







目录
3 Seq2Seq + 动态记忆网络DMN(dynamic memory network)模型
4 改进目标函数:最大化互信息 maximum mutual information
5 Seq2Seq + Speaker Embedding(用户画像)模型
Intro
生成式对话系统通常是使用基于深度学习的Encoder-Decoder架构来完成。基于深度学习的技术通常不依赖于特定的答案库或模板,而是依据从大量语料中习得的语言能力来进行对话,根据问题内容直接生成回答的方法被定义为基于某个条件下的生成模型. 深度学习的Seq2Seq技术可以非常好地实现生成模型的框架, 其最诱人的优势就是可以避免人为特征工程的端到端( End-to-End) 框架, 即利用强大的计算和抽象能力自动从海量的数据源中归纳、抽取对解决问题有价值的知识和特征, 使这一过程对于问题的解决者来说透明化, 从而规避人为特征工程所带来的不确定性和繁重的工作量.
改进思路
如果只是单纯的使用基于RNN的Seq2Seq模型来完成生成式对话模型的话,得到的回答往往在逻辑性,正确性或上下文连贯性上都比较一般,因此下面介绍几种改进方法来优化这一问题。

1 Seq2Seq + Context 模型
一般聊天中并不是简单的一问一答,回答时往往要参考上下文聊天信息 Context 的内容, 所以应该把Context引入到 Encoder中,因为这是除了当前输入Message 外的额外信息, 有助于 Decoder 生成更好的会话应答Response内容.很直接的想法是把Context和 Message拼接起来形成一个长的输入提供给Encoder,这样就把上下文信息融入模型中了,但是直接拼接起来形成的输入非常长, 而对于RNN模型来说,输入的线型序列长度越长,模型效果越差。因此后续有paper对这方面做了很多研究,主要改进方法有:
A neural network approach to context-sensitive generation of conversational responses提出在 Encoder 部分采用多层向前神经网络代替RNN模型,这样既能将Context和Message 通过多 层 前 向 神 经 网 络 编 码 成 Encoder-Decoder 模型的中间语义表达,又避免了RNN对于过长输入敏感的问题,下图是文中提到的2种融合方法.


方法 1 对 Context 和 Message 不做明显区分, 直接拼接成一个输入; 而方法 2 则明确区分了 Context和 Message,在前向神经网络的第 1 层分别对其进行编码,拼接结果作为深层网络后续隐层的输入,核心思想是强调 Message 的作用.
2 Seq2Seq + Attention模型
3 Seq2Seq + 动态记忆网络DMN(dynamic memory network)模型
Ask me anything: dynamic memory networks for natural language processing
4 改进目标函数:最大化互信息 maximum mutual information
采用经典的 Encoder-Decoder 模型构建的生成式对话系统比较容易产生“安全回答”问题, 用户不论说什么内容,系统都回答少数非常安全、符合语法但没有实际意义的回答, 比如“I don't know! ”之类. 原因在于传统的Seq2Seq在 Decoding 过程中都是以极大似然估计
法( maximum likelihood estimate, MLE) 为目标函数,公式为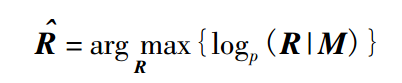
式中: M 为 Message; R 为 Response,即生成最符合语法的话,而不是最有用的话,这些安全的句子大量地出现在训练语料中,模型学习了之后,无可避免地总是生成这样的Response.
互信息目标函数为:
可以从公式差异中看出,MMI 的优化目标除了最大化从 Message 生成应答 Response 的概率,同时加入了反向优化目标, 即最大化应答 Response 产生Message 的概率,其中 λ 是控制两者哪个更重要的调节超参数。通过具体公式可以看出, 这个优化目标函数要求应答 Response 和 Message 内容密切相关而不仅考虑哪个 Response 以更高概率出现,所以降低了那些非常常见的回答的生成概率,使得应答Response更多样化且跟 Message 语义更加相关
5 Seq2Seq + Speaker Embedding(用户画像)模型
模型中考虑个性化信息( 比如背景信息、用户画像、年龄等) , 构建出一个个性化Sequence-to-Sequence 模型,称为 Speaker Model,为不同的用户,以及同一个用户对不同的对象自然语言生成不同风格的Response,架构如下图所示.
















 2034
2034











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









