






接下来我们来一一介绍scrapy命令有哪些,其实灰常少,也就十四五个,在这十四五个中,常用的就纳么两三个而已,如:
scrapy startproject(创建项目)、
scrapy crawl XX(运行XX蜘蛛)、
scrapy shell http://www.scrapyd.cn(调试网址为http://www.scrapyd.cn的网站),
这些就是最常用的,至于其他的话偶尔会用一下,这里的话只是希望诸君不要被命令二字吓到,没神马可怕的,比起你没有男(女)朋友!但为了文档的全面,也需要全面的跟诸位介绍哈其他命令!
为了大家好记,可以吧scrapy命令分为:全局命令、项目命令;很好理解,全局命令就是在哪都能用;项目命令就是只能依托你的项目;
全局命令有如下几个:
startproject genspider settings runspider shell fetch view version其实如果你细心,你会发现,这些命令是我们在命令行输入:scrapy就主动跳出来的命令:
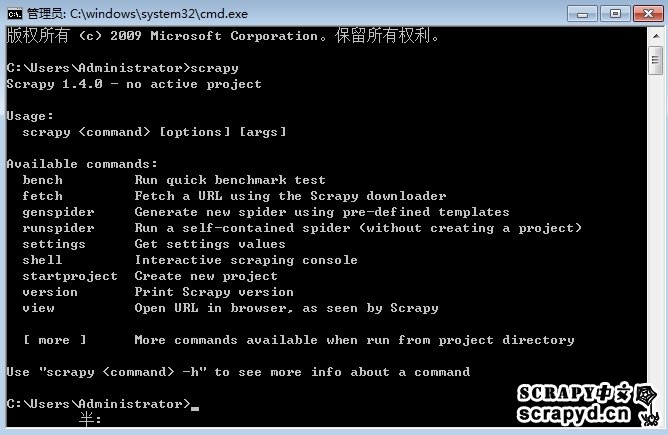
那这些全局命令就是不依托项目存在的,也就是不关你有木有项目都能运行,比如:startproject它就是创建项目的命令,肯定是没有项目也能运行;那接下来我们来看一下它们的详细用法;
一、startproject
这个是见得最多,创建项目的,如,创建一个名为:scrapyChina的项目:
scrapy strartproject scrapychina用法灰常简单,你能看到这里,应该已经用过多次了,就这么简单;
二、genspider
这个命令的话是根据蜘蛛模板创建蜘蛛的命令,我们有一篇文章:《 scrapy命令:genspider详解》,这篇文章已经对scrapy命令genspider的祖祖孙孙做了一个灰常详细的解密,这里不重复大家跳转了看哈!
三、settings
看字面意思,相信聪明的你已经知道它是干嘛的了!其实它就是方便你查看到你对你的scray设置了些神马参数!比如我们想得到蜘蛛的下载延迟,我们可以使用:
scrapy settings --get DOWNLOAD_DELAY比如我们想得到蜘蛛的名字:
scrapy settings --get BOT_NAME不常用,记得有这么一个就行了!
四、runspider
这个命令有意思,上面我们介绍过,运行蜘蛛除了使用:scrapy crawl XX之外,我们还能用:runspider,前者是基于项目运行,后者是基于文件运行,也就是说你按照scrapy的蜘蛛格式编写了一个py文件,那你不想创建项目,那你就可以使用runspider,比如你编写了一个:scrapyd_cn.py的蜘蛛,你要直接运行就是:
scrapy runspider scrapy_cn.py五、shell
这个命令比较重要,主要是调试用,里面还有很多细节的命令,我们会专门出一期专题详说,这里的话你需要记住它的使用方法,比如我们要调试http://www.scrapyd.cn,看我们的选择器到底有木有正确选中某个元素,那我们就可以这样来玩,首先用调试打开:http://www.scrapyd.cn(scrpay中文网):
scrapy shell http://www.scrapyd.cn然后我们可以直接执行命令,response,比如我们要测试我们获取标题的选择器正不正确,我们可以这样:
response.css("title").extract_first()
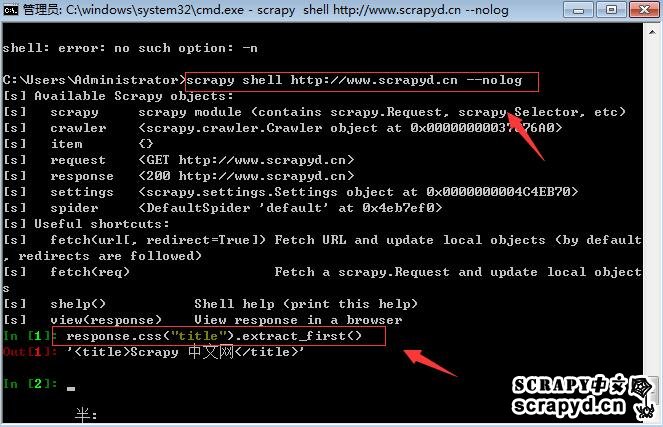
基本上,这就是这个命令最常用的用法,应该记住它就是调试用的,至于里面的详细参数,我们会专门出一个专题细说,请关注!
六、fetch
这个命令其实也可以归结为调试命令的范畴!它的功效就是模拟我们的蜘蛛下载页面,也就是说用这个命令下载的页面就是我们蜘蛛运行时下载的页面,这样的好处就是能准确诊断出,我们的到的html结构到底是不是我们所看到的,然后能及时调整我们编写爬虫的策略!举个栗子,淘宝详情页,我们一般看得到,但你如果按常规的方法却爬不到,为神马?因为它使用了异步传输!因此但你发现获取不到内容的时候,你就要有所警觉,感觉用fetch命令来吧它的html代码拿下来看看,到底有木有我们想要的那个标签节点,如果木有的话,你就要明白我们需要使用js渲染之类的技术!用法很简单:
scrapy fetch http://www.scrapyd.cn就这样,如果你要把它下载的页面保存到一个html文件中进行分析,我们可以使用window或者linux的输出命令,这里演示window下如下如何把下载的页面保存:
scrapy fetch http://www.scrapyd.cn >d:/3.html
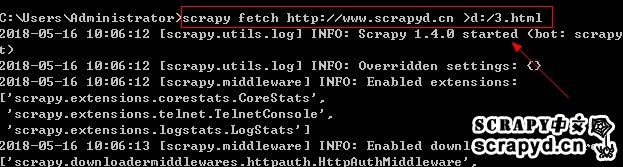
可以看到,经过这个命令,scrapy下载的html文件已经被存储,接下来你就全文找找,看有木有那个节点,木有的话,毫无悬念,使用了异步加载!
七、view
和fetch类似都是查看蜘蛛看到的是否和你看到的一致,便于排错,用法:
scrapy view http://www.scrapyd.cn八、version
不多说,查看scrapy版本,用法:
scrapy version若使用scrpay命令中出现问题,请留言讨论
申明:本文《scrapy命令明细:全局命令》 属于【Scrapy 中文网】原创文章,商业转载请联系作者获得授权,非商业转载请注明出处。















 345
345











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









