






在携程技术中心推出的线上公开课程[携程技术微分享]上,携程酒店研发BI经理潘鹏举介绍了如何借助大数据和算法,通过机器学习去克服酒店服务行业挑战。目前的应用主要包括订单量预测、回复市场预测、询房预测和用户价格偏好预测。采用的算法包括GBM、SVD++、XGBoost以及集成建模等。
携程是一家在线OTA服务公司,特点包括天生限时限购、每个酒店库存固定、代理房型、与酒店直接谈合作房型等。作为第三方平台,OTA酒店行业也面临众多挑战,比如无法掌握实际库存,依赖酒店行为;有些酒店设备落后,导致无法系统直连、无法接入EBK系统,所以管理起来比较困难。
酒店服务主要从好、快、准三个方面来衡量。“好”的KPI包括“到店无房率”和“到店无预订率”,“快”包括“订单确认时长”和“立即确认率”,“准”则包括了“信息准”、“价格准”、“房态准”。随着业务量的持续增长,持续增加客服人员来维持高服务水准就变得不太现实,借助于技术手段来实现自动化、智能化是一个很好的方向,机器学习算法在其中扮演了一个很重要的角色。
数据应用与模型评估
携程每天产生2亿PV,10TB的数据量。但数据大!=价值大,其中用到的数据大体分成四块:业务数据、网站性能数据、用户行为数据和爬虫数据,实践中主要会用到业务数据和用户行为数据,业务数据包括了订单数据、房态、房价等数据,用户行为数据包括了用户点击、浏览等数据。
一般性数据时效性越高,数据价值越大。未来的人工智能就是基于过去和当前的状态来预测未来,再用预测来影响未来。如果只用冷数据即过去的数据,比如统计报表、数据分析,那么可以挖到银矿,因为分析过去的数据只能控制未来不会犯同样的错误,但若结合过去和当下的数据预测了未来,那么可以挖到钻石,因为可以用预测结果和实际进行对比发现新的黑天鹅现象,从而来指导业务进行转变。

另外可能会有一个误区,我们都想要追求100%准确的数据。实际上,数据很难100%准确,尤其是用户行为数据,任何一种采集方式都会有PV漏记、错记的情况。因此我们要能容忍一定的数据采集偏差,在现有的数据中看如何利用数据创造价值。
还要注意,在算法应用到线上的过程中,人工经验、人工过滤以及风控会起到很关键的作用。如果没有做到这点,那么在实际应用中会大打折扣。正如人是商业的CPU,决策过程中要依赖人来调整方向。而风控是决定应用快慢的GPU,如果没有做好风控措施,不仅可能会导致业务损失也有可能让算法没有发挥出作用。
将理念运用到实践过程中,有三种常用的模型评估方法:
- A/BTest: AA测试用来评估分流是否随机,该方法在项目中使用率较高;
- 隔周/隔天对比:为了替代A/BTest的简单办法,针对有些情况下面很难做AB实验;
- 模型空跑:评估+风控的方式,先上线模型,但是业务不采纳模型结果,然后用log解析模型是否运转正确及效果。
机器学习提升用户预订体验
携程按照预定流程,区分了预订前、中、后流程,主要目的是为了提升客户体验和提高服务效率。预订前的主要目的是为了让信息更加准确、预订中主要是为了提升预订效率和速度,预订后就是为了订单风控、酒店风控和客人风控。
订单量预测应用
我们通过应用进行业务监控,做到准实时,延迟一分钟预测。从预测到应用,其实运用了简单的ARIMA+季节系数+人工调整算法,设计出模型。评估指标主要是看漏报率,不同阶段重点不同,在稳定期间,误报率较为重要,因为系统稳定了,需要尽量减少人力损失。
回复时长预测应用
在服务指标中,“快”体现了我们的服务速度,有两个重要KPI:立即确认和订单确认时长。我们有个业务逻辑叫保留房,是酒店承诺给携程的库存量。针对保留房我们可以立即确认订单给客人,确认时长为零。针对非保留房,确认速度比较慢,需要等酒店回复信息之后才能确认订单给客人,导致客人体验差,当然并不是所有的酒店都愿意和我们签订保留房,并且保留房有时间限制,到了入住日晚上X点以后,保留房就失效了,所以非保留房的存在,决定了“快”的服务水准。针对提高非保留房的服务水准是我们的一个很重要的课题。
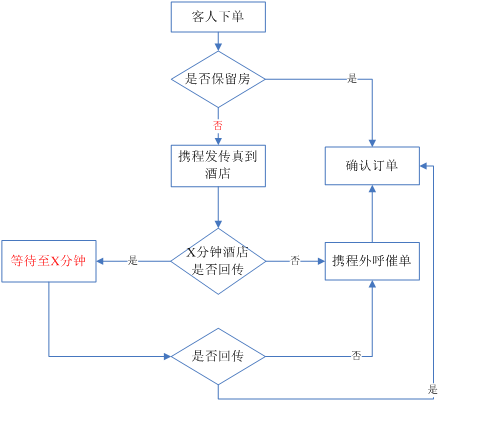
对整个流程进行分析,我们发现有两个可以优化的点:
非保留房的确认率90%+,意味着推翻的订单10%都不到,如果我们可以对非保留房里面的确认概率高(确认准确率99%+,与保留房的确认率持平)的订单先确认,那么实际上非保留房的流程可以遵循保留房的流程,暂且称为虚拟保留房。针对怎么挑出这些确认概率高的订单命题,机器学习算法就起作用了;
红色部分“等待至X分钟“设置的不合理,因为有些酒店在X分钟内是肯定不回传的,还要硬等X分钟,导致很多订单确认时长就白白多了X分钟。那么针对哪些订单是肯定不回传,哪些是回传的命题,机器学习算法就发挥作用了。
针对这两个优化的点,我们嵌入了两个机器学习模型,我们看一下优化后的流程是怎么样的:
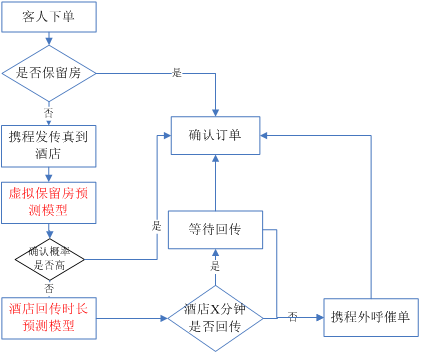
从红色部分的两个模型上可以看到,虚拟保留房可以新增立即确认订单占比,从而提高确认速度;酒店回传时长预测模型优化了现有的订单外呼流程,针对有部分的时长过长的订单提前干预,从而缩短了整体的确认时长。
我们看一下模型最终的效果,虚拟保留房预测模型准确率99%+,酒店回传时长预测模型准确率93%+。整体提升立即确认率5%,缩短平均确认时长约2分钟。通过以上的案例可以看到,模型很好的提升了用户的预订体验,取得了不错的效果。
机器学习提升大户室询房效率
过去,询房主要是人工经验为主,经理们会根据过去的房型预订情况和区域紧张度情况,筛选出今天要重点询问的酒店列表,然后大户室人员会对酒店列表打电话询问房态,酒店数量庞大,人工询问的电话量有限,如何提升询房有效率,即每通电话的有效性是个很棘手的问题。
过去一年,我们着力于使用机器学习算法来预测酒店的房态和技术手段持续的优化流程,提高询房有效性,通过算法筛选询房酒店比人工经验筛选的有效性从25%左右提升到了50%+,这是个很显著的提升,可以大大节省人工成本,提高工作效率。
以下是优化后的流程:
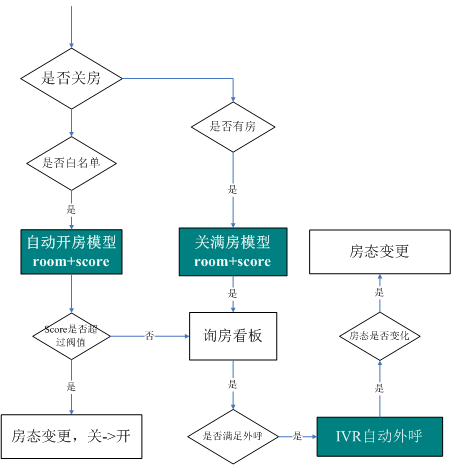
简单的说是变化的是两个模型+IVR自动外呼。自动开房模型采用GBM和SVD++,关满房模型采用XGBoost。过这两个模型,我们把房态变化概率高的酒店先筛选出来,放在询房看板上。IVR自动外呼概率高的酒店。通过这一流程改造,我们尽量实现了询房的自动化、智能化。但目前的决策过程中,对准确率不高的房型会有必要的人工介入,然后针对风险的高低,我们会有不同的风控和措施,这样的结合才能让算法的作用最大化。
算法经验
模型项目完整流程包括确定目标、变量设计评审、变量数据准备、线下数据校验、训练&优化模型、模型上线开发、模型空跑测试、模型上线、模型监控等。在携程的场景下,线下数据校验、模型空跑测试和模型监控比较重要。
模型训练方面,特征工程和其他团队的做法区别不大,如下图所示:

特别说明两点:
缺失值预测,如果某些变量对业务帮助很大,但是有一定量的缺失值,那么我们可用另一个模型来预测缺失值,做法就是取出关键变量不存在缺失值的样本进行训练,然后对有缺失值的变量进行预测。
另外还有归一化问题,目前常用的机器学习方法是GBM、XGBoost对量纲不敏感,所以为了减少数据分布的损失较少做归一化。在实际应用中,有些模型是一定要求归一化,因此还是需要进行归一化处理。
模型经验总结如下:
有时候单纯提升变量时效性会显著提高模型的预测能力,前提先证明时效性对结果是有提升的;
以XGBoost/GBM/GBDT(基于SGD和Boosting思想的,叫法和package不同)预测出来的模型当做Baseline,进行后续的优化方向;
数据校验很重要,多做数据校验;
多花时间挖掘出有用的Feature,新增变量+变量转换;
线下训练的模型快速上线,针对线上数据进行参数调优和模型优化;
基本上使用非线性模型,效果好于线性模型。
特别说明第5点,线下模型上线,根据线上数据进行调优,主要是担心线上上线过程中有人为失误导致数据计算有偏差,所以可以直接根据线上模型来进行模型优化来适应线上的开发错误,并且能够快速的定位出开发中的数据错误。
对于非线性关系,效果和算法之间的关系如下图所示:
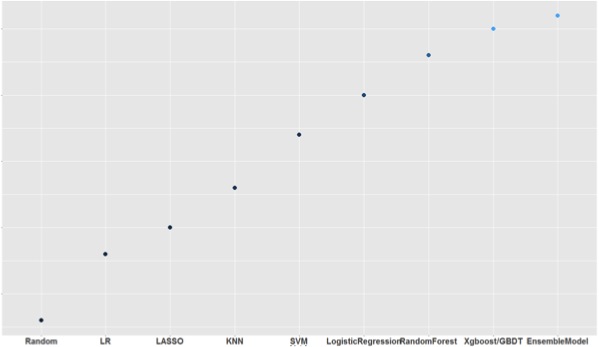
从图中看出,集成建模的效果最好。携程常用的模型融合方法是Stacking和Blending,具体可以参考http://mlwave.com/kaggle-ensembling-guide/。
综上所述,机器学习算法可以帮助公司创造出价值。目前来看,我们的数据利用只是数据价值的冰山一角,也借此机会希望大家多思考一下数据的利用价值,让数据发挥出应有的价值。
本文作者:潘鹏举,携程旅行网酒店研发BI经理

















 1415
1415

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









