









 介绍pdf2docx库,实现PDF文档向Word文档的转换。支持文本样式、表格、图片等元素转换,提供Python库和命令行工具两种使用方式。
介绍pdf2docx库,实现PDF文档向Word文档的转换。支持文本样式、表格、图片等元素转换,提供Python库和命令行工具两种使用方式。
本文简介作者写的一个PDF转Word的Python库pdf2docx,包括基本思路、功能、使用方法及样例。

2023-12-29 更新:
今天正式把pdf2docx仓库的所有版权通过技术转让的方式友情卖给了Artifex Software, Inc.,也就是pdf2docx的一个重要依赖PyMuPDF的母公司。前前后后断断续续3年多的业余研究和开发,即便默默无闻,每一次问题的解决、新功能的发布、星星的获得都成就满满;所以在点下Transfer按钮的那一刻,百感交集。然而,随着工作和家庭负担的加重,我已经有 8 个月没更新过这个库了,Artifex未尝不是pdf2docx的一个好归宿。
1 基本思路
PDF文档遵循一定的规范1,例如精确定位了每个字符出现在页面上的坐标、根据坐标绘制的各种形状(线、矩形、曲线等)。所以,用PDF格式传输和打印文档可以保证格式的一致性,不会像Word那样因为渲染引擎的不同而出现格式错乱、多页少页等问题。
Word文档则是一种流式布局,元素之间的相对距离决定了其呈现在页面上的最终位置。因此适合编辑内容,前文内容的修改自动促发后续文档布局的更新。
PDF转Word是一个古老的话题,其难点在于建立从PDF基于元素位置的格式到Word基于内容的格式的映射。例如,PDF中实际并不存在段落、表格的概念,仅仅是在给定位置上有一些文本、直线,PDF转Word要做的就是将“横、竖线条围绕着文本”解析为“表格”,将“文本及下方的一条横线”解析为“文本下划线”,等等。
具体实现离不开对PDF文档的版式分析,可以是传统的文档元素位置和内容分析,也可以是机器学习/计算机视觉方法训练模型(尤其是针对扫描的PDF文档)。pdf2docx采用的是前者,基本思路:
- 利用
PyMuPDF获取页面元素,例如文本和形状及其位置; - 利用元素间的相对位置关系推断内容;
- 使用
python-docx将上一步解析的内容元素重建为docx格式的Word文档。
以上技术路线也决定了pdf2docx的局限:
- 无法识别和重建PDF扫描件。
- 根据有限的、确定的规则建立PDF与docx元素之间的映射并非完全可靠,也就是说仅能处理常见的规范的格式,而非百分百还原。
2. 功能
-
段落及文本样式
- 段落对齐方式(左/右/居中/分散)及段间距
- 水平(自左向右)或竖直(自底向上)方向的文本
- 字体样式(颜色、字体、大小、粗/斜体)
- 文本样式(高亮、下划线、删除线、超链接)
- 列表样式
-
图片
- 段落内嵌入型图片
- 衬于文本下方的浮动型图片
- 支持Gray/RGB/CMYK等颜色模式及透明背景图片
-
表格及其样式
- 边框样式(粗细、颜色)
- 单元格背景色
- 合并的单元格
- 隐藏部分边框的表格(例如三线表)
- 嵌套表格
-
支持多进程并行处理
3. 快速上手
pdf2docx支持Windows和Linux平台,要求Python版本>=3.6。
首先,通过pip安装:
$ pip install pdf2docx
作为Python库使用
from pdf2docx import Converter
pdf_file = '/path/to/sample.pdf'
docx_file = 'path/to/sample.docx'
# convert pdf to docx
cv = Converter(pdf_file)
cv.convert(docx_file, start=0, end=None)
cv.close()
其中,start和end参数指定转换页码的范围(下标默认从0开始),默认从第一页到最后一页;也可以通过pages指定不连续的页面,例如pages=[1,3,5]。
作为命令行工具使用
pdf2docx也可以作为一个命令行工具,直接在命令窗口中使用:
$ pdf2docx convert /path/to/pdf /path/to/docx
同理可以通过--start、--end或者--pages指定页面范围。
更多说明参考文档2。
4. 样例
-
首先看一个综合样例,涉及段落、文本样式、表格样式及图片。

-
基本表格 (第一行标题存在一点瑕疵,不过可以手动回车调整)
-
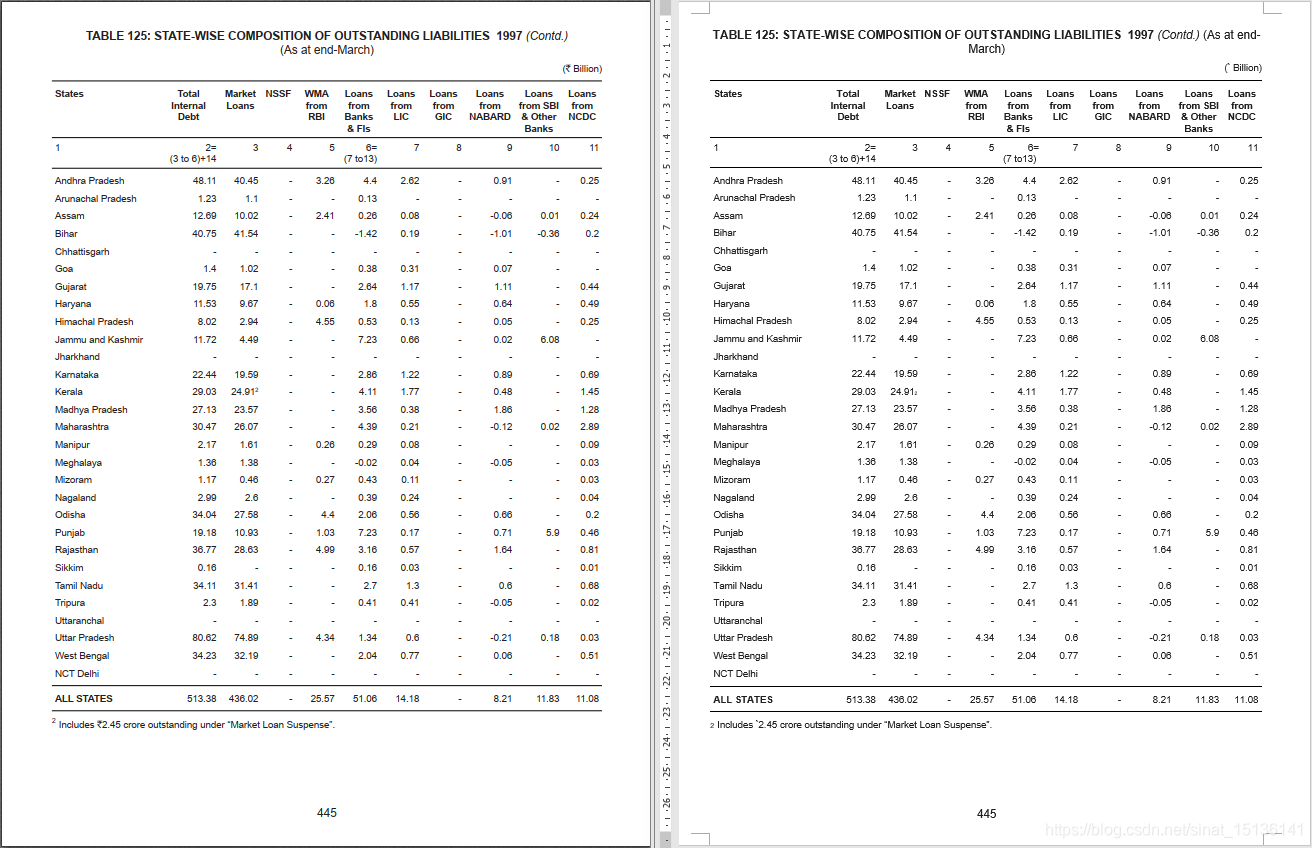
复杂一些的表格 (椭圆章上旋转角度的字都丢掉了,目前无能为力,仅支持水平、竖直的文字;密码区同上一例,第三行字符“49”后面需要手动加一个软回车)

-
最后,看一个浮动图片的例子


















 3359
3359

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









