







 本文介绍了如何使用随机森林模型进行机器学习,以解决Kaggle上的货物销售预测问题。文章详细展示了从数据读取、预处理到模型训练的过程,强调了验证集的重要性。通过分析模型,作者解释了特征重要度的概念,并指出特征工程对模型预测能力的影响。
本文介绍了如何使用随机森林模型进行机器学习,以解决Kaggle上的货物销售预测问题。文章详细展示了从数据读取、预处理到模型训练的过程,强调了验证集的重要性。通过分析模型,作者解释了特征重要度的概念,并指出特征工程对模型预测能力的影响。
Hi,这是我们第三次公开课。之所以有这个分享课程是因为大家太忙(懒),没有时间看fastai在线视频和笔记。而且视频和笔记都是英文的,大家也不想费脑子(懒)。所以本课程的目的就是把Jeremy老师的视频用中文再给大家讲一遍,另外把Hiromi小姐的笔记翻译加工一下分享给大家。
随机森林模型解析
Kaggle
通过机器学习更好地理解数据
这种想法与通常的见解相左,类如随机森林这样的算法是黑盒的、不能窥其实质的。事实恰恰相反,与传统方法相比,随机森林允许我们更深入、更快速地理解数据。
我们这次要探究更大的数据集,利用kaggle的货物销售预测竞赛(Grocery Forecasting),其中包含了超过100万行的数据集。
什么时候使用随机森林?
Jeremy说想不出有什么东西是一点用没有的,总是值得试一试随机森林。所以真正的问题可能是在什么情况下我们还应该尝试其他东西。简单地说,对于非结构化数据(图像、声音等),几乎肯定要使用深度学习;而对于协同过滤模型(杂货竞争就是这种类型),无论是随机森林还是深度学习方法都不是你想要的,你需要做一些调整。
1. 法沃里塔公司货物销售预测(Corporación Favorita Grocery Sales Forecasting)
让我们在处理一个非常大的数据集时,基本上和之前的处理过程相同。但是有一些情况下我们不能使用默认值,因为默认值运行得太慢了。
能够解释你正在处理的问题是很重要的。在机器学习问题中需要理解的关键是:
自变量是什么?
因变量是什么(我们要预测的东西)?
在这个货物销售竞赛中:
因变量——在两周的时间内,每个商店每天销售多少种产品。
自变量——在过去的几年里,每家商店每天卖出多少件产品。对于每个商店,它的位置以及它是什么类型的商店(元数据)。对于每种类型的产品,它是什么类型的产品,等等。对于每个日期,我们都有元数据,例如油价是什么。
这就是我们所说的关系数据集。关系数据集是一种我们可以将许多不同的信息片段连接在一起的数据集。具体来说,这种关系数据集就是我们所说的“星型模式”,其中有一些中央事务表。
在这个竞赛中,中央事务表是train.csv,其包含按日期、store_nbr和item_nbr出售的单位数。我们可以从这里连接各种元数据(因此得名“星型”模式——也称为“雪花”模式)。
1.1 读取数据
types = {
'id': 'int64',
'item_nbr': 'int32',
'store_nbr': 'int8',
'unit_sales': 'float32',
'onpromotion': 'object'}
%time df_all = pd.read_csv(f'../input/train.csv', parse_dates=['date'], dtype=types, infer_datetime_format=True)

- 如果设置
low_memory=False,无论有多少内存,它都会耗尽内存。 - 为了限制在读取时占用的空间,我们为每个列名创建一个字典,对应值为该列的数据类型。通过在数据集上运行
less或head,你将决定采用哪种数据类型。 - 通过这些调整,我们可以在2分钟的时间内读取125,497,040行。
- Python本身并不快,但是我们在数据科学中想要做的几乎所有事情都是用C或者Cython语言写的。在panda中,许多代码是用经过大量优化的汇编语言编写的。在幕后,很多工作都是调用基于Fortran的线性代数库。
指定int64和int是否有性能考虑?
这里的关键是使用尽可能少的位来完全表示列的值。如果我们对item_nbr使用int8,因为item_nbr的最大值大于255,所以这是不合适的。另一方面,如果我们对store_nbr使用int64,那么它使用的bit就比需要的要多。这样考虑的目的就是避免耗尽RAM。当使用大型数据集时,通常会发现性能瓶颈是读写RAM,而不是CPU操作。根据经验来说,较小的数据类型通常运行得更快,特别是如果可以使用单个指令多数据(Single Instruction Multiple Data,SIMD)向量化代码,它可以将更多的数字打包到单个向量中,以便一次运行。
不需要对数据重新洗牌么?
通过使用UNIX命令shuf,可以在命令提示符处获得一个随机的数据样本,然后就可以读取它了。这是一个很好的方法,例如,找出要使用的数据类型——从一个随机样本中读取数据,然后让panda为您计算出来。一般来说,Jeremy会在一个样本上做尽可能多的工作,直到他确信已经理解了这个样本才会继续。
要使用shuf从文件中随机选择一行,请使用-n选项。这将输出限制为指定的数字。你也可以指定输出文件:
shuf -n 5 -o sample_training.csv train.csv
‘onpromotion’: ‘object’——object是一种通用的Python数据类型,速度慢,占内存大。这里使用它因为onpromotion是一个布尔值,而且有缺失值,所以我们需要先处理这个问题,然后才能把它变成布尔值,如下所示:
df_all.onpromotion.fillna(False, inplace=True)
df_all.onpromotion = df_all.onpromotion.map({
'False': False,
'True': True})
df_all.onpromotion = df_all.onpromotion.astype(bool)
fillna(False):在经过检查数据后,我们决定用False填充缺失值。map({'False': False, 'True': True}):object通常以字符串的形式读入,所以用实际的布尔值替换字符串’True’和’False’。astype(bool):最后将其转换为boolean类型。
pandas一般都很快,所以你可以在几十秒内总结出所有1.25亿条记录中的每一列:
%time df_all.describe(include='all')

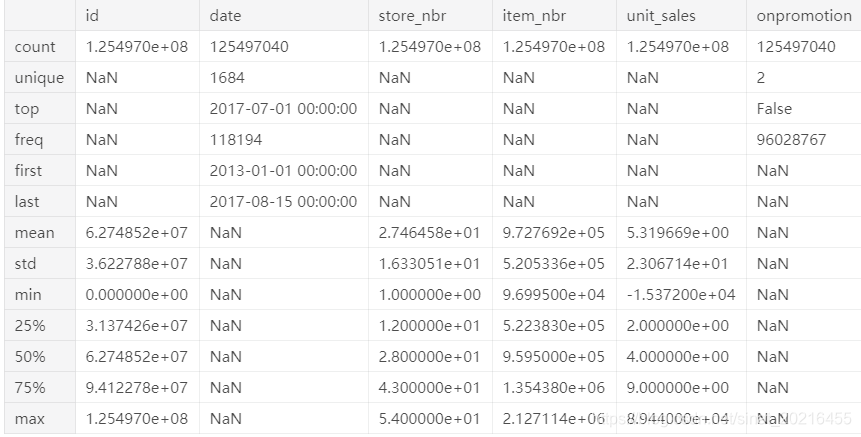
- 先看日期。日期之所以重要,是因为你在实践中使用的任何模型,将会应用到某个日期,而且这个日期要比训练模型用到的日期要晚。如果世界上有任何变化,你也需要知道预测精度是如何变化的。因此,对于Kaggle或你自己的项目,应该始终确保日期不重叠。
- 在这种情况下,使用从2013年到2017年8月训练集数据。
接下来处理测试集。
df_test = pd.read_csv(f'{PATH}test.csv', parse_dates = ['date'],
dtype=types, infer_datetime_format=True)
df_test.onpromotion.fillna(False, inplace=True)
df_test.onpromotion = df_test.onpromotion.map({
'False': False,
'True': True})
df_test.onpromotion = df_test.onpromotion.astype(bool)
df_test.describe(include='all')
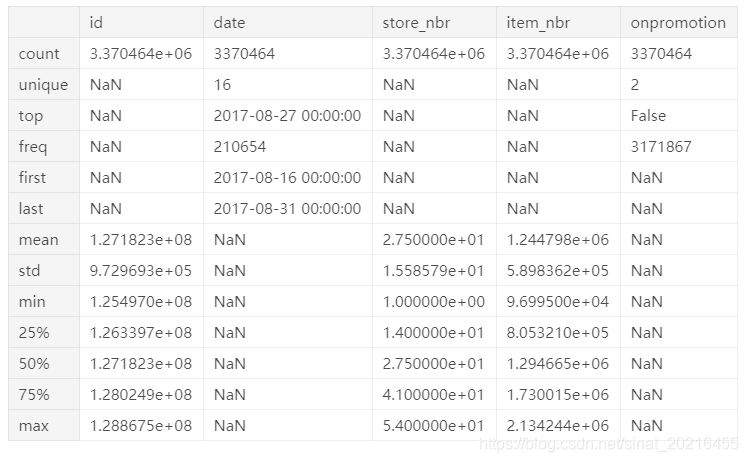
- 这是一个关键问题——在你理解这个基本部分之前,无法做任何有用的机器学习。即你有四年的数据,然后试图预测未来两周的结果。
- 如果你想使用较小的数据集,我们应该使用最近的数据集,而不是随机集。
四年前同样的时间段(比如圣诞节前后)不是很重要吗?
完全正确。这并不是说四年前的信息没用,所以我们不想完全抛弃这些数据。但作为第一步,如果你想提交个均值,你应该不会提交2012年的销售均值,而是可能会提交上个月的销售均值。稍后,我们可能想要更重视最近的日期,因为它们可能更相关。但我们应该做一些探索性的数据分析来验证这一点。
显示最底下的数据,也就是离现在最近的数据。
df_all 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 600
600

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









