







一、数组(列表) -- 在定义时需要指定长度和数组的类型 -- 数组是值类型(数组作为实参时,修改数组的值,原数组的值不会改变【如果想要改变原数据的值,那么实参就必须是数组的指针】)
1.1、数组的定义
数组是存放元素的容器,必须指定存放元素的类型和长度,数组的长度是数组类型的一部分。
数组是同一种数据类型元素的集合。 在Go语言中,数组从声明时就确定,使用时可以修改数组成员,但是数组大小不可变化。
数据的地址可以通过数组名来获取:&数组变量名
数组定义:var 数组变量名 [元素数量] 元素TYPE
数组可以通过下标(索引)进行访问,类似Python的列表索引取值一样。
var a [5]int
var a [10]int
[5]int 和 [10]int 是不同的类型。
数组的长度必须是常量,并且数组的长度是数组类型的一部分。一旦定义,长度不能变。
var a [3]int
var b [4]int
a = b 这里不能做赋值操作,因为此时a和b是不同的类型。数组在创建时,如果没有赋值,会有默认值:
数组是int类型,默认值是:0
数组是string类型,默认值是:""
数组是bool类型,默认值是:false
1.2、数组的初始化 (数组的赋值)
方法一:初始化数组时可以使用初始化列表来设置数组元素的值。
func main() { var testlist [3]int fmt.Println(testlist) // 数组未赋值时,默认的索引值为0:[0 0 0] // 依次给数组的索引赋值 testlist[0] = 1 testlist[1] = 2 testlist[2] = 3 fmt.Println(testlist) // [1 2 3] // 不能定义空数组,因为数组必须要设置长度(不设置长度的是分片),不同的类型都会有默认值 // 2个长度一样的数组,可以直接赋值 var a = [3]int{1,2,3} var b = a fmt.Println(a) // [1 2 3] fmt.Println(b) // [1 2 3] // 2个长度不一样的数组赋值 a := [5]int{10,20,30,40,50} var b [6]int // 把数组a所有的值,循环赋值给数组b for i:=0;i<len(a);i++ { b[i]=a[i] } fmt.Println(a) // [10 20 30 40 50],数组a的值 fmt.Println(b) // [10 20 30 40 50 0],数组b的值,因为长度多1位,默认用0填充 }方法二:按照上面的方法每次都要确保提供的初始值和数组长度一致,一般情况下我们可以让编译器根据初始值的个数自行推断数组的长度,例如:
func main() { var testArray [1]int var numArray = [...]int{1, 2} var cityArray = [...]string{"北京", "上海", "深圳"} fmt.Println(testArray) //[0] fmt.Println(numArray) //[1 2] fmt.Println(cityArray) //[北京 上海 深圳] // 打印数组的类型 fmt.Printf("type of numArray: %T\n", numArray) //type of numArray: [2]int fmt.Printf("type of cityArray: %T\n", cityArray) //type of cityArray: [3]string }方法三:我们还可以使用指定索引值的方式来初始化数组,例如:
func main() { // 设置索引1的值为1,索引3的值为5 a := [...]int{1: 1, 3: 5} fmt.Println(a) // [0 1 0 5] fmt.Printf("type of a:%T\n", a) //type of a:[4]int }1.3、数组的遍历
func main() { // 方式一:类似python的索引取值 a := [...]string{"北", "上", "广", "深"} for i := 0; i < len(a); i += 1 { println(a[i]) } //北 //上 //广 //深 // 方法二:for + range循环取值 for i, v := range a { fmt.Println(i, v) } //0 北 //1 上 //2 广 //3 深 }1.4、数组的注意事项
值拷贝(不会改变数组原本的值)
func test(arr [3]int) { arr[0] = 88 } func main() { arr := [3]int{1,2,3} test(arr) fmt.Println("main",arr) // 返回值:main [1 2 3] }指针拷贝(会改变数组原本的值)
func test(arr *[3]int) { arr[0] = 88 } func main() { arr := [3]int{1,2,3} test(&arr) fmt.Println("main",arr) // 返回值:main [88 2 3] }1.5、二维数组
Go语言是支持多维数组的,我们这里以二维数组为例(数组中又嵌套数组)
1、二维数组的定义
语法:var 数组名 [大小][大小]Type
func main() { // [[北京 上海] [广州 深圳] [成都 重庆]] // [3] 表示最外层列表内值的数量 // [2] 表示内层列表内值的数量 a := [3][2]string{ {"北京", "上海"}, {"广州", "深圳"}, {"成都", "重庆"}, } // 可以理解为列表内套用列表 fmt.Println(a) //[[北京 上海] [广州 深圳] [成都 重庆]] fmt.Println(a[2]) //支持索引取值: [成都 重庆] fmt.Println(a[2][1]) //支持索引取值: 重庆 // 延伸的列表内在套用2层列表的写法 b := [3][2][2]string{ {{"aa", "bb"}, {"cc", "dd"}}, {{"AA", "BB"}, {"CC", "DD"}}, {{"11", "22"}, {"33", "44"}}, } fmt.Println(b) // [[[aa bb] [cc dd]] [[AA BB] [CC DD]] [[11 22] [33 44]]] fmt.Println(b[2]) // [[11 22] [33 44]] fmt.Println(b[2][1]) //[33 44] }2、二维数组的遍历
func main() { a := [3][2]string{ {"北京", "上海"}, {"广州", "深圳"}, {"成都", "重庆"}, } for _, v1 := range a { for _, v2 := range v1 { fmt.Println(v2) //北京 //上海 //广州 //深圳 //成都 } } }注意: 多维数组只有第一层可以使用...来让编译器推导数组长度。例如:
//支持的写法 a := [...][2]string{ {"北京", "上海"}, {"广州", "深圳"}, {"成都", "重庆"}, } //不支持多维数组的内层使用... b := [3][...]string{ {"北京", "上海"}, {"广州", "深圳"}, {"成都", "重庆"}, }3、二位数组案例
func main() { var arrint = [...][5]int{ {1,2,3,4,5}, {2,3,4,5,6}, {3,4,5,6,7}, {4,5,6,7,8}, {5,6,7,8,9}, } for i:=0;i<len(arrint);i++ { res :=0 for j:=0;j<len(arrint[i]);j++{ res+=arrint[i][j] } fmt.Printf("数组%v的和为:%v\n",arrint[i],res) //数组[1 2 3 4 5]的和为:15 //数组[2 3 4 5 6]的和为:20 //数组[3 4 5 6 7]的和为:25 //数组[4 5 6 7 8]的和为:30 //数组[5 6 7 8 9]的和为:35 avg := res/len(arrint[i]) fmt.Printf("数组%v的平均值为:%v\n",arrint[i],avg) //数组[1 2 3 4 5]的平均值为:3 //数组[2 3 4 5 6]的平均值为:4 //数组[3 4 5 6 7]的平均值为:5 //数组[4 5 6 7 8]的平均值为:6 //数组[5 6 7 8 9]的平均值为:7 } }4、二维切片内通过 append() 传值
func main() { // Step 1: 创建一个空的二位切片 values := [][]int{} // Step 2: 使用 appped() 函数向空的二维切片添加两行一维切片 row1 := []int{1, 2, 3} row2 := []int{4, 5, 6} values = append(values, row1) values = append(values, row2) fmt.Println(values) // [[1 2 3] [4 5 6]] // Step 3: 显示两行数据 fmt.Println("Row 1") fmt.Println(values[0]) fmt.Println("Row 2") fmt.Println(values[1]) // Step 4: 访问二维切片的第一个元素里面的第一个值 fmt.Println("第一个元素为:") fmt.Println(values[0][0]) }1.6、数组的练习题
1.求数组[1, 3, 5, 7, 8]所有元素的和
func main() { //求数组[1, 3, 5, 7, 8]所有元素的和 a_list := [...]int{1, 3, 5, 7, 8} sum := 0 for _, v := range a_list { sum += v } fmt.Println(sum) } // 求和以及求平均值 func main() { var intarr = [4]int{1,2,3,4} res := 0 for i:=0;i<len(intarr);i++{ res += intarr[i] } fmt.Println("求和",res) // 求和 10 fmt.Println("平均值",float64(res)/float64(len(intarr))) // 平均值 2.5 }2.从数组[1, 3, 5, 7, 8]中随机找2个数字相加的和为8的数字,并列出该数字的索引
func main() { //从数组[1, 3, 5, 7, 8]中随机找2个数字相加的和为8的数字,并列出该数字的索引,答案:(0,3)和(1,2)索引的值相加都等于8。 // 算法: // 先把第1个数字列出来,依次和后4个数相加当相加的和为8时,列出该数字的索引值。 // 然后第2个和后3位依次相加,第3个和后2位依次相加,第4个和后1位依次相加 b_list := [...]int{1, 3, 5, 7, 8} // 先把第1个数字列出来 for i := 0; i < len(b_list); i += 1 { // 依次和后4个数相加 for j := i; j < len(b_list); j += 1 { //当相加的和为8时,列出该数字的索引值。 if b_list[i]+b_list[j] == 8 { fmt.Printf("(%v,%v)", i, j) } } } }1.7、数组的排序和查找
1.7.1、什么是排序?
内部排序:将所需要处理的所有数据都加载到内部存储器中进行排序,包括(交换式排序法,选择式排序法和插入式排序法)
外部排序:数据量大,无法全部加载到内存,需要借助外部存储进行排序,包括(合并排序法和直接合并排序法)
1.7.2、冒泡排序(从小到大排序)
规则:让前面的数和后面的数进行比较,如果前面的数大,则前后数的位置交换。
规律:
数组有N个数据,会进行N-1轮次比较,每一轮次将会确定一个数的位置;
每"轮次"的"比较次数"会"逐渐减少"。
冒泡排序案例,以数组 [24 69 80 57 13] 为例:
第一轮排序 第1次比较(24和69比较):[24 69 80 57 13] 第2次比较(69和80比较):[24 69 80 57 13] 第3次比较(80和57比较):[24 69 57 80 13] 第4次比较(80和13比较):[24 69 57 13 "80"] // 80最大 第二轮排序 第1次比较(24和69比较):[24 69 57 13 80] 第2次比较(69和57比较):[24 57 69 13 80] 第3次比较(69和13比较):[24 57 13 "69 80"] // 80最大69其次 第三轮排序 第1次比较(24和57比较):[24 57 13 69 80] 第2次比较(57和13比较):[24 13 “57 69 80”] // 80最大69其次57再其次 第四轮排序 第1次比较(24和13比较):[“13 24 57 69 80”] // 从小到大排序完成冒泡排序的代码实现:
func test(arrint *[5]int) { fmt.Println("排序前:",*arrint) // 排序前: [24 69 80 57 13] temp := 0 // 第一轮排序 for j :=0;j<len(*arrint)-1;j++{ for i:=0;i<len(*arrint)-1-j;i++ { if (*arrint)[i] > (*arrint)[i+1] { temp = (*arrint)[i] (*arrint)[i] = (*arrint)[i+1] (*arrint)[i+1] = temp } } fmt.Println("每轮排序后:",*arrint) //每轮排序后: [24 69 57 13 80] //每轮排序后: [24 57 13 69 80] //每轮排序后: [24 13 57 69 80] //每轮排序后: [13 24 57 69 80] } } func main() { arrint := [5]int{24,69,80,57,13} test(&arrint) fmt.Println("main:",arrint) // main: [13 24 57 69 80] }冒泡排序例子2(数组赋值给数组):有一个长度为5且升序排序的数组,要求插入一个元素,最后打印数组,顺序依旧是升序
func test(num int) { // arrint 数组的长度为5 arrint := [...]int{10,20,30,40,50} // arrint_new 数组的长度为5+1=6 var arrint_new [len(arrint)+1]int // 把数组arrint所有的值,循环赋值给数组arrint_new。 for i:=0;i<len(arrint);i++ { arrint_new[i]=arrint[i] } // 数组arrint_new的最后一个索引值为"输入的值num" arrint_new[len(arrint)]=num // 升序的逻辑 fmt.Println("排序前:",arrint_new) temp := 0 // 第一轮排序 for j :=0;j<len(arrint_new)-1;j++{ for i:=0;i<len(arrint_new)-1-j;i++ { if (arrint_new)[i] > (arrint_new)[i+1] { temp = (arrint_new)[i] (arrint_new)[i] = (arrint_new)[i+1] (arrint_new)[i+1] = temp } } } fmt.Println("排序后的值:",arrint_new) } func main() { test(1) //排序前: [10 20 30 40 50 1] //排序后的值: [1 10 20 30 40 50] test(100) //排序前: [10 20 30 40 50 100] //排序后的值: [10 20 30 40 50 100] }1.7.3、二分查找
案例:数组是一个有序数组,并且是从小到大排序的:arr = [1 2 3 4 5 6 7]
分析思路:
1.先找到数组中间的索引值,middle = (leftindex + rightindex)/2,然后和findVal比较
2.如果arr[middle] > findVal,那么继续比较 leftindex ~ (middle-1)
3.如果arr[middle] < findVal,那么继续比较 (middle+1) ~ rightindex
4.arr[middle] = findVal,那么退出如果所有的都找完了,都没有找到,那就直接退出,否则死循环
5.leftindex > rightindex时,直接退出代码实现
func test(arrint *[6]int, leftIndex int, rightIndex int, findVlue int) { moddleIndex := (leftIndex+rightIndex)/2 // 判断leftIndex是否大于rightIndex,如果大于,说明没找到,直接退出 if leftIndex > rightIndex { fmt.Printf("没有找到:%v\n", findVlue) return } // 如果arrint[moddleIndex] > findVlue,那么继续比较 leftIndex ~ (moddleIndex-1) if (*arrint)[moddleIndex] > findVlue { test(arrint,leftIndex,moddleIndex-1,findVlue) // 如果arrint[moddleIndex] < findVlue,那么继续比较 (moddleIndex+1) ~ rightIndex } else if (*arrint)[moddleIndex] < findVlue { test(arrint,moddleIndex+1,rightIndex,findVlue) } else if (*arrint)[moddleIndex] == findVlue{ fmt.Printf("找到了:%v,索引为:%v\n", (*arrint)[moddleIndex], moddleIndex) return } } func main() { arrint := [6]int{13, 24, 57, 69, 80, 100} test(&arrint,0,len(arrint)-1,57) // 找到了:57,索引为:2 test(&arrint,0,len(arrint)-1,58) // 没有找到:58 }
数组和切片的区别:切片可以通过执行 append 方法来测试,数组不能使用 append 方法。
func main() {
// a 的定义方式就是一个数组,执行append时会报错
a := [10]int{1, 2, 3}
a = append(a, 44)
fmt.Println(a)
// first argument to append must be slice; have [3]int
// b 的定义方式就是一个数组,执行append时会报错
b := [...]int{1, 2, 3}
b = append(b, 44)
fmt.Println(b)
// first argument to append must be slice; have [3]int
// c 的定义方式就是一个切片
c := []int{1, 2, 3}
c = append(c, 44)
fmt.Println(c)
// [1,2,3,44]
}二、切片Slice (和数组类似,只是没有长度限制,是数组的抽象) -- 切片是引用类型(切片作为实参时,修改切片的值,原切片的值会跟着改变【如果不想改变原切片的值,那么需要使用copy()函数创建一个新的切片,作为实参】)
2.1、切片(Slice)是一个拥有相同类型元素的可变长度的序列。它是基于数组类型做的一层封装。它非常灵活,支持自动扩容。
切片是一个引用类型,它的内部结构包含地址、长度和容量。切片一般用于快速地操作一块数据集合。2.2、声明切片类型的基本语法如下:
var name []typename: 表示变量名
type: 表示切片中的元素类型数组的变量声明:var name [5]type | var name [...]type 和切片做区分
2.3、切片的定义
2.3.1、直接定义
func main() { //切片的定义 var s1 = []int{1, 2, 3} // 定义存放 int 类型的切片,并初始化 var s2 = []string{"a", "b", "c"} // 定义存放 string 类型的切片,并初始化 fmt.Println(s1) // [1 2 3] fmt.Println(s2) // [a b c] // 定义空切片 var slice []int fmt.Println(slice) // [] c := []int{} fmt.Println(c) // [] }2.3.2、通过取数组的索引值来定义一个切片(修改切片的值,就会改变数组的值)
func main() { // 定义数组 arrint := [...]int{1,2,3,4,5} // 通过取数组的索引值来定义一个切片 sliceint := arrint[1:3] fmt.Println(sliceint) // [2 3] // 把切片索引为0的值修改为111 sliceint[0] = 111 fmt.Println(sliceint) // [111 3] // 查看数组的值(数组的值"2"已经被修改为"111"了) fmt.Println(arrint) // [1 111 3 4 5] }2.3.3、使用 make()函数 构造切片(详见2.7)
2.4、切片的长度len和容量cap
切片拥有自己的长度和容量,我们可以通过使用内置的len()函数求切片的长度,使用内置的cap()函数求切片的容量func main() { //切片的定义 var s1 = []int{1, 2, 3} // 定义存放 int 类型的切片,并初始化 var s2 = []string{"a", "b", "c"} // 定义存放 string 类型的切片,并初始化 fmt.Printf("长度s1:%v,容量s1:%v\n", len(s1), cap(s1)) //长度s1:3,容量s1:3 fmt.Printf("长度s2:%v,容量s2:%v", len(s2), cap(s2)) //长度s2:3,容量s2:3 }2.5、简单切片表达式 ( a[0:3] a[low : high] ) 需要满足:0 <= low <= high <= len(a)
切片的底层就是一个数组,所以我们可以基于数组通过切片表达式得到切片。简单切片表达式中切片容量(cap)为: len(a) - low
简单切片表达式中得到的切片长度(len) 为: a[0:3] 取到的值func main() { // 数组切片 a1 := [...]int{1, 2, 3, 4, 5, 6} s1 := a1[1:4] fmt.Printf("s1:%v len(s1):%v cap(s1):%v\n", s1, len(s1), cap(s1)) } // s1:[2 3 4] len(s1):3 cap(s1):5为了方便起见,可以省略切片表达式中的任何索引。省略了low则默认为0;省略了high则默认为切片操作数的长度:
- a := [5]int{1, 2, 3, 4, 5}
- a[2:] // 等同于 a[2:len(a)]
- a[:3] // 等同于 a[0:3]
- a[:] // 等同于 a[0:len(a)],等于获取所有的值
2.6、完整切片表达式 ( 切片后在切片 a[0:3:4] a[low : high : max] )
需要满足:0 <= low <= high <= max <= cap(a),其他条件和简单切片表达式相同。
完整切片表达式中切片容量(cap)为: max - low
完整切片表达式中得到的切片长度(len) 为: a[0:3] 取到的值func main() { // 数组切片后在切片 a := [5]int{1, 2, 3, 4, 5} t := a[1:3:5] fmt.Printf("t:%v len(t):%v cap(t):%v\n", t, len(t), cap(t)) // t:[2 3] len(t):2 cap(t):4 } func main() { // 数组切片后在切片(2个切换分开执行) a := [5]int{1, 2, 3, 4, 5} t := a[1:5] fmt.Println(t) // [2 3 4 5] t1 := t[1:3] fmt.Println(t1) // [3 4] }判断切片是否为空:请始终使用len(s) == 0来判断,而不应该使用s == nil来判断。
2.7、使用 make([]type, size, cap) 函数 构造切片
我们上面都是基于数组来创建的切片,如果需要动态的创建一个切片,我们就需要使用内置的make()函数,格式如下:
- make([]type, size, cap)
- type: 切片的元素类型
- size: 切片中默认元素的数量(元素的数量设置为2时,默认值就是[0 0])
- cap: 切片的容量
举例:
// 定义切片,设置长度为2(最大可以存放2个值) func main() { var test []int test = make([]int,2) fmt.Println(test) //[0 0] } // 定义切片设置长度为2,容量为10(最大可以存放2个值) func main() { a := make([]int, 2, 10) fmt.Println(a) //[0 0] fmt.Println(len(a)) //2 fmt.Println(cap(a)) //10 } // 定义切片,设置长度为1 (最大可以存放1个值,超过1个值会报错,此时只能通过append传值) func main() { test := make([]int,1,10) test[0]=11 test[1]=22 fmt.Println(test) // 报错:panic: runtime error: index out of range [1] with length 1 // 直接报错的原因:make时设置的长度为1,但此时切片的长度已经为2 // 超过长度后,只能通过append的方式传递值 test = append(test,33) fmt.Println(test) }上面代码中a的内部存储空间已经分配了10个,但实际上只用了2个,容量并不会影响当前元素的个数,所以len(a)返回2,cap(a)则返回该切片的容量。
2.7.1、make函数构造切片时,只设置size(切片的元素数量)为2时,那么len和cap的值都为2
func main() { dst := make([]int, 2) fmt.Printf("len:%v cap:%v", len(dst), cap(dst)) // len:2 cap:2 }2.7.2、make 初始化切片后,使用append 给切片赋值,追加值
// size为0时[],追加值"1", "2",结果就是[1 2] func main() { var value = make([]string, 0, 2) value = append(value, "1", "2") fmt.Println(value) // [1 2] } // size为2时[0 0],追加值1,2,结果就是[0 0 1 2] func main() { res := make([]int,2,5) res = append(res,1,2) fmt.Println(res) // [0 0 1 2] }2.8、切片的内部布局示意图
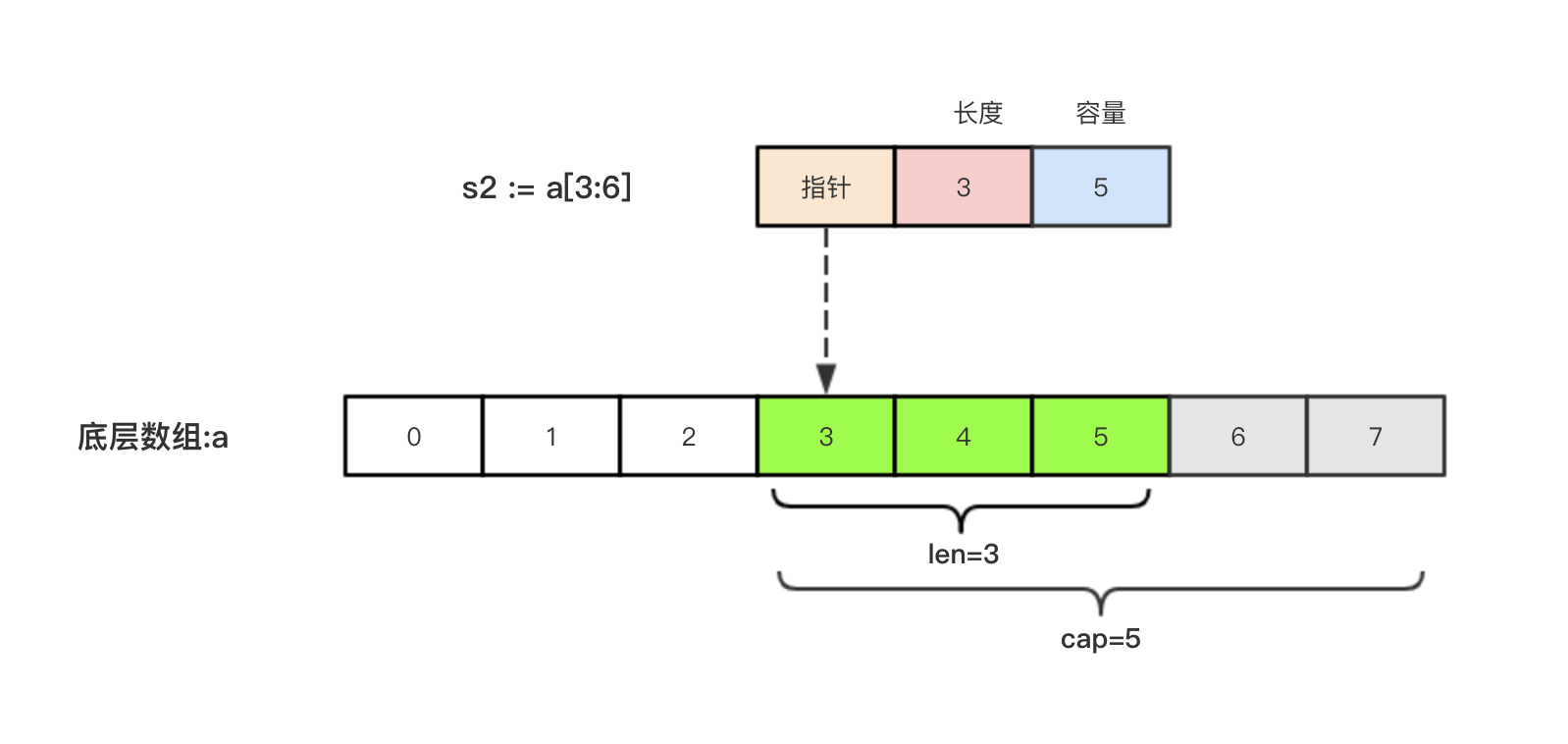
切片的本质就是对底层数组的封装,它包含了三个信息:底层数组的指针、切片的长度(len)和切片的容量(cap)
举例,现在有一个数组a := [8]int{0, 1, 2, 3, 4, 5, 6, 7}
切片s1 := a[:5],相应示意图如下:
切片s2 := a[3:6],相应示意图如下:
2.9、切片的赋值拷贝
下面的代码中演示了拷贝前后两个变量共享底层数组,对一个切片的修改会影响另一个切片的内容,这点需要特别注意。func main() { s1 := make([]int, 3) //[0 0 0] s2 := s1 //将s1直接赋值给s2,s1和s2共用一个底层数组 s2[0] = 100 fmt.Println(s1) //[100 0 0] fmt.Println(s2) //[100 0 0] }2.10、切片遍历
切片的遍历方式和数组是一致的,支持索引遍历和for range遍历。
func main() { s := []int{1, 3, 5} //方法1: for i := 0; i < len(s); i++ { fmt.Println(s[i]) } //方法2: for _, value := range s { fmt.Println(value) } }2.11、append()方法 为切片添加元素
Go语言的内建函数append()可以为切片动态添加元素。 可以一次添加一个元素,可以添加多个元素,也可以添加另一个切片中的元素(后面加…)备注: 一维数组时需要加…,二维数组时不需要加…
func main() { var s []int // 添加一个值 s = append(s, 1) // [1] fmt.Println(s) // 添加多个值 s = append(s, 2, 3, 4) // [1 2 3 4] fmt.Println(s) // 添加另外一个切片 s2 := []int{5, 6, 7} s = append(s, s2...) // [1 2 3 4 5 6 7] fmt.Println(s) }每个切片会指向一个底层数组,这个数组的容量够用就添加新增元素。当底层数组不能容纳新增的元素时,切片就会自动按照一定的策略进行“扩容”,此时该切片指向的底层数组就会更换。“扩容”操作往往发生在append()函数调用时,所以我们通常都需要用原变量接收append函数的返回值。
举个例子:
func main() { //append()添加元素和切片扩容 var num []int for i := 0; i < 10; i += 1 { num = append(num, i) fmt.Println(num) } }输出:
[0] len:1 cap:1 ptr:0xc000014068
[0 1] len:2 cap:2 ptr:0xc000014090
[0 1 2] len:3 cap:4 ptr:0xc000016160
[0 1 2 3] len:4 cap:4 ptr:0xc000016160
[0 1 2 3 4] len:5 cap:8 ptr:0xc00001a140
[0 1 2 3 4 5] len:6 cap:8 ptr:0xc00001a140
[0 1 2 3 4 5 6] len:7 cap:8 ptr:0xc00001a140
[0 1 2 3 4 5 6 7] len:8 cap:8 ptr:0xc00001a140
[0 1 2 3 4 5 6 7 8] len:9 cap:16 ptr:0xc000102000
[0 1 2 3 4 5 6 7 8 9] len:10 cap:16 ptr:0xc000102000从上面的结果可以看出:
append()函数将元素追加到切片的最后并返回该切片。
切片numSlice的容量按照1,2,4,8,16这样的规则自动进行扩容,每次扩容后都是扩容前的2倍。2.12、使用append合并多个数组 (多个数组分成两两合并)
func main() { var arr1 = []int{1, 2, 3} var arr2 = []int{4, 5, 6} var arr3 = []int{7, 8, 9} // 多个数组分成两两合并 var s1 = append(append(arr1, arr2...), arr3...) fmt.Printf("s1: %v\n", s1) // s1: [1 2 4 5 7 8] fmt.Printf("len: %v cap: %v\n", len(s1), cap(s1)) // len: 6 cap: 8 }2.13、使用append 删除索引的值
a = append(a[:i], a[j:]...) 删除切片 a 中从索引 i 至 j 位置的值 ( 删除的值是a[i:j] )
func main() { // a = append(a[:i], a[j:]...):删除切片 a 中从索引 i 至 j 位置的值 s := []int{1, 2, 3, 4, 5, 6, 7} s = append(s[:1], s[5:]...) fmt.Println(s) // [1 6 7] }2.14、使用 copy()函数 复制切片(使用copy函数将a切片复制到b切片,那么ab切片相互独立,修改不影响对方)
首先我们来看一个问题:由于切片是引用类型,所以a和b其实都指向了同一块内存地址。修改b的同时a的值也会发生变化。
func main() { a := []int{1, 2, 3, 4, 5} b := a fmt.Println(a) //[1 2 3 4 5] fmt.Println(b) //[1 2 3 4 5] b[0] = 1000 fmt.Println(a) //[1000 2 3 4 5] fmt.Println(b) //[1000 2 3 4 5] }Go语言内建的copy()函数(只能给切片使用,数组不能使用)可以迅速地将一个切片的数据复制到另外一个切片空间中,copy()函数的使用格式:copy(源,目标 []type)
- srcSlice: 数据来源切片
- destSlice: 目标切片
举个例子1:当A把值复制到C时,C的cap大小和A一样( cap(A) = cap(C) )时,那么A的值可以全部复制到C。
func main() { // copy()复制切片 a := []int{1, 2, 3, 4, 5} // [1 2 3 4 5] c := make([]int, 5, 5) // [0 0 0 0 0] //使用copy()函数将切片a中的元素复制到切片c,此时a和c的值相同 copy(c, a) fmt.Println(a) //[1 2 3 4 5] fmt.Println(c) //[1 2 3 4 5] // 修改切片c的值,不会影响切片a的值。 c[0] = 1000 fmt.Println(a) //[1 2 3 4 5] fmt.Println(c) //[1000 2 3 4 5] }举个例子2:当A把值复制到C时,C的cap大小和A不一样时:
当 cap(A) > cap(C) 时:A的值只有1和2复制到C,3因为受到了C的cap限制,无法复制过去
func main() { A := []int{1, 2, 3} C := make([]int, 2) //当 cap(A) > cap(C) fmt.Printf("cap-A:%v cap-C:%v\n", cap(A), cap(C)) // cap-A:3 cap-C:2 copy(C, A) // 把A的值复制到C fmt.Printf("A:%v C:%v", A, C) // 结果:A:[1 2 3] C:[1 2] // A的值只有1和2复制到C,3因为受到了C的cap限制,无法复制过去 }当 cap(A) < cap(C) 时:A的值可以全部复制到C,由于C的cap值比A大,所以C的多余值用0填充
func main() { A := []int{1, 2, 3} C := make([]int, 5) //当 cap(A) < cap(C) fmt.Printf("cap-A:%v cap-C:%v\n", cap(A), cap(C)) // cap-A:3 cap-C:5 copy(C, A) // 把A的值复制到C fmt.Printf("A:%v C:%v", A, C) // 结果:A:[1 2 3] C:[1 2 3 0 0] // A的值可以全部复制到C,由于C的cap值比A大,所以C的多余值用0填充 }

string的底层是一个byte数组,因此string也可以进行切片处理
func main() {
// string类型
str := "sudada@atguigu"
res := str[0:6]
fmt.Println(res) // sudada
// string类型是不可变的,所以不能通过name[0] = "xxx"的方式修改字符串,需要按照如下方式转换:
// 修改字符串,现将string -> []byte 或者 []rune -> 修改 -> 重写转成string
arr1 := []byte(str)
arr1[0] = 'x' // 将str的第一个值改为'x'
str = string(arr1)
fmt.Println(str) // xudada@atguigu 这里可以看到第一个值为'x'
}三、MAP (字典) -- map是引用类型(map作为实参时,修改map的值,原map的值会跟着改变)
Go语言中提供的映射关系容器为map,其内部使用散列表(hash)实现。
map是一种无序的基于key-value的数据结构,Go语言中的map是引用类型,必须初始化才能使用。3.1、map的语法定义 map[KeyType]ValueType
- KeyType: 表示键的类型(通常为int或string,其中slice,map,function不可以作为key的类型,因为不能用==来判断)
- ValueType: 表示值的类型(通常为int,string,map,struct)
map类型的变量默认初始值为空,需要使用make()函数来分配内存。语法为:
make( map[KeyType]ValueType, [cap] )
其中cap表示map的容量,该参数虽然不是必须的,但是我们应该在初始化map时为其指定一个合适的容量。3.2、map的声明
3.2.1、map的3种声明方式
make()初始化一个map时,map的预估容量(键值对)为10,如果超过10的时候,会自动扩容,不会报错。
// 方式1(先声明,在make,在赋值) func main() { // 定义一个map: sudada var sudada map[string]string // 使用map前,需要先make,目的是给map分配内存空间(声明完毕后,不make,直接赋值会报错) // 使用make,给map分配内存空间(空间的大小是10,超过10也不会报错,会自动扩容) sudada = make(map[string]string,10) // 最后赋值 sudada["name"] = "sudada" // 此时赋值就不会报错 fmt.Println(sudada) // map[name:sudada] } // 方式2(声明时就make,然后在赋值) func main() { // 定义一个map: sudada,并make var sudada = make(map[string]string, 10) // 然后赋值 sudada["name"] = "sudada" // 此时赋值就不会报错 fmt.Println(sudada) // map[name:sudada] } // 方式3(声明时就赋值,然后在赋值) func main() { // 定义一个map: sudada,并赋值 var sudada = map[string]string{ "name": "sudada", } // 然后在赋值 sudada["age"] = "18" fmt.Println(sudada) // map[age:18 name:sudada] } // 方式3的简写 func main() { // 定义一个map: sudada,并赋值 sudada := map[string]string{ "name": "sudada", } // 然后在赋值 sudada["age"] = "18" fmt.Println(sudada) // map[age:18 name:sudada] }3.2.2、map嵌套:{"key":{"key":"value"}}
func main() { // 定义一个双层map结构:{"key":{"key":"value"}} student := map[string]map[string]string{ "student1": {"name":"sudada"}, "student2": {"name":"sudada1"}, } fmt.Println(student) // map[student1:map[name:sudada] student2:map[name:sudada1]] }3.2.3、map删除一个key(使用delete()函数删除键值对)
使用delete()内建函数从map中删除一组键值对,delete()函数的格式如下:
delete(map, key)
- map: 表示要删除键值对的map
- key: 表示要删除的键值对的键
示例代码如下:
func main() { test:= map[string]string{ "name":"sudada", "age":"18", } // 删除一个Key delete(test,"name") // 删除一个不存在的key时,也不会报错 delete(test,"xxx") fmt.Println(test) // 删除后,只剩下一个值:map[age:18] }3.2.4、map删除所有key(for循环删除,make清空)
func main() { test:= map[string]string{ "name":"sudada", "age":"18", } // 删除所有的Key(方式1:for循环删除) for k,_ := range test { delete(test, k) } fmt.Println(test) // map[] // 方式2:直接make一个新的空间 test = make(map[string]string) fmt.Println(test) // map[] }3.3、map取值
判断key是否存在,Go语言中有个判断map中键是否存在的特殊写法,格式:value, ok := map[key]
// 方式1:value, ok := szq_dict["szq"] func main() { szq_dict := make(map[string]string, 10) szq_dict["age"] = "18" szq_dict["name"] = "sudada" // map 定义后,通过key取值 fmt.Println(szq_dict["age"]) // 18 fmt.Println(szq_dict["name"]) // sudada // 如果key不存在时: value, ok := szq_dict["szq"] if !ok { fmt.Println("无此键") } else { fmt.Println(value) } } // 方式2:if map[key] == nil func main() { // 判断用户是否存在 if map[key] == nil { fmt.Printf("key: %v不存在\n",key) } else { fmt.Printf("key: %v存在\n",key) } }3.4、map通过for range遍历
func main() { test_dict := make(map[string]int, 10) test_dict["sudada"] = 18 test_dict["szq"] = 28 for k, v := range test_dict { fmt.Println(k, v) // sudada 18 // szq 28 } }只想遍历key的时候,可以按下面的写法:
func main() { test_dict := make(map[string]int, 10) test_dict["sudada"] = 18 test_dict["szq"] = 28 for k, _ := range test_dict { fmt.Println(k) // sudada // szq } }3.5、元素为map类型的切片 (切片里面的值均为map,可以理解为列表内的值为字典)
切片里面的map在使用时,需要做初始化操作。
func main() { // 声明一个map切片,计划存放的2个key var test = make([]map[string]string,2) fmt.Println(test) // [map[] map[]] // map在使用前需要先make test[0]=make(map[string]string,) test[0]["name"] = "sudada" test[0]["age"] = "18" // map在使用前需要先make test[1]=make(map[string]string) test[1]["name"] = "zhang" test[1]["age"] = "28" fmt.Println(test) // [map[age:18 name:sudada] map[age:28 name:zhang]] // 当超过2个key时,通过append的方式给切片追加新的key newTest := map[string]string{ "name":"wang", "age":"38", } test = append(test,newTest) fmt.Println(test) // [map[age:18 name:sudada] map[age:28 name:zhang] map[age:38 name:wang]] }3.6、值为切片类型的map (map的key对应的value是切片)
map里面的切片在使用时,需要做初始化操作。
func main() { // 1、初始化map var sliceMap = make(map[string][]string) fmt.Println(sliceMap) // map[] // 2、初始化切片 var value = make([]string, 0, 2) // 给切片赋值 value = append(value, "北京", "上海") // 给map的key赋值 sliceMap["city"] = value fmt.Println(sliceMap) // map[city:[北京 上海]] }3.7、map排序
golang默认就是无序的,那么golang排序的思路:先将key排序,然后根据key值遍历输出即可。
func main() { // 1.先将map的key放入到切片中 qiepian := []string{} testmap := map[string]string{ "name":"name", "age":"age", "sex":"sex", "player":"player", } for k,_ := range testmap { qiepian = append(qiepian,k) } fmt.Println(qiepian) // [name age sex player] // 2.对切片排序 sort.Strings(qiepian) // 使用内置函数sort.Strings对string排序 // sort.Ints(int类型切片) // 使用内置函数sort.Ints对int排序 fmt.Println(qiepian) // [age name player sex] // 3.遍历切片,然后按照key来输出map的值 for i:=0;i<len(qiepian);i++{ fmt.Println(testmap[qiepian[i]]) // 依次输出:age,name,player,sex } }
四、练习题
5.1、写一个程序,统计一个字符串中每个单词出现的次数。比如:”how do you do”中how=1 do=2 you=1。
func main() { str := "how do you do think you about" // 将整个字符串按照" "为分隔符做分割。得到一个数组 strSlice := strings.Split(str, " ") fmt.Println(strSlice) // [how do you do think you about] // 方法1 count_map := make(map[string]int, 10) for _, value := range strSlice { _, ok := count_map[value] if ok { count_map[value] += 1 } else { count_map[value] = 1 } } fmt.Println(count_map) // map[about:1 do:2 how:1 think:1 you:2] // 方法2 count_map_2 := make(map[string]int, 10) for _, v := range strSlice { count_map_2[v] = count_map_2[v] + 1 // 也可以写成:count_map[v] += 1 } fmt.Println(count_map_2) // map[about:1 do:2 how:1 think:1 you:2] }5.2、使用map嵌套的方式判断一个用户是否存在:{"key":{"key":"value"}}
func User(users map[string]map[string]string, name string) { // 判断用户是否存在 if users[name] == nil { fmt.Printf("用户: %v不存在\n",name) } else { fmt.Printf("用户登录: %v\n",name) } } func main() { tests := make(map[string]map[string]string, 10) User(tests,"xxx") // 用户: xxx不存在 tests["sudada"] = make(map[string]string, 2) tests["sudada"]["sex"]="nan" tests["sudada"]["age"]="18" fmt.Println(tests) // map[sudada:map[age:18 sex:nan]] User(tests,"sudada") // 用户登录: sudada }















 2422
2422











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









