






一、Hash表
表就是键值对,存储数据 key –> value;
问题:怎么查找表? 一个一个key去比较查找?这样会导致效率不高。如果有一万个,就算用二分法查找,也要logN次。
解决方案:所以轮到hash表出场。
每个关键字key对应一个存储位置f(key)。查找时,根据这个对应的关系找到给定值key的映射F(key),若查找集合中存在这个记录,则必定在F(key)的位置上。我们把这种对应关系F(key)称为为散列函数,又称为哈希(Hash)函数,Hash函数能使得不同的Key尽量有不同的值(仍然有重复)与之对应。
学术的解释:
Hash,一般翻译做“散列”,也有直接音译为“哈希”的。就是把任意长度的输入(又叫做预映射, pre-image),通过散列算法,变换成固定长度的输出,该输出就是散列值。这种转换是一种压缩映射,也就是说,散列值的空间通常远小于输入的空间,不同的输入可能会散列成相同的输出,而不能从散列值来确定唯一的输入值。简单的说,就是一种将任意长度的消息压缩到某一固定长度的消息摘要的函数。
二、常见hash算法的原理
散列技术将记录存储在一块连续的存储空间中,这块连续空间称为散列表或哈希表(Hash-Table)。总之,对于海量的数据,按照Hash值分成不同的集合,先找集合,再找key–>value,大大提高效率。
举个例子:我们存储70个元素,但我们可能为这70个元素申请了100个元素的空间。70/100=0.7,这个数字称为负载因子。我们之所以这样做,也是为了“快速存取”的目的。我们基于一种结果尽可能随机平均分布的固定函数H为每个元素安排存储位置,这样就可以避免遍历性质的线性搜索,以达到快速存取。但是由于此随机性,也必然导致一个问题就是冲突。所谓冲突,即两个元素通过散列函数H得到的地址相同,那么这两个元素称为“同义词”。这类似于70个人去一个有100个椅子的饭店吃饭。散列函数的计算结果是一个存储单位地址,每个存储单位称为“桶”。设一个散列表有m个桶,则散列函数的值域应为[0,m-1]。
解决冲突是一个复杂问题。
常用的构造散列函数的方法
散列函数能使对一个数据序列的访问过程更加迅速有效,通过散列函数,数据元素将被更快地定位。选用不同的hash算法,会获得不同的查找效果。因为不同的Hash函数会导致分类后的集合不相同
1. 直接寻址法:取关键字或关键字的某个线性函数值为散列地址。
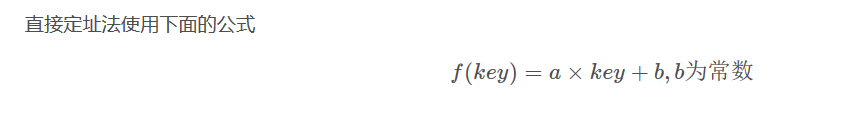
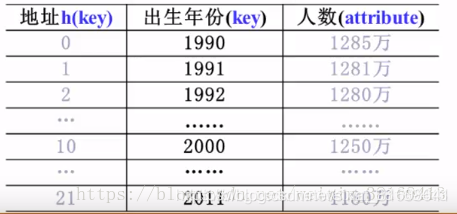
比如统计出生年份,那么就可以使用f(key)=key−1990来计算散列地址
2. 数字分析法:分析一组数据,比如一组员工的出生年月日,这时我们发现出生年月日的前几位数字大体相同,这样的话,出现冲突的几率就会很大,但是我们发现年月日的后几位表示月份和具体日期的数字差别很大,如果用后面的数字来构成散列地址,则冲突的几率会明显降低。因此数字分析法就是找出数字的规律,尽可能利用这些数据来构造冲突几率较低的散列地址。
再举个例子,取手机号前8位做散列地址

3. 平方取中法:取关键字平方后的中间几位作为散列地址。
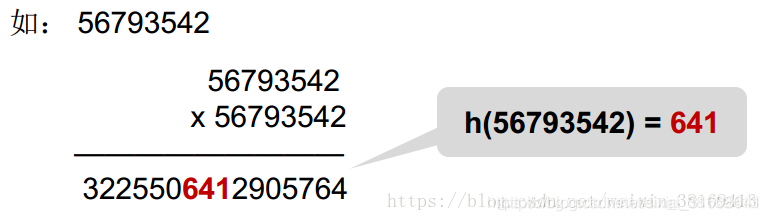
4. 折叠法:将关键字分割成位数相同的几部分,然后取这几部分的叠加和作为散列地址。

5. 除留余数法:取关键字被某个不大于散列表表长m的数p除后所得的余数为散列地址。不仅可以对关键字直接取模,也可在折叠、平方取中等运算之后取模。对p的选择很重要,一般取素数或m,若p选的不好,容易产生同义词。
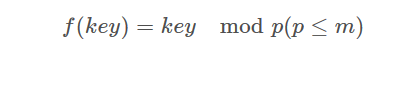
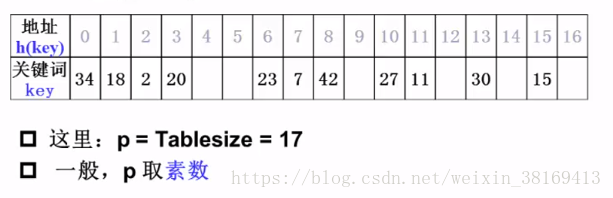
6. 随机数法:选择一随机函数,取关键字的随机值作为散列地址,通常用于关键字长度不同的场合。
三、解决冲突的方案
常用处理冲突的思路:
1、换个位置: 线性探测法
一旦产生了冲突(该地址已有其它元素),就按某种规则去寻找另一空地址.若发生了第 i 次冲突,试探的下一个地址将增加di, 基本公式是:

这里面di 决定了不同的解决冲突方案: 线性探测、平方探测、双散列。具体的方案见链接哈希表的原理和使用

2、同一位置的冲突对象组织在一起: 开链
就是将相应位置上冲突的所有关键词存储在同一个单链表中
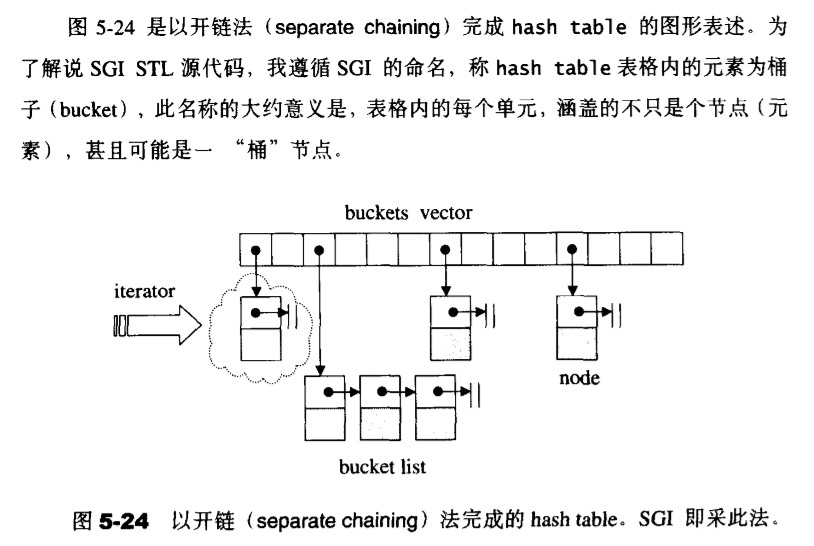
四、Hash表设计
1、key, value节点:
struct hash_node {
char* key;
void* node;
struct hash_node* next;
};2:、hash算法: 选取一种HASH算法;
3、 有限的集合数目, 定义一个集合数目,每个集合的元素用链表连接;
4:、对用户开放的hash表接口;
struct hash_table* creator_hash_table(集合的数目);
void destroy_hash_table(struct hash_table*);
void* hash_find(table, char* key);
hash_delete(table, char* key);
hash_insert(table, char*key, void* value); // 直接插入,不判断是否有key重复;
hash_set(table, char* key, void* value); // 如果key存在就覆盖,如果不存在返回;实例
假设一个键值对,身份证(key)与数据信息(value)。如果我们有10000个学生,查找一个学生的话,很费劲;
如果说有一个办法能均匀的将10000个人分成n个集合,(N100*100)我们有一种办法能快速的找到key,所对应的集合,那么就能很快的在集合里面找出所对应的value;
怎么根据key来分集合;
怎么分能够相对比较均匀;
采用Hash算法
1:将一个字符串变成一个整数 %N规模(0,N-1)的集合序号里面整数 %N = 集合序列号,[0,n-1],用数组来表示每个集合;
2:对于不同的字符串,尽可能的生成不同的Key; Hash散列,要散得足够均匀;
“hello”–>3;
“helmm” –>7;
随机的字符串样本,能均匀的分布出来,分散开来;
参考:
https://blog.csdn.net/qq_36482772/article/details/79191170

















 1735
1735

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









