






Context-aware Deep Feature Compression for High-speed Visual Tracking 论文地址
写在前面
这是韩国首尔大学2018年CVPR上的一个工作,利用深度特征+相关滤波的形式做的,其中比较新的地方就是设计了一系列encoder来更好编码目标的特征,更加注重目标本身的一些context的信息,论文里面用了很多操作来提升精度。
Motivation
- 近年来越来越多的tracker是使用深度特征+CF的方式,直接迁移过来的深度特征不是很适用,并且CF的tracker会因为特征维度升高而速度变慢;
- 低层的特征更加注重单个物体自身的信息
Contribution
- 提出了一个压缩深度特征的方式,使得CF的tracker速度更快;
- 利用多个自动编码器,每个编码器负责目标的不同类别,并且训练过程是无监督的,根据目标自动选择;
- 效果好并且速度为100fps
Algorithm

这篇文章的anto-encoder(AE)是用不同的context训练的,所以它们有很强的独立的context压缩能力。如上图,他们用了一个Context-aware 网络来在AE池中找到那个最适合当前ROI的encoder,然后在跟踪的时候就用这个找到的encoder来压缩特征。接下来讲一下各个部分具体实现过程。
1 Expert Auto-encoders
这篇文章一共用了
N
e
N_e
Ne 个encoder,这些encoder拥有相同的网络结构,但是每个包含的是不同的Context信息,这些encoder的输入就是从VGG里面提取出来的特征。图中encoder和decoder的结构中特征的分辨率一样但是通道数经过了缩小和放大,然后通过计算decode之后的特征和原始特征相似度的损失来优化网络。注意到这个地方不是简单的用了l2或是交叉熵的损失,而是提出了新的损失函数:
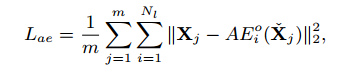
其中
X
j
X_j
Xj代表输入的ROI,
A
E
i
o
AE_i^o
AEio 表示第 i 个encoder 编码出来的东西, m是batch大小。
为了让这些encoder更加适应表观变化和遮挡,他们提出了两个denoise的策略,如下图:

1 随机将某些通道的权重置为0;
2 随机交换某些空间位置上的特征,这种方式可以理解为引入了遮挡,因为把背景的东西交换到目标区域中来。
然后他们发现,这么搞,不能保证每个encoder的训练数据,所以会出现过拟合的情况,所以他们修改了聚类的策略。这里先说一下auto-encoder训练不是用原图训练,而是只是用这个encoder对应的Context来训练的,所以需要先做聚类,然而这样,就会有一些类的特征太少,造成了在这些类别上过拟合。所以他们一开始用kmeans先聚了 2 N e 2N_e 2Ne 类,然后在这些cluster中数量少的 N e N_e Ne个拿出来,再把它们分给剩下的类,最后就得到 N e N_e Ne 类。然后用这些拿去训练encoder就好啦。
2 Context-aware Network
那么有个这么多个encoder,怎么知道哪个才是我们要的呢,这就是这个Context-aware Network该做的事了。这里的Context-aware Network结构就是MDNet的结构,它通过计算当前样本属于每个cluster的概率,概率最大的就是找到的expert encoder。损失就是使得所有的距离都小就可以了:
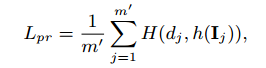
注意到这里的Context-aware网络和上面的encoder网络是分开训练的,作者也说后期可以end-to-end的训练,可能会提高精度。
Tracking process
在跟踪的时候,先在第一帧提取ROI,然后在这些ROI里面加一些blur和flip的数据增强操作,然后用这些ROI来finetune网络。在finetune的时候,他们在损失上加了一个正交的损失,而且是加在filter上面的,加在相关滤波的模板上,说是为了减少训练数据太少造成的一些影响(我也不知道这样为什么可以,可能还需要再研究)。损失函数如下:
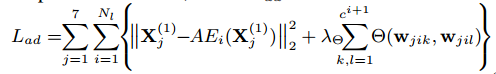
另,他们也对最后输出的特征的一些channel移除掉,用如下的公式:
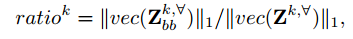
说是当某个通道中对背景高响应的通道的权重设为0,(唉,这篇文章的操作真的太多,不理解了),大概也是防止干扰把。
Online Tracking
在跟踪的时候用的是CF的方式,CF模板更新方式:

这里他们用的是逐channel的做相关操作,然后通过整合各个通道的响应来预测,有点depth convolution的感觉。整合过程用的是各通道加权平均方式:
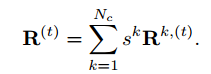
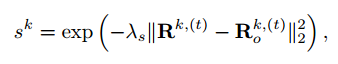
其中
R
o
R_o
Ro 是指在
R
R
R 的最高响应位置的一个高斯型的窗口,也就是当检测出来的响应为高斯型的时候,权重更大。最后就得到了位置,文章里没有提到怎么通过中间点来搞出bbox。
Experiment
在训练的时候,他们用到VOC的数据集来训练,然后在OTB50和OTB100上测试,做了很多ablation实验证明哪个部分最work,具体看论文

总结
感觉就是一篇集大成者,文章中可以看到集成了很多操作,但是比较新颖的应该是他们提出的encoder机制,指导网络选择最合适的encoder,训练的时候很麻烦,但是跟踪的时候却意外得很快。filter解耦也是一个可以参考的机制,还有很佩服的是,他们发现了overfitting之类的问题的时候,并没有放弃,而且坚持找到方法来解决这些问题,很有毅力!我自己要是遇到不work的东西,感觉分分钟就放弃了,毕竟解释性不强,怕怕的。















 1268
1268











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









