






Learing Theory
该部分主要让我们对机器学习算法有一定的认知分析能力,而不是只知道如何调取函数,成为调包侠。对算法提前进行分析可以提高研究效率。
1.bias-variance tradeoff
参考线性回归,偏差方差权衡
bias:可以认为是generalization error,即样本集的训练误差。当欠拟合时,bias偏大
variance:当训练得到的模型迁移到另外一组样本时,得到的结果与训练结果之间差异的大小。过拟合时,variance会变大。
损失函数=偏差^2+方差+固有噪音。
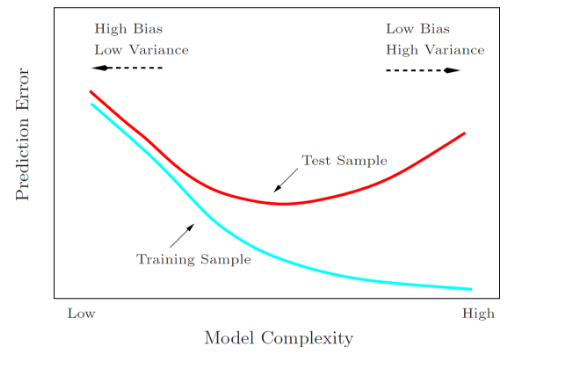
下面这张图能够帮助理解:
接下来介绍一些定义
training error:
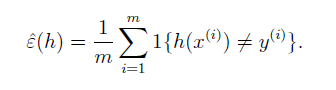
generalization error:
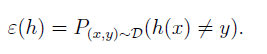
empirical risk minimization (ERM):
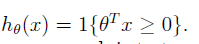
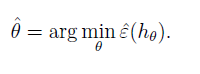
该过程我们叫做ERM,这是一种基础的学习算法。
我们将这种方法进行推广,加入我们想得到非线性的模型,因此我们定义
hypothesisclassH
为一些分类模型的集合。在该假设下,将ERM推广我们得到问题的模型为挑选最合适的h模型:
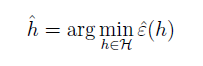
two lemmas
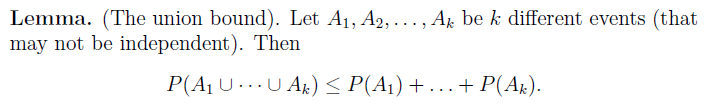

这两条定理能够帮助我们在后面的推导中得到probablity,样本训练个数m,H中模型个数k之间存在的关系。
2.The case of finite H
定义:
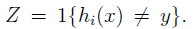
那么在Z中各事件满足条件独立分布IID时,我们可以得到:
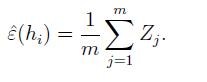
该近似的可信程度由lemma2给出:
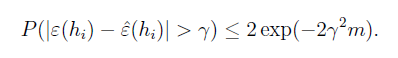
γ
为任意固定的正数,m为训练样本个数,该式表明在一定可信程度下,可以用training error代替generalization error。
接下来我们想证明该结论当
hϵH
依然成立:
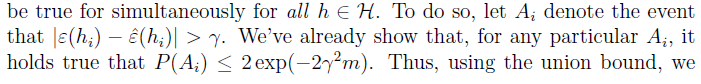
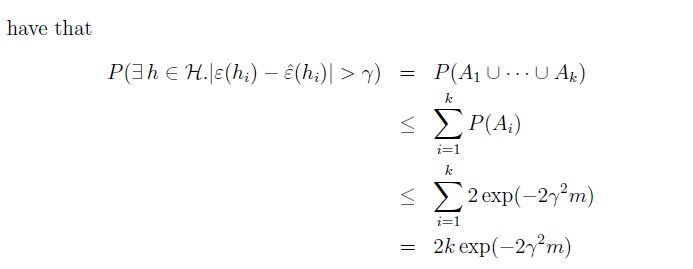
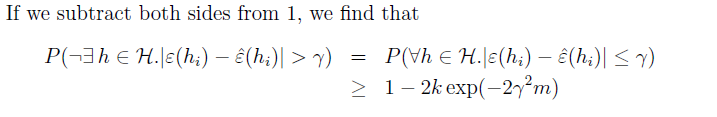
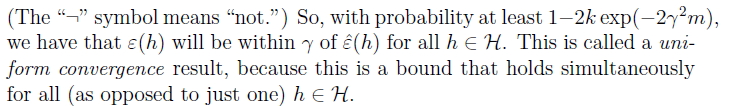
因此我们得到对于集合内所有的h,error估计误差都会在
γ
范围内。
对于给定的指标,我们可以计算出必须的训练个数:
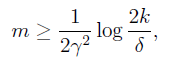
不同算法为了得到相同的performance所需要的不同训练集大小成为sample complexity。值得注意的一点,m~
O(log(k)
,这个性质很重要,在后面会用到。
同样我们可以得到:
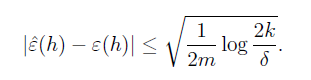
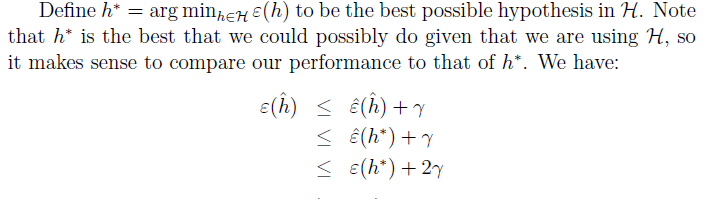
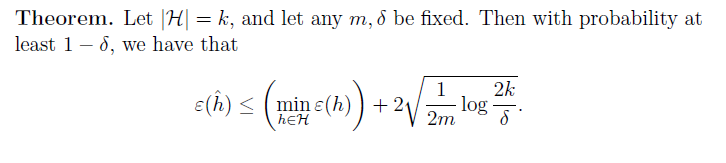
该结论表明了训练得到的最优h和实际上的最优
h∗
之间满足的关系。不等式右边第一项为bias,随着k的增加而减小,第二项为variance,随着k的增加而增大。

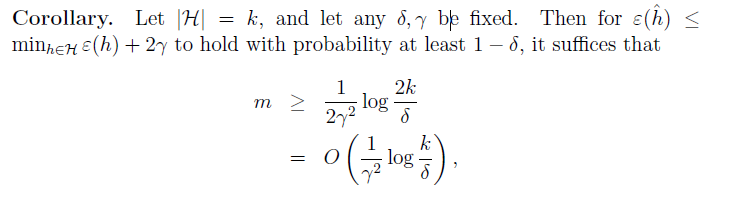















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









