






这段时间学习了一些大数据开发的基础知识,这篇学习笔记的主要内容是把这些知识进行回顾和整理。
学习的内容:
(1)HDFS
(2)YARN
(3)MapReduce
1. HDFS介绍
1.1 Hadoop2
定义:Hadoop是Apache软件基金会旗下的一个分布式系统基础架构。Hadoop2的框架最核心的设计就是HDFS,MapReduce,YARN。为海量的数据提供了存储和计算。
Hadoop 1.0和Hadoop 2.0的结构对比:
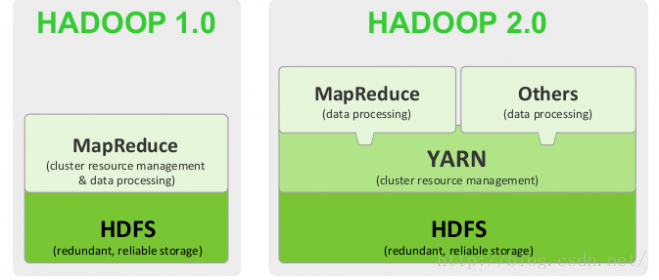
Hadoop2 的主要改进:
1. YARN。Hadoop2中的新方案:YARN+MapReduce,YARN只负责资源调度管理。第一代MapReduce中的资源管理和作业管理均是由JobTracker实现的,集两个功能于一身;而在第二代中,则将这两部分分开了。 其中,作业管理由ApplicationMaster实现,而资源管理由新增系统YARN完成。
2. NameNode HA。Hadoop2中HDFS的HA主要指的是可以同时启动2个NameNode。中一个处于工作状态,另一个处于随时待命状态。这样,当一个NameNode所在的服务器宕机时,可以在数据不丢失的情况下,手工或者自动切换到另一个NameNode提供服务。
3. HDFS federation。老HDFS架构由一个Namenode和一组datanode组成。而HDFS Federation 由多个Namenode和一组Datanode,每一个Datanode会为多个块池(block pool)存储块。
4. Hadoop RPC 序列化扩展性。
1.2 HDFS的简介
HDFS(Hadoop Distributed File System )Hadoop分布式文件系统。
主要特点:
支持超大文件、检测和快速应对硬件故障、高吞吐量、简化一致性模型。
HDFS不适合的场景:低延迟数据访问;大量的小文件;多用户写入文件、修改文件。
1.2.1 HDFS的构成
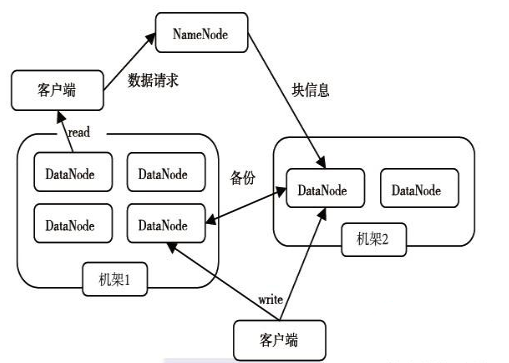
NameNode保存着HDFS的名字空间,对于任何对文件系统元数据产生修改的操作;
DataNode将HDFS数据以文件的形式存储在本地文件系统中,它并不知道有关HDFS文件的信息。
1.2.2 数据块
在Hadoop 2.0中默认大小为128MB。
数据块的好处:
Hadoop可以保存比存储节点单一磁盘大的文件;简化了存储子系统,简化了存储管理,也消除了分布式管理文件元数据的复杂性;方便容错,有利于数据复制。
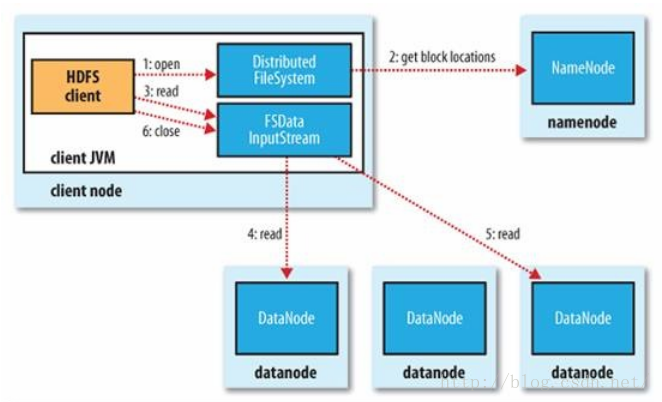
1.3 HDFS的读写过程
读过程:
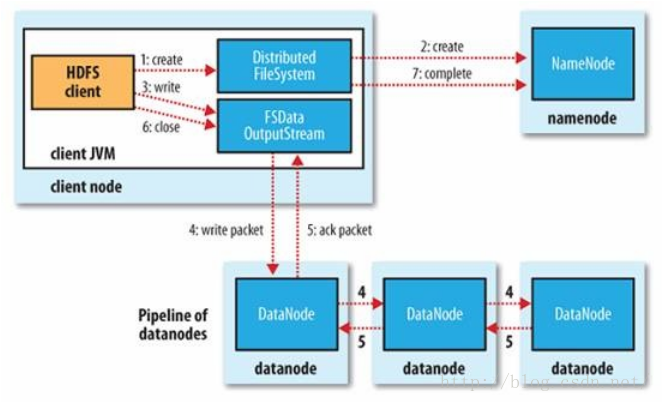
写过程:
2. YARN
2.1 YARN 产生背景
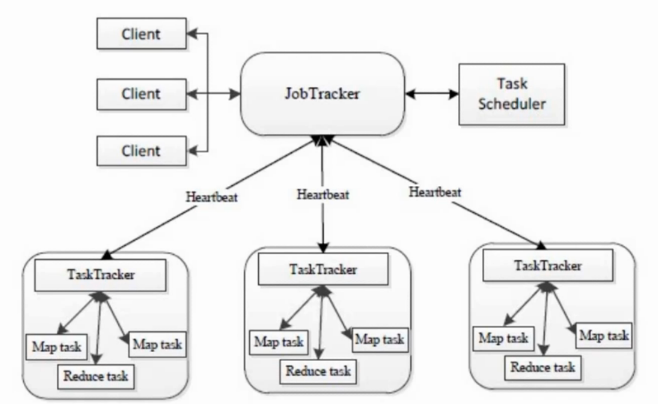
Hadoop 1.0的弊端包括:扩展性差、可靠性差、资源利用率低、无法支持多种计算框架。
Hadoop1.x的MapReduce构成图:
2.2 YARN 基本结构
YARN的基本思想是将JobTracker的两个主要功能(资源管理和作业调度/监控)分离,主要方法是创建一个全局的ResourceManager(RM)和若干个针对应用程序的ApplicationMaster(AM)。
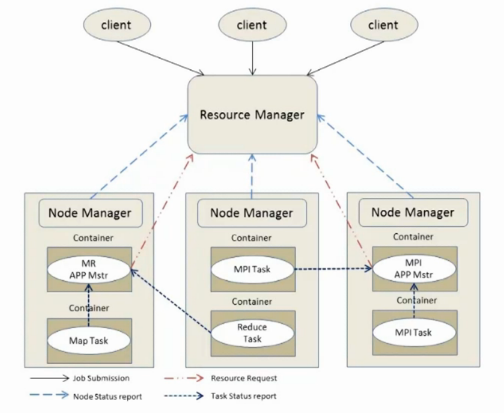
它由下面几大构成组件:
a. 一个全局的资源管理器 ResourceManager
b.ResourceManager的每个节点代理 NodeManager
c. 表示每个应用的 ApplicationMaster
d. 每一个ApplicationMaster拥有多个Container在NodeManager上运行
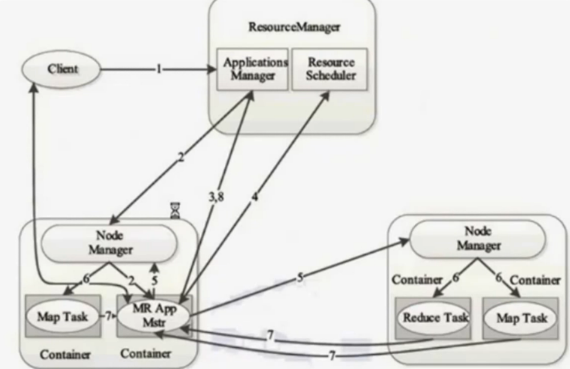
2.3 YARN 工作流程
3. MapReduce
3.1 MapReduce的简介
MapReduce是由Google公司研究提出的一种面向大规模数据处理的并行计算模型和方法,是Hadoop面向大数据并行处理的计算模型、框架和平台。
MapReduce执行流:

3.2 MapReduce2运行原理
MapReduce2整体图:
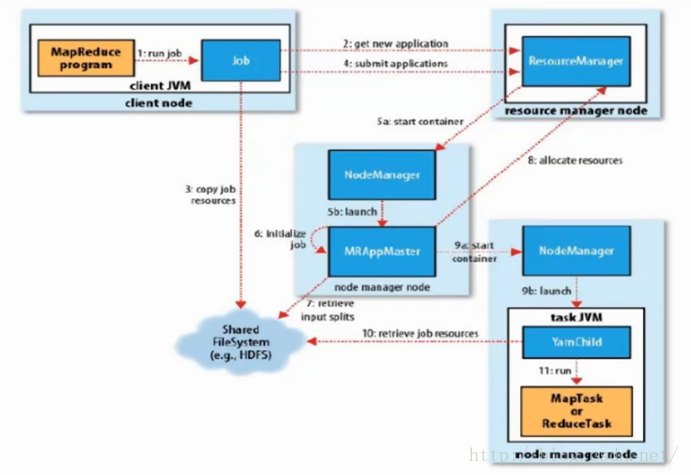
MapReduce2进度状态更新:
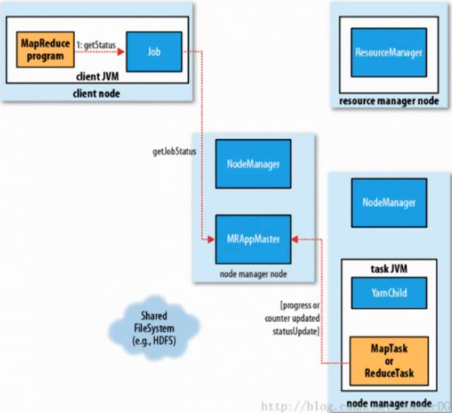
3.3 shuffle及排序
apreduce的map端输出作为输入传递给reduce端,并按键排序的过程称为shuffle。
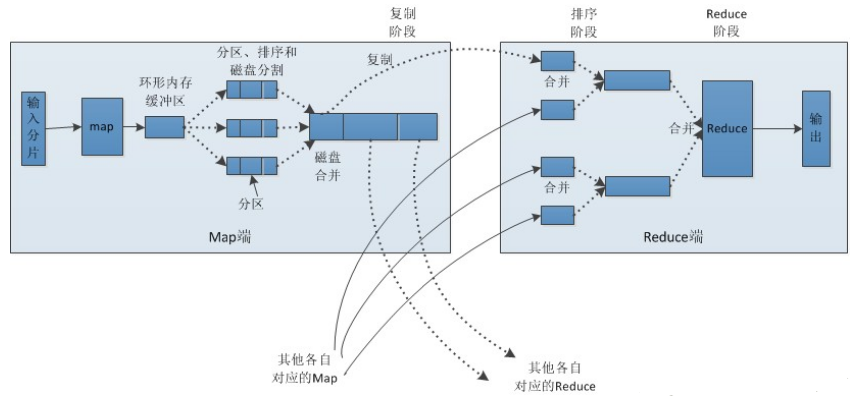
Map端:
(1)在map端首先接触的是InputSplit(输入分片),在InputSplit中含有DataNode中的数据,每一个InputSplit都会分配一个Mapper任务,Mapper任务结束后产生输出, 这些输出先存放在 缓存 中 , 每个map有一个环形内存缓冲区,用于存储任务的输出。默认大小100MB(io.sort.mb属性),一旦达到阀值0.8(io.sort.spil l.percent),一个后台线程就把内容写到(spill)Linux本地磁盘中的指定目录(mapred.local.dir)下的新建的一个溢出 写文件。
(2)写磁盘前,要进行partition、sort和combine等操作。通过分区,将不同类型的数据分开处理,之后对不同分区的数据进行 排序,如果有Combiner,还要对排序后的数据进行combine。等最后记录写完,将全部溢出文件合并为一个分区且排序的文件。
(3)最后将磁盘中的数据送到Reduce中,从图中可以看出Map输出有三个分区,有一个分区数据被送到图示的Reduce任务中,剩下的两个分区被送到其他Reducer任务中。而图示的Reducer任务的其他的三个输入则来自其他节点的Map输出。
reduce端:
(1)Copy(复制)阶段:Reducer通过Http方式得到输出文件的分区。
reduce端可能从n个map的结果中获取数据,而这些map的执行速度不尽相同,当其中一个map运行结束时,reduce就会从 JobTracker中获取该信息。map运行结束后TaskTracker会得到消息,进而将消息汇报给JobTracker,reduce定时从 JobTracker获取该信息,reduce端默认有5个数据复制线程从map端复制数据。
(2)Merge阶段:如果形成多个磁盘文件会进行合并
从map端复制来的数据首先写到reduce端的缓存中,同样缓存占用到达一定阈值后会将数据写到磁盘中,同样会进行partition、 combine、排序等过程。如果形成了多个磁盘文件还会进行合并,最后一次合并的结果作为reduce的输入而不是写入到磁盘中。
(3)Reducer的参数:最后将合并后的结果作为输入传入Reduce任务中。















 1007
1007

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









