






1、为什么用CNN

DNN参数太多,需要更简单的模型。

只看一小块区域。
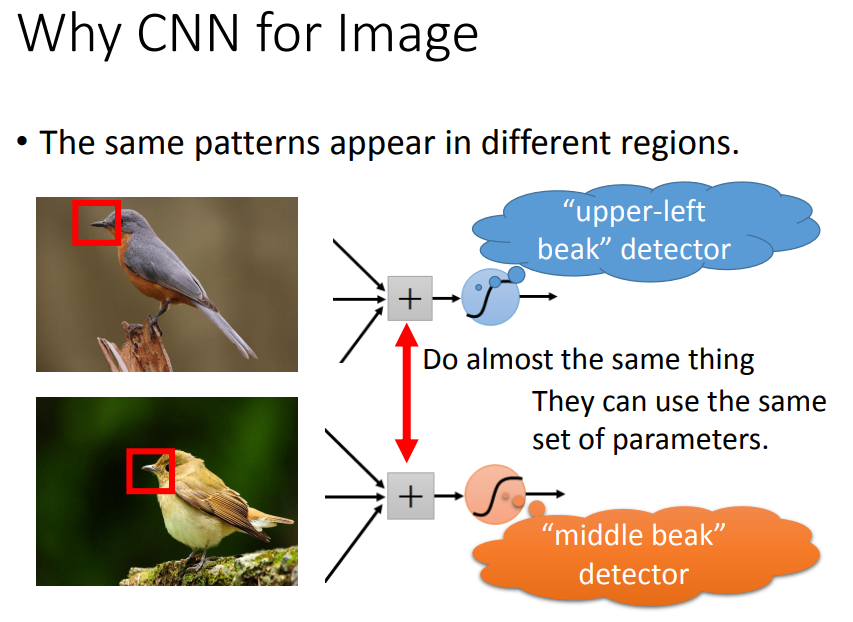
鸟嘴出现在图片的不同位置,但可以共用同一组参数。

做subsampling对影像辨识没有太大影响,可以这样减少参数。
2、CNN结构
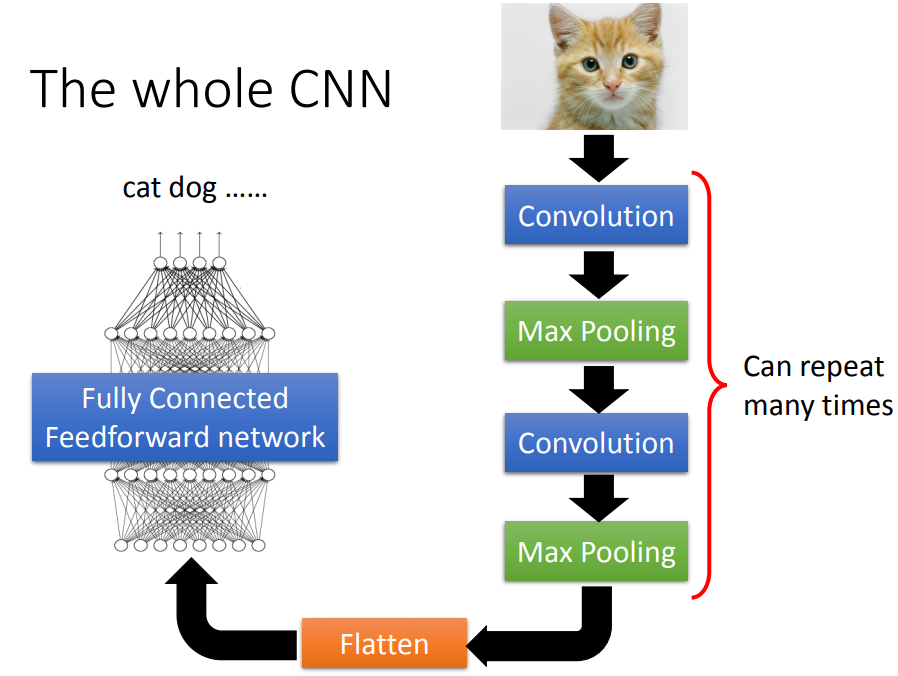

前两点通过卷积来处理,第三点通过池化来处理。
3、卷积
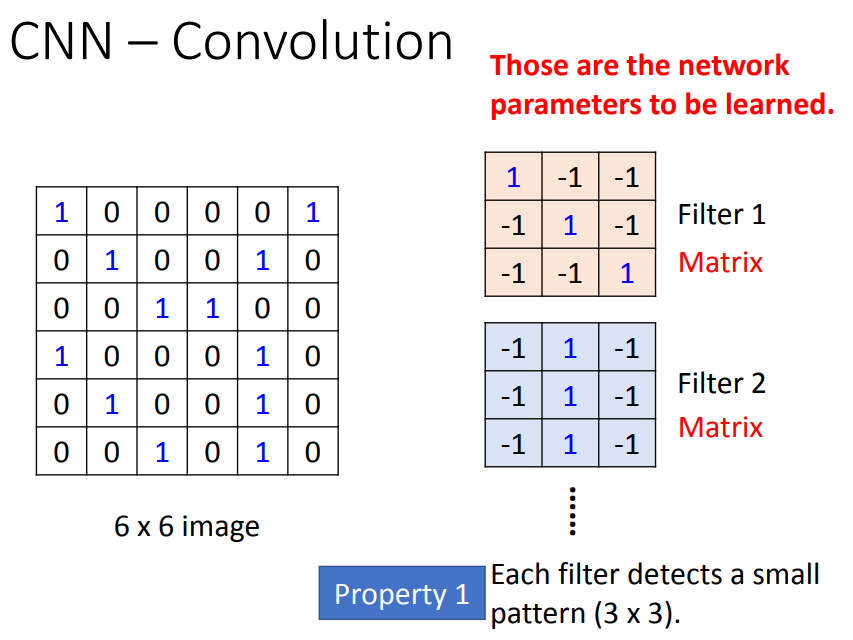
每一个filter里的参数都是被学出来的。


做内积(对应位置相乘再求和)。
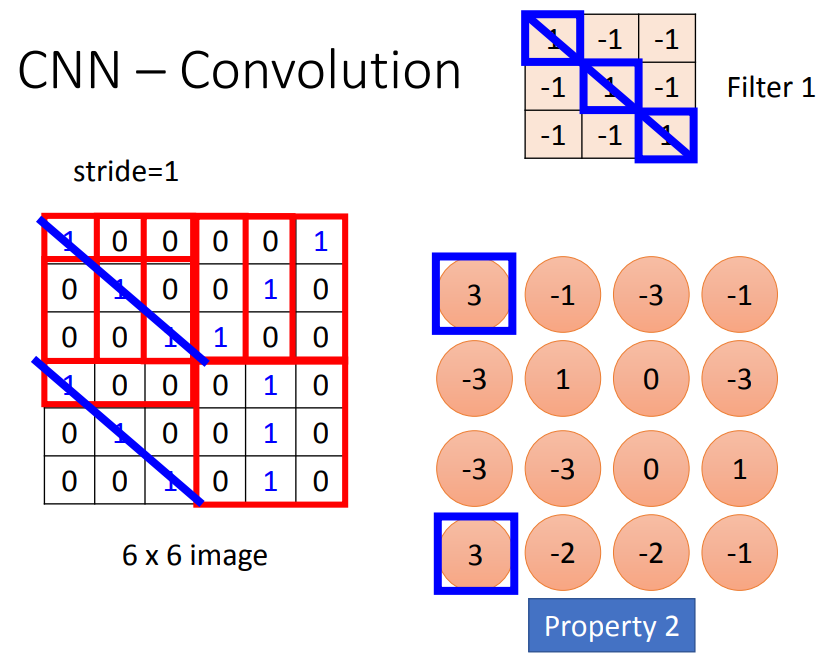
这个filter的工作就是找对角连续出现的111,这样用同一个filter就可以侦测不同位置。

用另一个filter得到另外一个matrix,得到的矩阵叫做feature map,有几个filter就可以得到多少个feature map。

RGB颜色并不是把每个channel分开算,而是多个filter同时算。

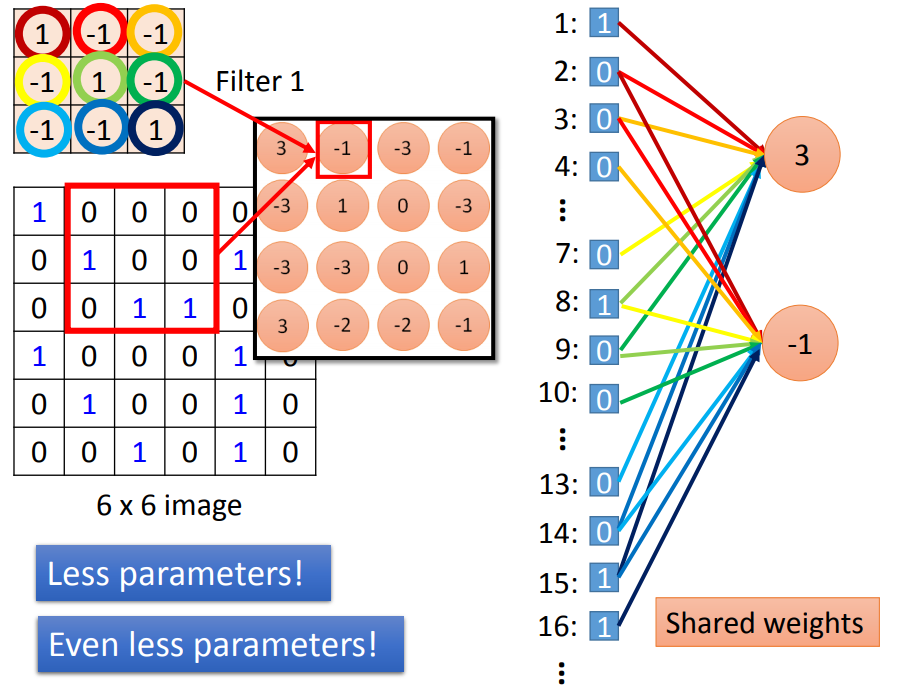
相当于把全连接网络的连接去掉了一些,这样就用到比较少的参数,而且这些参数都是共享的。
4、池化
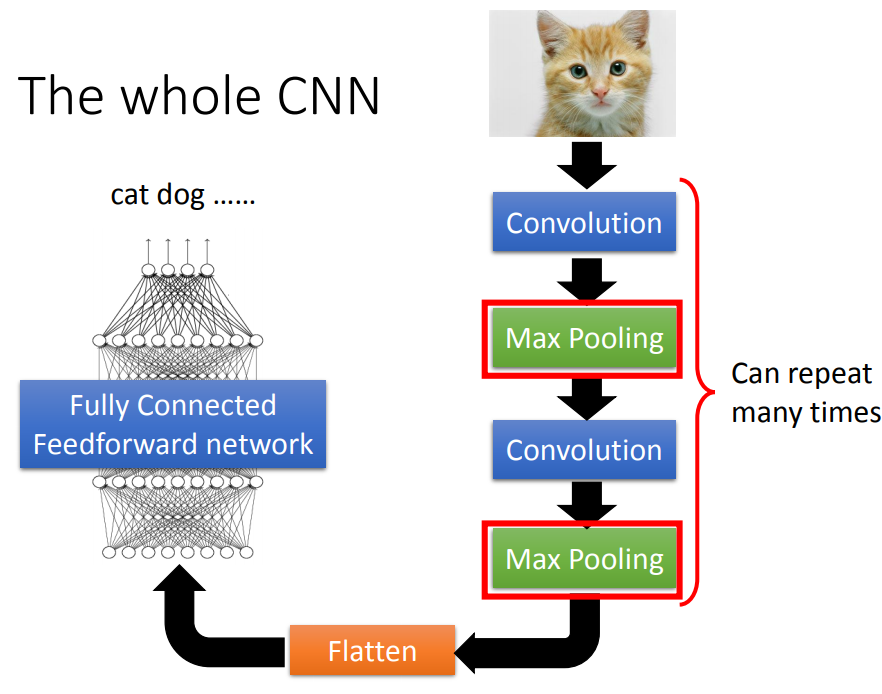

四个一组,可以选最大值也可以选平均值。
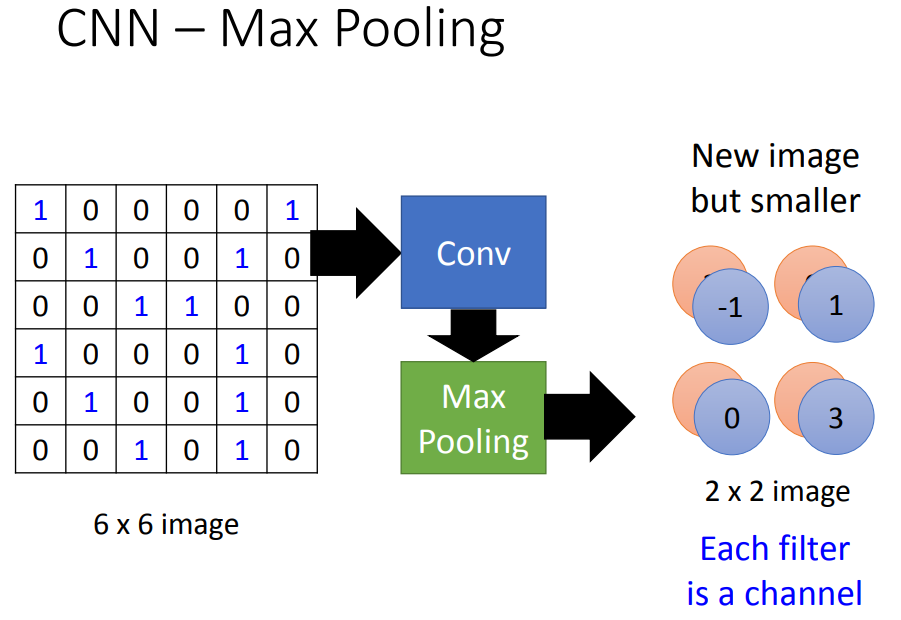

6*6-->2*2,每个像素的深度等于filter的个数。
5、flatten和全连接

6、Keras实现CNN


第二层卷积每个filter的参数个数是3*3*25=225,它是一个立方体。

7、分析CNN学到了什么


第一个卷积层很容易理解,每个filter对应到3*3范围内的9个像素。
第二个卷积层,每个filter的输出是一个11*11的矩阵。
定义第k个filter的activation,表示现在input的东西与第k个filter有多match,把11*11的值相加表示activate的程度。
我们的目的是想要找一张image,可以让第k个filter被activate的程度最大。(使用梯度上升)
我们可以看到在这个例子中想要filter找的是不同角度的密集斜线条。

全连接层每个neural的工作,也是找什么样的image丢到CNN能使这几个neural被最大程度的activate(aj的值最大)。
做了flatten以后每个neural的工作是看整张图,而不是一小块。

同样要使output的值yi最大,对应能使yi最大的图如上。

白色代表有墨水的地方,为了对x做一些限制,减去所有的x绝对值之和。
也就是希望在找出最大的yi同时,希望找出来的x之和越小越好(L1正则化)
8、deepdream的精神
给出一张图片,机器会把它所看到的东西加进去。


拿出一个隐藏层的vector,把filter的值调大(正的更正,负的更负),然后把新的值作为新的图的target(让CNN夸大看到的东西)。


找一张image,同时可以maximize内容和样式的结果。
9、更多应用

全连接网络就可以学。

监督学习(阿法狗还用到了reinforcement learning)
CNN适用的条件如下两点。


根据围棋的特性,不需要池化这样的架构。

在CNN中考虑时间信息没有特别的帮助,所以只考虑频率的方向。
不同的人说同一个音可能只是频率高低,但pattern一样(在image的不同位置而已)。
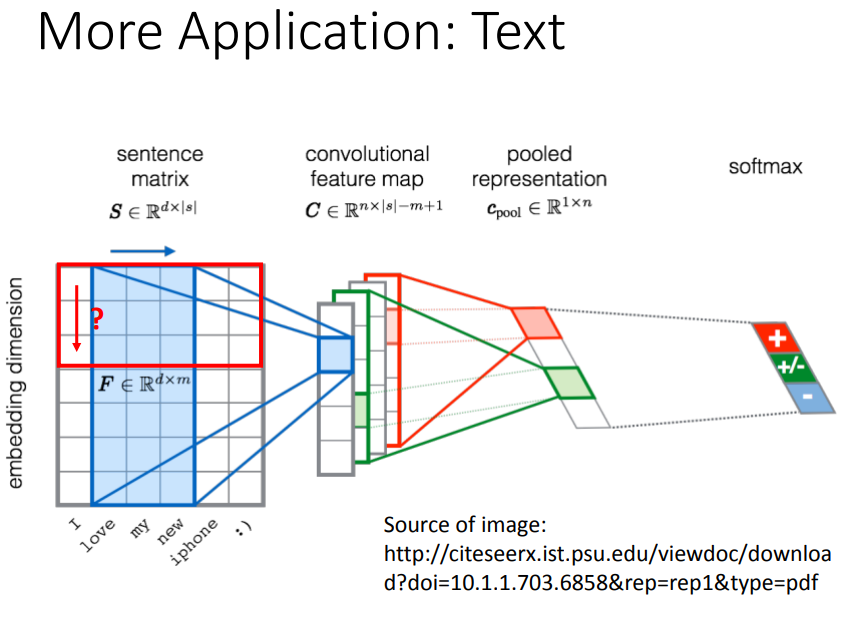
用在文字的情感判别,filter沿着句子顺序来移动(只在时间序列上移动,而不在嵌入维度上移动,因为是独立的没有意义)















 168
168











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









