheBuilder() {
CacheBuilder<K, V> builder = CacheBuilder.newBuilder()
.setKeyStrength(keyStrength)
.setValueStrength(valueStrength)
.keyEquivalence(keyEquivalence)
.valueEquivalence(valueEquivalence)
.concurrencyLevel(concurrencyLevel)
.removalListener(removalListener);
builder.strictParsing = false;
if (expireAfterWriteNanos > 0) {
builder.expireAfterWrite(expireAfterWriteNanos, TimeUnit.NANOSECONDS);
}
if (expireAfterAccessNanos > 0) {
builder.expireAfterAccess(expireAfterAccessNanos, TimeUnit.NANOSECONDS);
}
if (weigher != CacheBuilder.OneWeigher.INSTANCE) {
builder.weigher(weigher);
if (maxWeight != UNSET_INT) {
builder.maximumWeight(maxWeight);
}
} else {
if (maxWeight != UNSET_INT) {
builder.maximumSize(maxWeight);
}
}
if (ticker != null) {
builder.ticker(ticker);
}
return builder;
}
private void readObject(ObjectInputStream in) throws IOException, ClassNotFoundException {
in.defaultReadObject();
com.google.common.cache.CacheBuilder<K, V> builder = recreateCacheBuilder();
this.delegate = builder.build();
}
private Object readResolve() {
return delegate;
}
@Override
protected Cache<K, V> delegate() {
return delegate;
}
}
/**
* Serializes the configuration of a LocalCache, reconsitituting it as an LoadingCache using CacheBuilder upon deserialization. An
* instance of this class is fit for use by the writeReplace of LocalLoadingCache.
* <p>
* Unfortunately, readResolve() doesn't get called when a circular dependency is present, so the proxy must be able to behave as the
* cache itself.
*/
static final class LoadingSerializationProxy<K, V>
extends ManualSerializationProxy<K, V> implements LoadingCache<K, V>, Serializable {
private static final long serialVersionUID = 1;
transient LoadingCache<K, V> autoDelegate;
LoadingSerializationProxy(LocalCache<K, V> cache) {
super(cache);
}
private void readObject(ObjectInputStream in) throws IOException, ClassNotFoundException {
in.defaultReadObject();
com.google.common.cache.CacheBuilder<K, V> builder = recreateCacheBuilder();
this.autoDelegate = builder.build(loader);
}
@Override
public V get(K key) throws ExecutionException {
return autoDelegate.get(key);
}
@Override
public V getUnchecked(K key) {
return autoDelegate.getUnchecked(key);
}
@Override
public ImmutableMap<K, V> getAll(Iterable<? extends K> keys) throws ExecutionException {
return autoDelegate.getAll(keys);
}
@Override
public final V apply(K key) {
return autoDelegate.apply(key);
}
@Override
public void refresh(K key) {
autoDelegate.refresh(key);
}
private Object readResolve() {
return autoDelegate;
}
}
static class LocalManualCache<K, V> implements Cache<K, V>, Serializable {
final LocalCache<K, V> localCache;
LocalManualCache(com.google.common.cache.CacheBuilder<? super K, ? super V> builder) {
this(new LocalCache<K, V>(builder, null));
}
private LocalManualCache(LocalCache<K, V> localCache) {
this.localCache = localCache;
}
// Cache methods
@Override
@Nullable
public V getIfPresent(Object key) {
return localCache.getIfPresent(key);
}
@Override
public V get(K key, final Callable<? extends V> valueLoader) throws ExecutionException {
checkNotNull(valueLoader);
return localCache.get(key, new CacheLoader<Object, V>() {
@Override
public V load(Object key) throws Exception {
return valueLoader.call();
}
});
}
@Override
public ImmutableMap<K, V> getAllPresent(Iterable<?> keys) {
return localCache.getAllPresent(keys);
}
@Override
public void put(K key, V value) {
localCache.put(key, value);
}
@Override
public void putAll(Map<? extends K, ? extends V> m) {
localCache.putAll(m);
}
@Override
public void invalidate(Object key) {
checkNotNull(key);
localCache.remove(key);
}
@Override
public void invalidateAll(Iterable<?> keys) {
localCache.invalidateAll(keys);
}
@Override
public void invalidateAll() {
localCache.clear();
}
@Override
public long size() {
return localCache.longSize();
}
@Override
public ConcurrentMap<K, V> asMap() {
return localCache;
}
@Override
public CacheStats stats() {
SimpleStatsCounter aggregator = new SimpleStatsCounter();
aggregator.incrementBy(localCache.globalStatsCounter);
for (Segment<K, V> segment : localCache.segments) {
aggregator.incrementBy(segment.statsCounter);
}
return aggregator.snapshot();
}
@Override
public void cleanUp() {
localCache.cleanUp();
}
// Serialization Support
private static final long serialVersionUID = 1;
Object writeReplace() {
return new ManualSerializationProxy<K, V>(localCache);
}
}
static class LocalLoadingCache<K, V>
extends LocalManualCache<K, V> implements LoadingCache<K, V> {
LocalLoadingCache(com.google.common.cache.CacheBuilder<? super K, ? super V> builder,
CacheLoader<? super K, V> loader) {
super(new LocalCache<K, V>(builder, checkNotNull(loader)));
}
// LoadingCache methods
@Override
public V get(K key) throws ExecutionException {
return localCache.getOrLoad(key);
}
@Override
public V getUnchecked(K key) {
try {
return get(key);
} catch (ExecutionException e) {
throw new UncheckedExecutionException(e.getCause());
}
}
@Override
public ImmutableMap<K, V> getAll(Iterable<? extends K> keys) throws ExecutionException {
return localCache.getAll(keys);
}
@Override
public void refresh(K key) {
localCache.refresh(key);
}
@Override
public final V apply(K key) {
return getUnchecked(key);
}
// Serialization Support
private static final long serialVersionUID = 1;
@Override
Object writeReplace() {
return new LoadingSerializationProxy<K, V>(localCache);
}
}
}














 982
982











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









