







 距离上次更新已经不知道有多久了,因为过几日就是中期答辩了,为了不太监开始坚持把这个项目往后做一做。这次我们要做的是什么呢,要先搭建整个开发环境,目前用到的如下:mysql,idea,IKAnalyzer2012_u6(一个开源的分词包,完全够用了)这次我计划先完成最简单的一个推荐系统的设计,目的只为了完成通过余弦相似性来计算文本的相似性,提取特征值采用数据库中最好拆解分析的“原料”列余
距离上次更新已经不知道有多久了,因为过几日就是中期答辩了,为了不太监开始坚持把这个项目往后做一做。这次我们要做的是什么呢,要先搭建整个开发环境,目前用到的如下:mysql,idea,IKAnalyzer2012_u6(一个开源的分词包,完全够用了)这次我计划先完成最简单的一个推荐系统的设计,目的只为了完成通过余弦相似性来计算文本的相似性,提取特征值采用数据库中最好拆解分析的“原料”列余
距离上次更新已经不知道有多久了,因为过几日就是中期答辩了,为了不太监开始坚持把这个项目往后做一做。
这次我们要做的是什么呢,要先搭建整个开发环境,目前用到的如下:mysql,idea,IKAnalyzer2012_u6(一个开源的分词包,完全够用了)
这次我计划先完成最简单的一个推荐系统的设计,目的只为了完成通过余弦相似性来计算文本的相似性,提取特征值采用数据库中最好拆解分析的“原料”列
余弦相似度和tf-idf的参考文章 http://www.ruanyifeng.com/blog/2013/03/cosine_similarity.html
IKAnalyzer 下载地址http://lxw1234.com/archives/2015/07/422.htm
需要用到的jar包:
上面两个在上面那个下载的文件夹里,导入即可,jdbc的java和mysql的连接用的jar包自己搜着下载吧。
用到的数据库:已经放到我百度云里了https://pan.baidu.com/s/1nv4klM5,格式是mdb也就是微软的access,我使用的是navicat将其转换为mysql的。
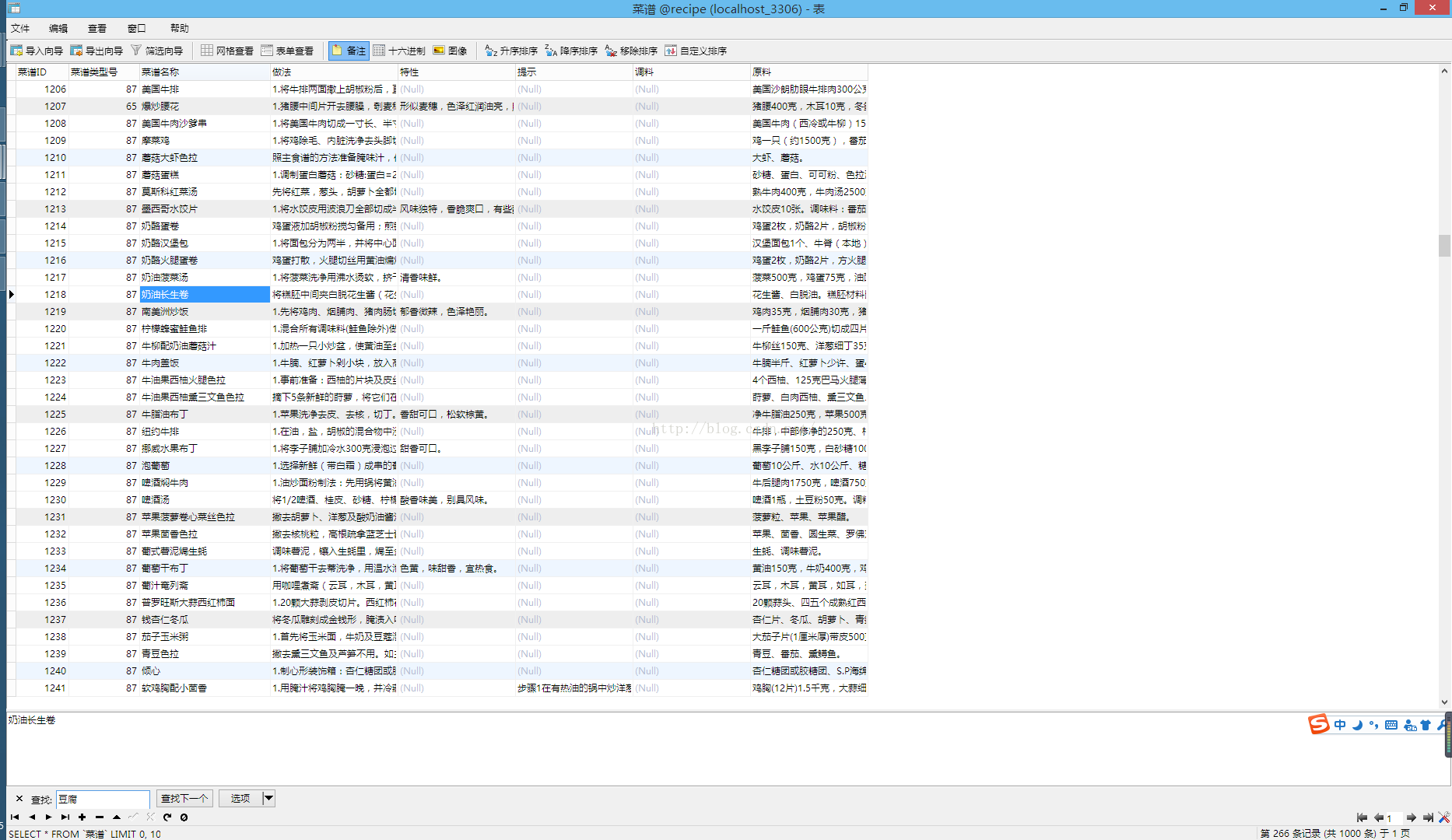
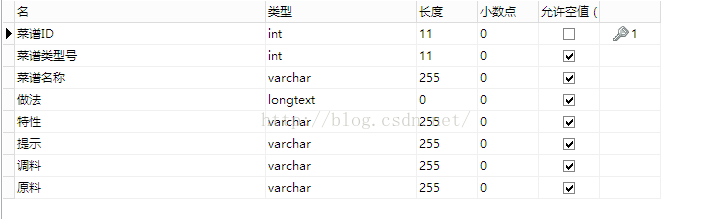
数据格式:
我们先上一个现在达到的最终效果
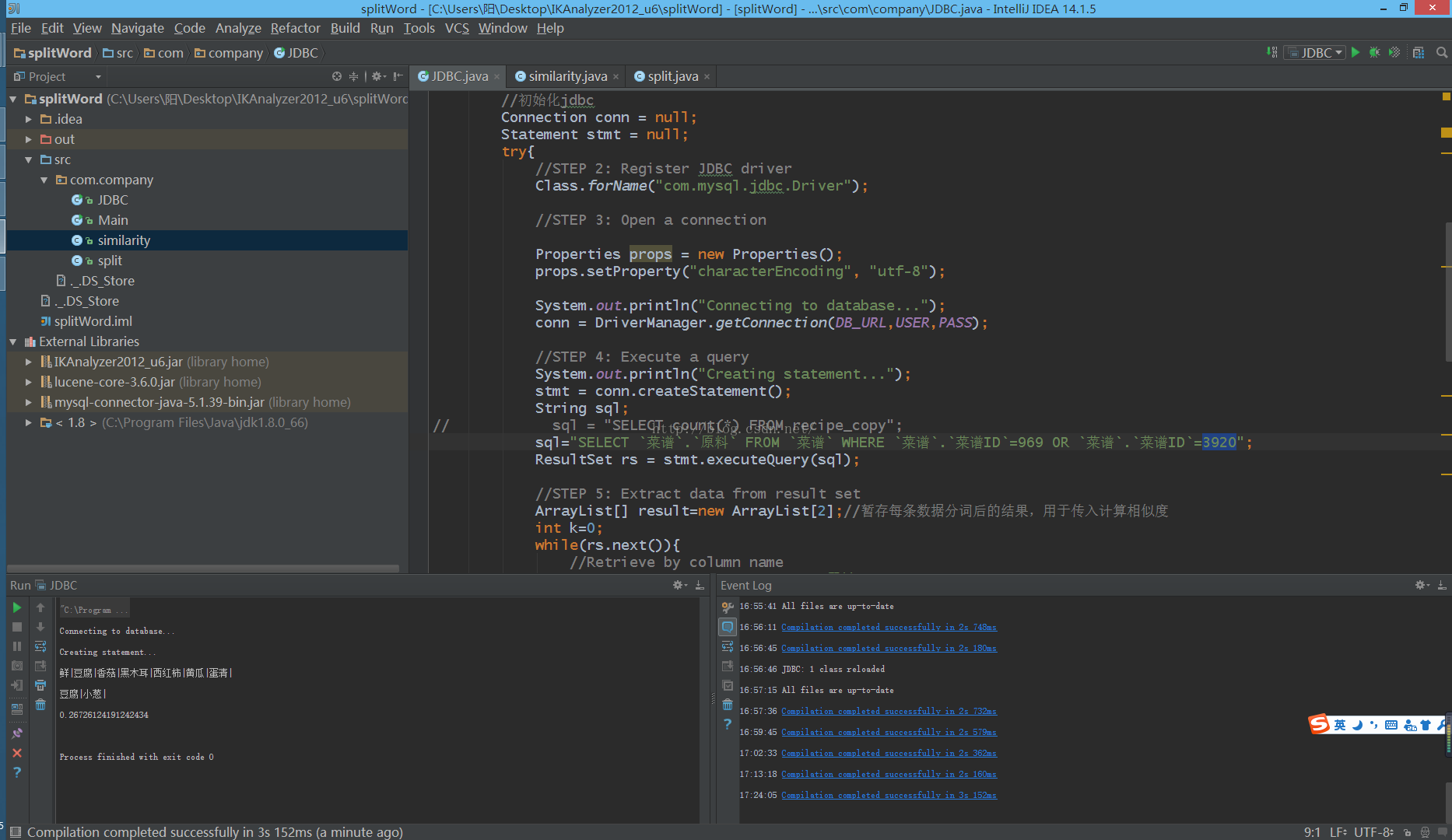
接下来讲如何实现。
首先我设计了三个类,分别是JDBC类用于连接数据库, similarity类用于计算相似度,split类用来完成分词。
先将最重要的部分,similarity类是如何工作的。
我们采用默认的分词方法,随便分一行中的原料列看看效果
菠菜|400克|熟火腿|20克|鸡蛋|50克|海米|20克|熟|冬笋|50克|水|发|冬菇|50克|胡萝卜|50克|
里面有两个方法,getSimilarDegree计算相似度,delUseless是将无用的“50克”这样的删掉。
下面我们举一个实际的例子:
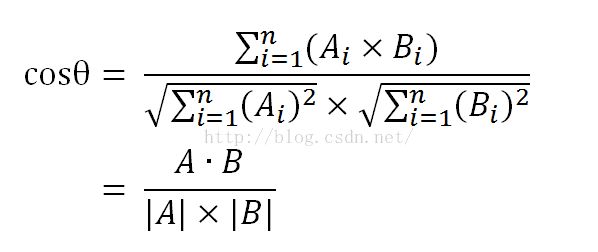
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1732
1732











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









