






在 Object Detection API 的示例代码中包含了一个训练识别宠物的 Demo,包括数据集和相应的一些代码。虽然本课程中我们会自己准备数据和脚本来进行训练,但是在这之前还需要安装一些库、配置一下环境。在配置完成之后,运行一下这个训练宠物的 Demo,以便检查环境配置是否 OK,同时对训练过程先有个整体的了解,然后再准备自己的数据和训练脚本。
安装 Object Detection API
首先下载 Object Detection API 的代码:
git clone https://github.com/tensorflow/models.git(建议下载压缩包,更快)
安装tensorflow-gpu,教程可看官方文档:https://www.tensorflow.org/install/pip
gpu支持:https://www.tensorflow.org/install/gpu
接着是一些依赖库
pip install pillow
pip install lxml
pip install jupyter
pip install matplotlib
pip install contextlib2
Object Detection API 中的模型和训练参数是使用 protobuf 来序列化和反序列化的,所以在运行之前需要将相应的 protobuf 文件编译出来。
#进入 /models/research/
protoc object_detection/protos/*.proto --python_out=.
成功编译以后可以在 object_detection/protos/ 下找到生成 .py 文件。
注意这里可能需要安装protobuf-compiler,直接sudo apt-get只能得到2.6.1,故可上github上下载压缩包。
到 https://github.com/google/protobuf/releases 下载最新的protoc安装包 protobuf-all-3.x.x.tar.gz
下载完后解压,然后执行下面的命令编译安装:
$ cd protobuf-3.6.1
$ ./configure --prefix=/usr
$ make -j15
$ make check -j15
$ sudo make install -j15
$ sudo ldconfig
接下来将 Object Detection API 的库加入到 PYTHONPATH 中:
#进入 models/research/
打开环境变量:
sudo gedit ~/.bashrc
添加命令:
export PYTHONPATH=$PYTHONPATH:/home/turing/software/models/research:/home/turing/software/models/research/slim
下载数据集
数据集由图片和相应的标注文件组成:
wget http://www.robots.ox.ac.uk/~vgg/data/pets/data/images.tar.gz
wget http://www.robots.ox.ac.uk/~vgg/data/pets/data/annotations.tar.gz
tar -xvf annotations.tar.gz
tar -xvf images.tar.gz
在 images 目录就是一些宠物的照片,而在 annotations 文件夹里面是对相应照片的标注,在 annotations 文件夹中的和 images 文件夹中照片文件名一致的 xml 文件就是标注文件,这些标注文件为 PASCAL VOC 格式,可以打开 Abyssinian_1.xml看一下:
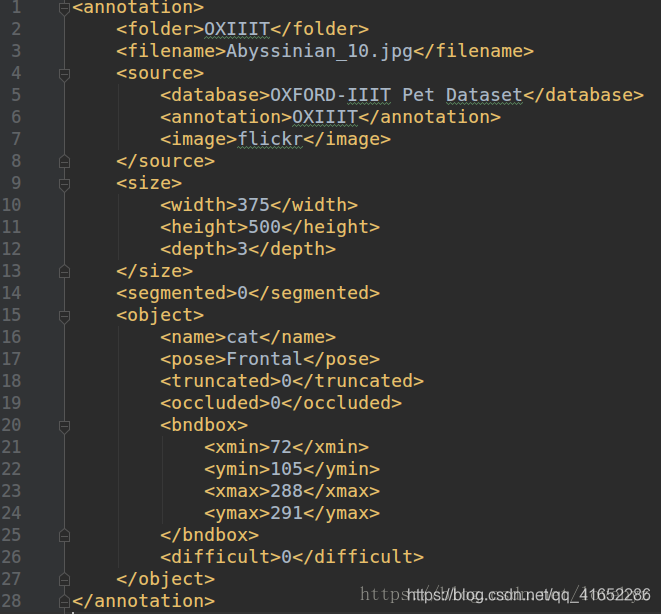
标注内容主要为图片的源信息,如高和宽、物体的名称及所在位置:(xmin、ymin、xmax、ymax)所标识的矩形框。
还记得需要一个物体类别的数字编号和物体类别实际名称的对应关系的文件吗?可以在这里找到:
object_detection/data/pet_label_map.pbtxt
把它移到pet_dataset文件夹下
文件内容看起来是这样的:
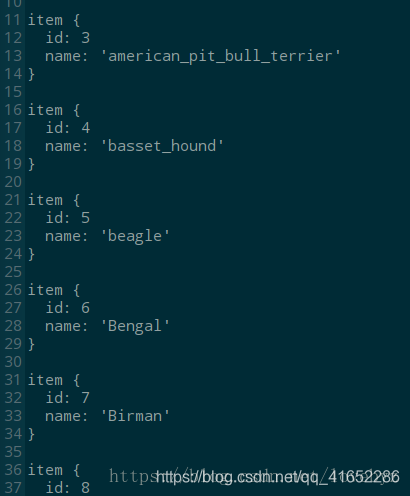
注意:所有物体类别的数字编号都是从 1 开始的,因为 0 是一个在数学计算中很特殊的值。
生成 TFRecord 文件
Object Detection API 的训练框架使用 TFRecord 格式的文件作为输入。所以这里需要将图片和标注转换为 TFRecord 格式的文件。
TFRecord 数据文件是一种将图像数据和标签统一存储的二进制文件,能更好的利用内存,在 TensorFlow 中快速的复制、移动、读取、存储等。
Demo 里面包含了生成对应 TFRecord 格式文件的脚本,运行:
进入 models/research/
python object_detection/dataset_tools/create_pet_tf_record.py \
--label_map_path=object_detection/data/pet_label_map.pbtxt \
--data_dir=/media/turing/data/DATA/pet_dataset \
--output_dir=/media/turing/data/DATA/pet_dataset/output
这里需要将 DATA_DIR 替换为 images 和 annotations 所在的文件夹(父文件夹)
pet_train.record 为训练集,pet_val.record 为测试集。
准备转移学习
还需要一个 Pre-trained 模型来进行转移学习,尽量的缩短学习的时间,预训练模型文件可在这里下载所需要的:https://github.com/tensorflow/models/blob/master/research/object_detection/g3doc/detection_model_zoo.md
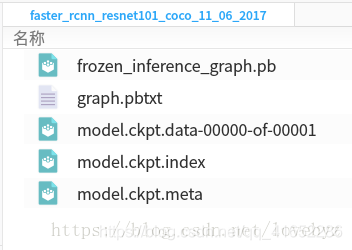
在转移学习中要用的文件是 model.ckpt.* 这三个文件。
准备配置文件
还需要一个配置文件来对训练的流程进行配置,如使用什么算法,选用什么优化器等。在 object_detection/samples/configs/ 可以找到很多配置模板,在这里使用 object_detection/samples/configs/ssd_mobilenet_v1_pets.config 作为起始的配置文件,需要在这个模板上面稍作修改。
这个配置文件是一个 JSON 格式的文件,里面有很多配置项,先挑一些必须修改的或者重要的项目:
train_input_reader: {
tf_record_input_reader {
input_path: "/media/turing/data/DATA/pet_dataset/output/pet_faces_train.record-?????-of-00010"
}
label_map_path: "/media/turing/data/DATA/pet_dataset/pet_label_map.pbtxt"
}
eval_input_reader: {
tf_record_input_reader {
input_path: "/media/turing/data/DATA/pet_dataset/output/pet_faces_val.record-?????-of-00010"
}
label_map_path: "/media/turing/data/DATA/pet_dataset/pet_label_map.pbtxt"
shuffle: false
num_readers: 1
}
需要将PATH_OF_TRAIN_TFRECORD替换为pet_train.record的绝对路径,将PATH_OF_LABEL_MAP替换为pet_label_map.pbtxt的绝对路径。
需要将PATH_OF_VAL_TFRECORD替换为pet_val.record的绝对路径,将PATH_OF_LABEL_MAP替换为pet_label_map.pbtxt的绝对路径:
train_config: {
}
fine_tune_checkpoint: "CHECK_POINT_PATH" <--("/media/turing/data/DATA/pet_dataset/faster_rcnn_resnet101_coco_2018_01_28/model.ckpt"
from_detection_checkpoint: true
num_steps: 200000
如果将from_detection_checkpoint设为true的话,代表将从一个事先训练好的模型开始继续训练(转移学习),此时需要将CHECK_POINT_PATH替换为 model.ckpt 的绝对路径(注意之前有三个文件,model.ckpt.index、model.ckpt.meta、model.ckpt.data-xxx 在配置时不需要加model.ckpt 之后的后缀),如:fine_tune_checkpoint: “/media/turing/data/DATA/pet_dataset/faster_rcnn_resnet101_coco_2018_01_28/model.ckpt”
num_steps 为训练迭代的步数,这里暂时不修改。
将改好以后的配置文件重命名为 pipeline.config。
开始训练
准备好训练数据和配置文件以后,就可以开始进行训练了。通常会把训练会用到的文件放到一起(训练目录).
然后执行训练脚本:
# 进入 tensorflow/models/research/
python object_detection/train.py \
--logtostderr \
--pipeline_config_path=${TRAIN_DIR}/model/pipeline.config} \
--train_dir=${TRAIN_DIR}/model/train
本人配置如下:
python object_detection/model_main.py \
--logtostderr \
--pipeline_config_path=/media/turing/data/DATA/pet_dataset/pipeline.config \
--model_dir=/media/turing/data/DATA/pet_dataset/train \
--num_train_steps=5000 \
--num_eval_steps=2000
模型开始训练,可以在终端上看到以下输出:
每一行输出为:训练迭代步数/当前损失值/每步训练所花时间。
本人代码运行如下:
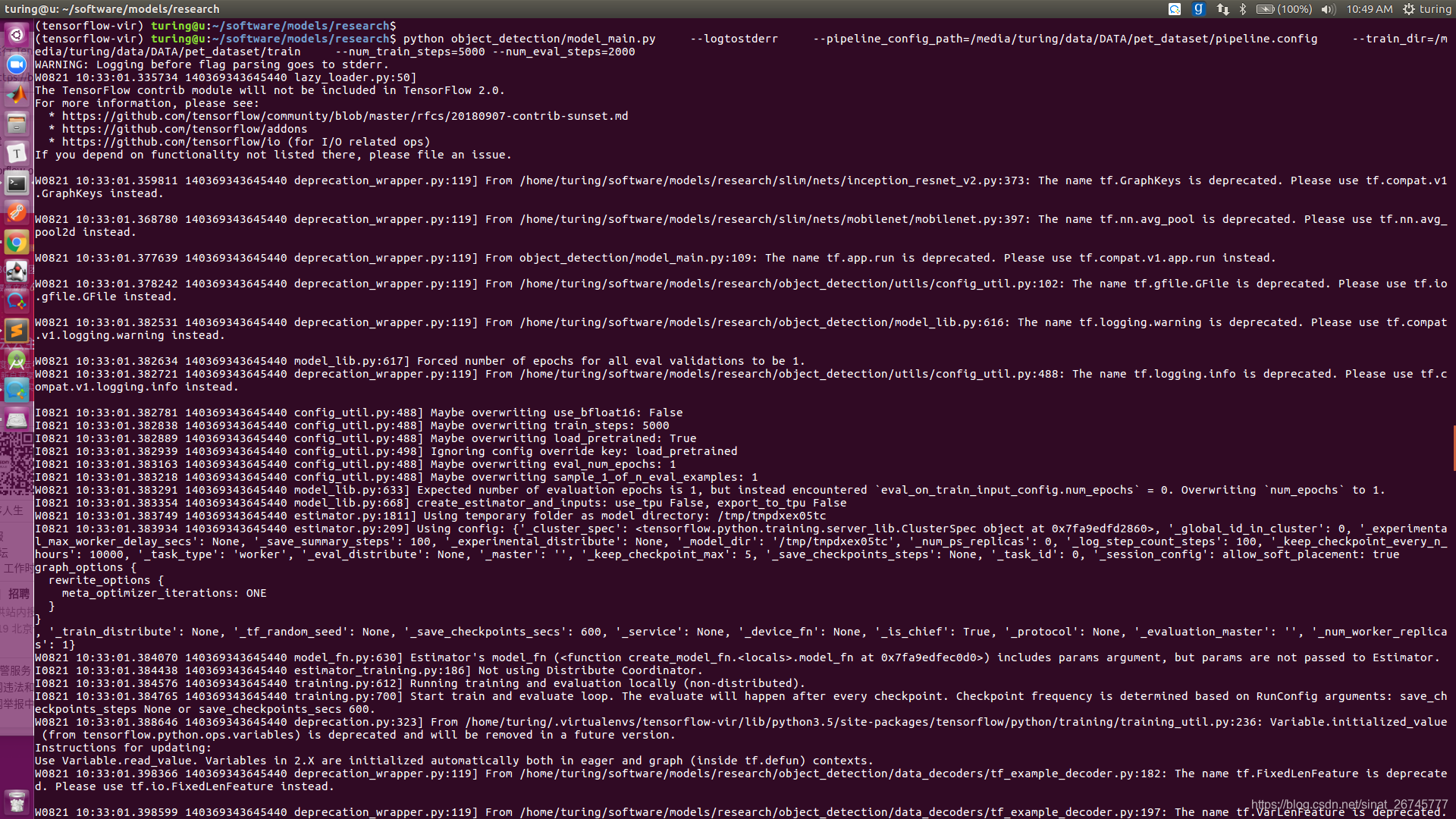
运行中途是这样的:
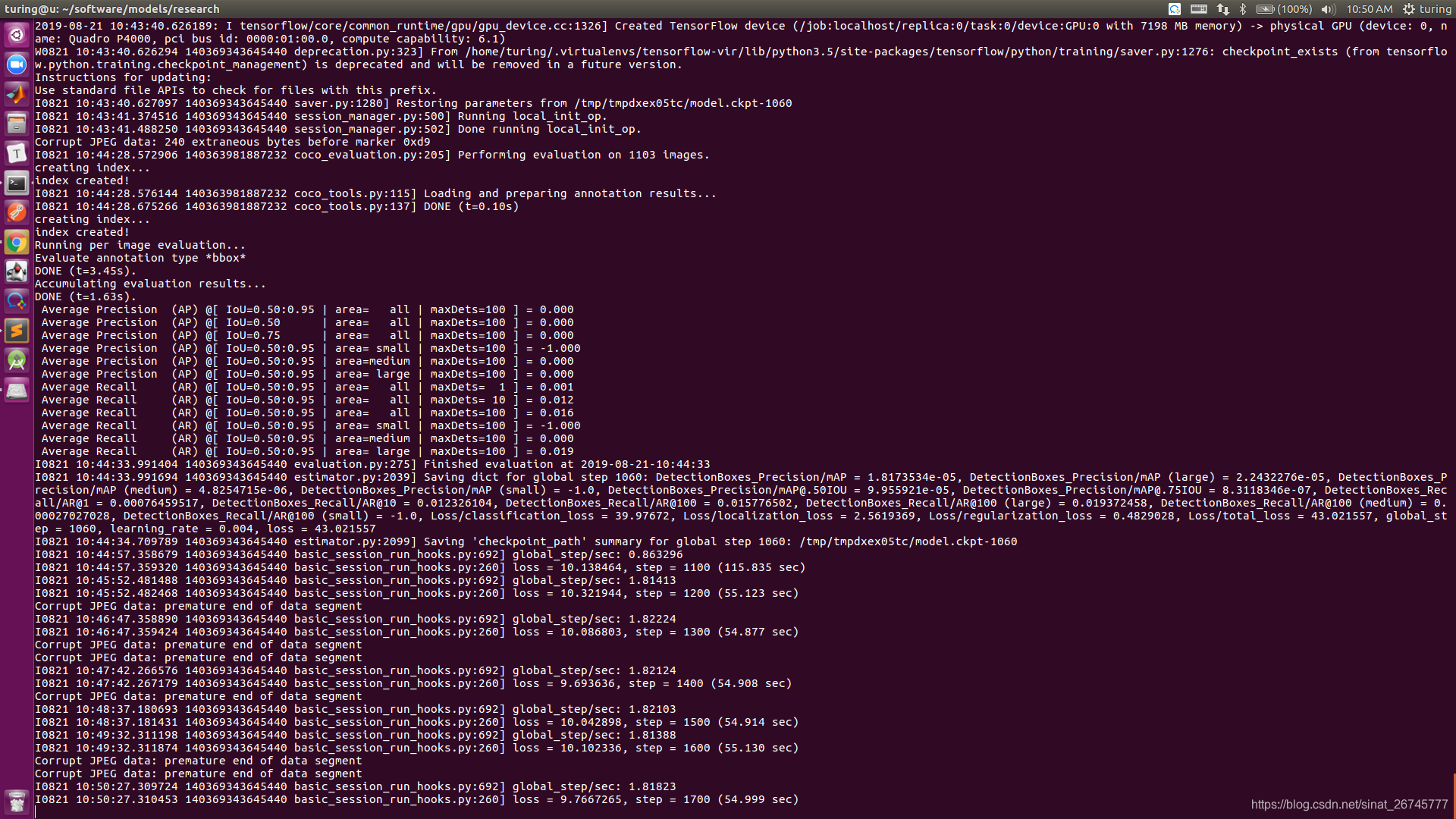
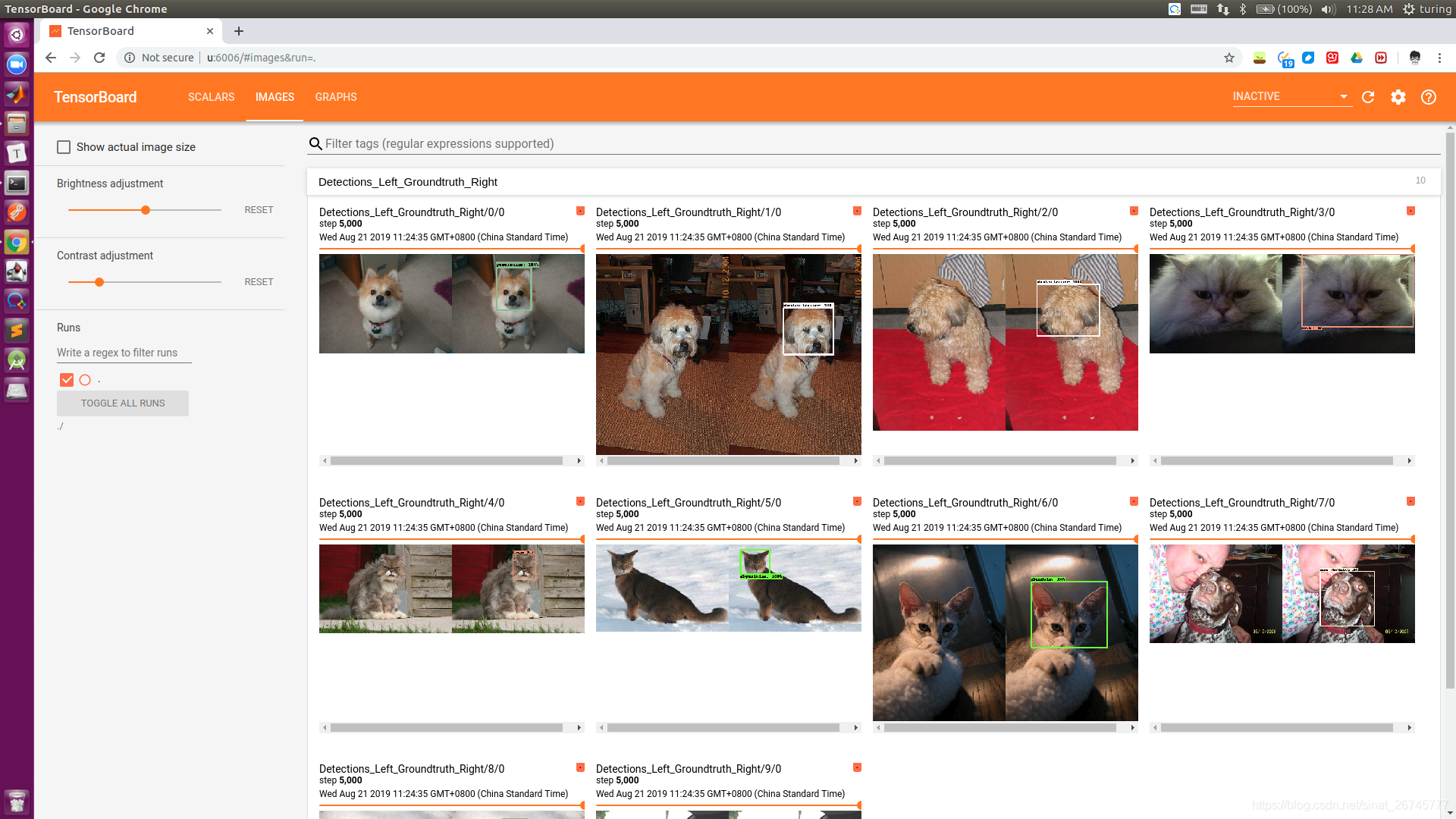
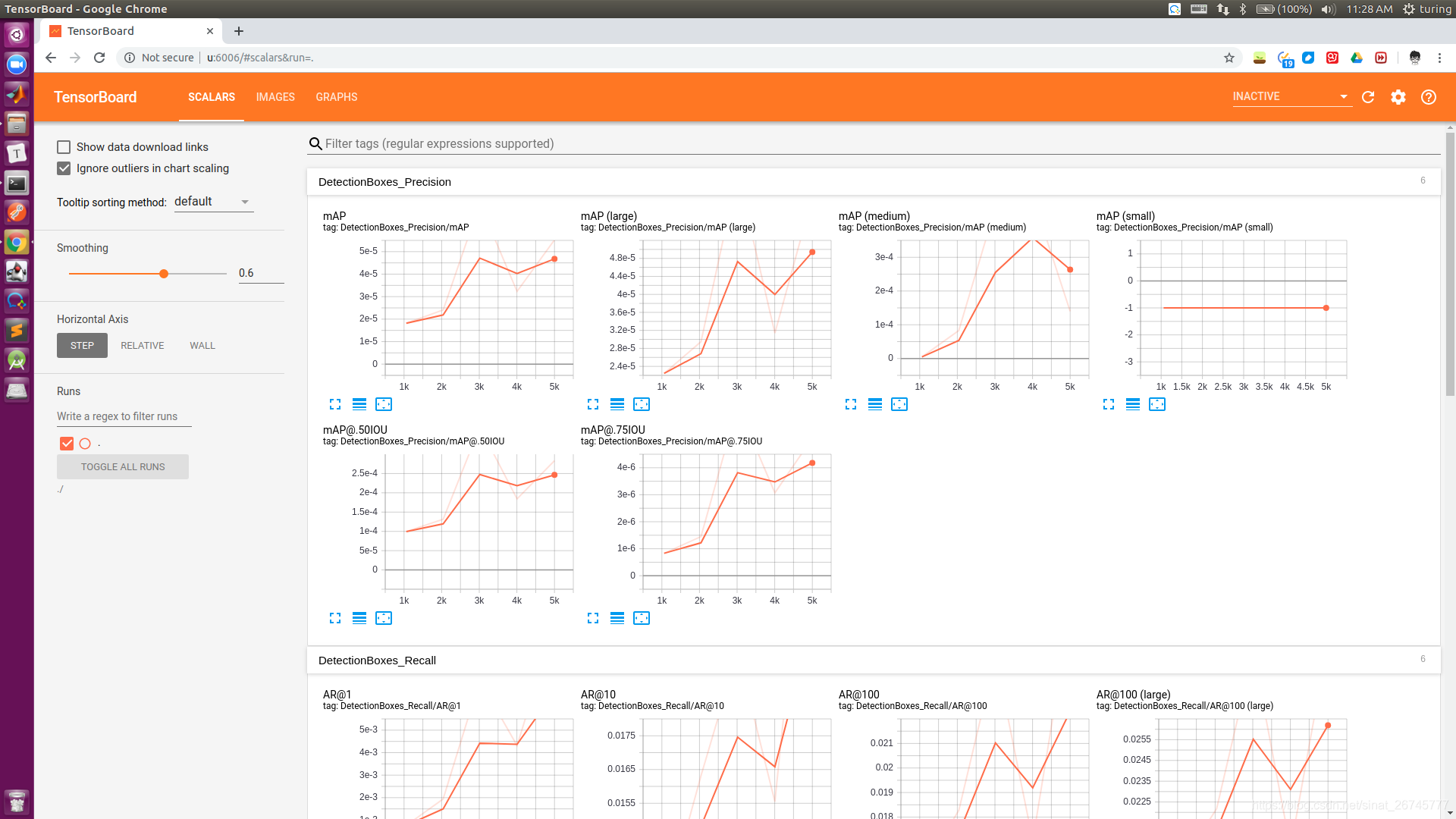
啊啊啊,哈哈哈哈,代码跑60多个小时就大功告成了....














 234
234











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









