






FM(Factorization Machines)
传统的LR算法是线性模型,想要提取非线性关系,要么通过GBDT来提取非线性特征,要么手动构建非线性特征。
FM直接显示的构建交叉特征,直接建模二阶关系:
公式如下:
y
(
x
)
=
w
0
+
∑
i
=
1
n
w
i
x
i
+
∑
i
=
1
n
∑
j
=
i
+
1
n
w
i
j
x
i
x
j
y(\mathbf{x}) = w_0+ \sum_{i=1}^n w_i x_i + \sum_{i=1}^n \sum_{j=i+1}^n w_{ij} x_i x_j
y(x)=w0+i=1∑nwixi+i=1∑nj=i+1∑nwijxixj
其中
w
i
j
w_{ij}
wij是二阶关系的参数,其个数是
n
(
n
−
1
)
2
\frac{n(n-1)}{2}
2n(n−1),复杂度是
O
(
n
2
)
O(n^2)
O(n2)
优化时间复杂度,矩阵分解提供了一种解决思路,
w
i
j
=
⟨
v
i
,
v
j
⟩
w_{ij} = \langle \mathbf{v}_i, \mathbf{v}_j \rangle
wij=⟨vi,vj⟩ 来代替上式。则:
y
(
x
)
=
w
0
+
∑
i
=
1
n
w
i
x
i
+
∑
i
=
1
n
∑
j
=
i
+
1
n
⟨
v
i
,
v
j
⟩
x
i
x
j
y(\mathbf{x}) = w_0+ \sum_{i=1}^n w_i x_i + \sum_{i=1}^n \sum_{j=i+1}^n \langle \mathbf{v}_i, \mathbf{v}_j \rangle x_i x_j
y(x)=w0+i=1∑nwixi+i=1∑nj=i+1∑n⟨vi,vj⟩xixj
其中,
v
i
v_i
vi是第 i 维特征的隐向量,⟨⋅,⋅⟩ 代表向量点积。隐向量的长度为 k(k«n),包含 k 个描述特征的因子。
直观上看,FM的复杂度是
O
(
k
n
2
)
O(kn^2)
O(kn2),但通过数学化简,可以做到
O
(
k
n
)
O(kn)
O(kn),具体推导如下:
∑
i
=
1
n
∑
j
=
i
+
1
n
⟨
v
i
,
v
j
⟩
x
i
x
j
=
1
2
∑
i
=
1
n
∑
j
=
1
n
⟨
v
i
,
v
j
⟩
x
i
x
j
−
1
2
∑
i
=
1
n
⟨
v
i
,
v
i
⟩
x
i
x
i
=
1
2
(
∑
i
=
1
n
∑
j
=
1
n
∑
f
=
1
k
v
i
f
v
j
f
x
i
x
j
−
∑
i
=
1
n
∑
f
=
1
k
v
i
f
v
i
f
x
i
x
i
)
=
1
2
∑
f
=
1
k
(
(
∑
i
=
1
n
v
i
f
x
i
)
(
∑
j
=
1
n
v
j
f
x
j
)
−
∑
i
=
1
n
v
i
,
f
2
x
i
2
)
=
1
2
∑
f
=
1
k
(
(
∑
i
=
1
n
v
i
f
x
i
)
2
−
∑
i
=
1
n
v
i
,
f
2
x
i
2
)
% <![CDATA[ \begin{aligned} & \sum_{i=1}^n \sum_{j=i+1}^n \langle \mathbf{v}_i, \mathbf{v}_j \rangle x_i x_j \\ = & \frac{1}{2} \sum_{i=1}^n \sum_{j=1}^n \langle \mathbf{v}_i, \mathbf{v}_j \rangle x_i x_j - \frac{1}{2} \sum_{i=1}^n \langle \mathbf{v}_i, \mathbf{v}_i \rangle x_i x_i \\ = & \frac{1}{2} \left( \sum_{i=1}^n \sum_{j=1}^n \sum_{f=1}^k v_{if}v_{jf} x_i x_j - \sum_{i=1}^n \sum_{f=1}^k v_{if}v_{if} x_i x_i \right) \\ = & \frac{1}{2} \sum_{f=1}^k \left( \left(\sum_{i=1}^n v_{if}x_i \right) \left( \sum_{j=1}^n v_{jf}x_j \right) -\sum_{i=1}^n v_{i,f}^2x_i^2 \right) \\ = & \frac{1}{2} \sum_{f=1}^k \left( \left(\sum_{i=1}^n v_{if}x_i \right)^2 -\sum_{i=1}^n v_{i,f}^2x_i^2\right) \end{aligned} %]]>
====i=1∑nj=i+1∑n⟨vi,vj⟩xixj21i=1∑nj=1∑n⟨vi,vj⟩xixj−21i=1∑n⟨vi,vi⟩xixi21⎝⎛i=1∑nj=1∑nf=1∑kvifvjfxixj−i=1∑nf=1∑kvifvifxixi⎠⎞21f=1∑k((i=1∑nvifxi)(j=1∑nvjfxj)−i=1∑nvi,f2xi2)21f=1∑k⎝⎛(i=1∑nvifxi)2−i=1∑nvi,f2xi2⎠⎞
DeepFM
Paper [IJCAI 2017]:
DeepFM: A Factorization-Machine based Neural Network for CTR Prediction
网络结构图
整体网络结构

FM部分:
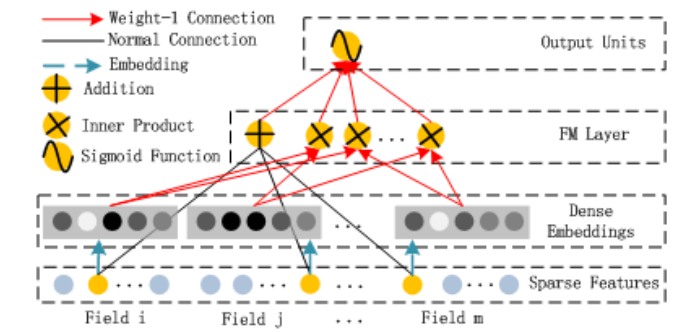
Deep部分:

代码实现(第一种)
数据处理
模型需要输入两个,input_idxs, input_values
- input_idxs是稀疏编码,即每一个分类型的field下各个独一无二的取值,每个连续型field都编码为一个定值。
- input_values是特征取值,分类型field特征取值变为1,连续性field特征取值不变
举个例子:

需要注意的
- second_order_part里面,分类型field和连续型field进行了交叉
- deep_part里面,embedding之后和特征值相乘,再接Dense
代码
import tensorflow as tf
def dnn(params):
dnn_model = tf.keras.Sequential()
for size in params['dnn_hidden_units']:
dnn_model.add(tf.keras.layers.Dense(size, activation='relu', use_bias=False))
dnn_model.add(tf.keras.layers.Dense(1, activation=None, use_bias=False))
return dnn_model
class DeepFM(tf.keras.Model):
def __init__(self, params):
'''
:param params:
feature_size: 编码id大小
factor_size:embedding维度大小,对应公式里的k
field_size: 输入变量个数,对应公式里的f
'''
super(DeepFM, self).__init__()
self.params = params
self.embeddings_1 = tf.keras.layers.Embedding(params['feature_size'], 1)
self.embeddings_2 = tf.keras.layers.Embedding(params['feature_size'], params['factor_size'],
embeddings_regularizer=tf.keras.regularizers.l2(0.00001),
embeddings_initializer=tf.initializers.RandomNormal(
mean=0.0, stddev=0.0001, seed=1024)
)
self.deep_dnn = dnn(params)
self.dense_output = tf.keras.layers.Dense(params['class_num'], activation=params['last_activation'], )
def first_order_part(self, idxs, values):
'''
:return: (n, k)
'''
x = self.embeddings_1(idxs) # (n, f, 1)
x = tf.multiply(x, tf.expand_dims(values, axis=-1)) # (n, f, 1)
x = tf.reduce_sum(x, axis=1) # (n, 1)
return x
def second_order_part(self, idxs, values):
'''2ab = (a+b)^2- (a^2+b^2)
:return (n, k)
'''
x = self.embeddings_2(idxs) # (n, f, k)
x = tf.multiply(x, tf.expand_dims(values, axis=-1)) # (n, f, k)
sum_square = tf.square(tf.reduce_sum(x, axis=1)) # (n, k)
square_sum = tf.reduce_sum(tf.square(x), axis=1) # (n, k)
output = 0.5*(tf.subtract(sum_square, square_sum))
return tf.reduce_sum(output, axis=1, keepdims=True)
return output
def deep_part(self, idxs, values):
'''
:return: (n, 128)
'''
x = self.embeddings_2(idxs)
x = tf.multiply(x, tf.expand_dims(values, axis=-1)) # (n, f, k)
x = tf.reshape(x, (-1, self.params['field_size']*self.params['factor_size']))
x =self.deep_dnn(x)
return x
def call(self, idxs, values):
'''
:param idxs: (n, f)
:param values: (n, f)
:return:
'''
first_order_output = self.first_order_part(idxs, values)
second_order_output = self.second_order_part(idxs, values)
deep_output = self.deep_part(idxs, values)
combined_output = tf.concat([first_order_output, second_order_output, deep_output], axis=1)
output = self.dense_output(combined_output)
return output
if __name__=='__main__':
import numpy as np
params = {
'field_size':12,
'feature_size':5+3,
'factor_size':4,
'class_num': 1,
'last_activation': 'sigmoid',
'dnn_hidden_units': (128, 128)
}
print('Generate fake data...')
x_dense = np.random.random((1000, 5))
x_sparse = np.random.randint(0, 3, (1000, 7))
# 这里x_idxs没有做更高的处理
dense_idxs = np.zeros((x_dense.shape))
for i in range(dense_idxs.shape[1]):
dense_idxs[:, i] = i
x_idxs = np.concatenate([dense_idxs, x_sparse+5], axis=1, )
x_values = np.concatenate([x_dense, np.ones(x_sparse.shape)], axis=1)
x_idxs = tf.convert_to_tensor(x_idxs, dtype=tf.int64)
x_values = tf.convert_to_tensor(x_values, dtype=tf.float32)
y = np.random.randint(0, 2, (1000, 1))
model = DeepFM(params)
pred = model(x_idxs, x_values)
print(pred.shape)















 9663
9663

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









