







 文章介绍了stablediffusion的环境准备和安装,包括模型选择区、功能区域、提示词输入、参数设置区和出图区的详细说明。模型选择涉及stablediffusion模型、VAE模块和Clip跳过层的概念。参数设置如迭代步数、采样方法、面部修复等对图像生成有显著影响。文章还提供了模型获取渠道和提示词的正负向使用,并给出了一个具体的示例来演示如何生成图像。
文章介绍了stablediffusion的环境准备和安装,包括模型选择区、功能区域、提示词输入、参数设置区和出图区的详细说明。模型选择涉及stablediffusion模型、VAE模块和Clip跳过层的概念。参数设置如迭代步数、采样方法、面部修复等对图像生成有显著影响。文章还提供了模型获取渠道和提示词的正负向使用,并给出了一个具体的示例来演示如何生成图像。
上一篇:【AI绘图】二、stable diffusion环境准备与安装
stable diffusion操作界面介绍
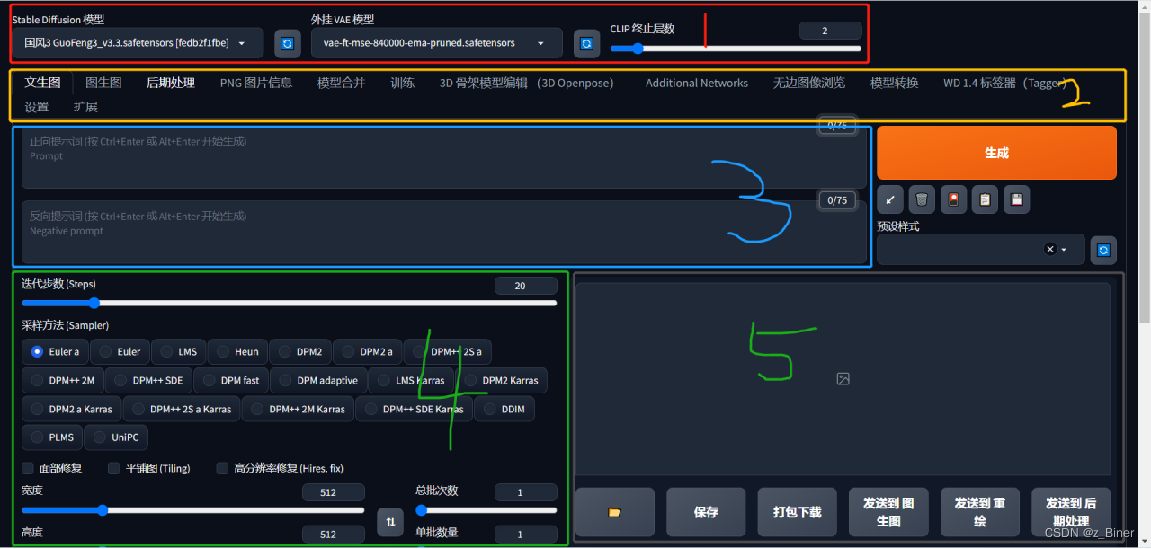
操作界面总共分为5大块
1.模型选择区;点击跳转
2.功能区域;点击跳转
3.提示词输入;点击跳转
4.参数设置区;点击跳转
5.出图区点击跳转
1.模型选择区域介绍

模型选择区域分为三块
stable diffusion模型:经过训练的图片合集,被称作模型,也就是chekpoint,体积较大,一般的单个模型的大小在5GB左右,早期的CKPT后缀名是ckpt,如今新的CKPT后缀名都是safetensors
VAE模块:SD VAE是variable autoencoder的意思,在这里可以选择载入vae组分。使用vae组分可以让图片的色彩变得更好。一般大模型会自带vae,有些则需要自己配置
Clip跳过层:一般默认就好了。原理:prompt最终在模型中使用时,是分层的,对于stable diffusion模型来说,分成了12层。clip skip就是说,我不需要完整的使用这12层,而是跳过其中一些层。跳过的层越多,对细节的控制就越少。下面图可以看出跳过层的参数对图片的影响

比如上面的图中,我们的描述词是face,那么face会有一些细节:眼睛、鼻子、嘴巴的具体形状应该怎么样,肤色应该怎么样等等。我们对比高的clip
skip和低的clip skip,可以发现在clip skip较低时,基本都可以看到脸上的细节,而clip
skip较高时,就比较随机,经常出现类似没有眼珠的这种情况,这是因为没有对细节进行控制,所以细节的随机性会更大。
常用模型介绍:
获取渠道:
1)civitai:俗称C站:
https://civitai.com/models/26580/xsarchitectural-19houseplan2)
huggingface:著名的开源网站,提供模型,但是没有效果图
https://huggingface.co/3)
哩卟哩卟AI:国内的模型网站:
https://www.liblibai.com/#/index/model
2.功能区域介绍

后续教程会对以上功能一一介绍,敬请期待
3.提示语区域

此区域分为两个部分
正向提示:想要图片的信息,比如一只猫
负面提示:不想要的信息,比如 画质低
分享一个网站:咒语生成器
https://www.wujieai.com/tag-generator
人物通用负面提示: low quality,normal quality, worst quality,bad anatomy, extra
breasts,extra nipples,extra hands,bad legs, bad feet,extra feet, bad
fingers,confused fingers, extra fingers,breasts out,
4.参数设置区
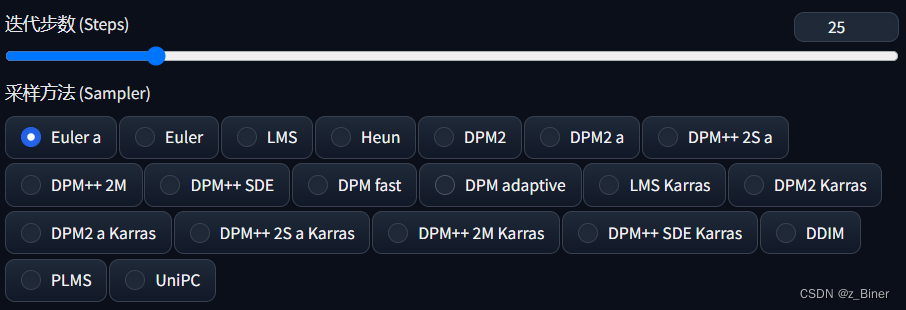
1)迭代步数:
- 此参数控制这些去噪步骤的数量。通常越高越好,但在一定程度上,我们使用的默认值是
25 个步骤。以下是不同情况下使用哪个步骤编号的指南- 如果您正在测试新的提示,并希望获得快速结果来调整您的输入,请使用 10-15 个步骤
- 当您找到您喜欢的提示时,请将步骤增加到 25
- 如果是有毛皮的动物或有纹理的主题,生成的图像缺少一些细节,尝试将其提高到 40
2)采样方法:
建议根据自己使用的 checkpoint 使用脚本跑网格图(用自己关心的参数)然后选择自己想要的结果。
懒得对比:请使用 DPM++ 2M 或 DPM++ 2M Karras(二次元图)或 UniPC,想要点惊喜和变化,Euler a、DPM++ SDE、DPM++ SDE Karras(写实图)、DPM2 a Karras(注意调整对应 eta 值)eta 和 sigma都是多样性相关的,但是它们的多样性来自步数的变化,追求更大多样性的话应该关注 seed 的变化,这两项参数应该是在图片框架被选定后,再在此基础上做微调时使用的参数。

3)面部修复
- 修复人物的面部,但是非写实风格的人物开启面部修复可能导致面部崩坏。
4)平铺:
- 生成一张可以平铺的图像
5)高分辨率修复:
- 使用两个步骤的过程进行生成,以较小的分辨率创建图像,然后在不改变构图的情况下改进其中的细节。
6)长宽尺寸:主要用于生成图片的尺寸
- 长宽尺寸并非数值越大越好,最佳的范围应在 512 至 768 像素之间,比如正方形图多是
512*512和768*768,- 人像肖像
512x768 - 风景画
768×512,可按比例加大或减小
- 人像肖像
- 这个值必须是 8 的倍数。如果不希望主题对象出现重复,应在此范围内选择适当的尺寸。
7)生成批次:每次生成图像的组数。
- 一次运行生成图像的数量为生成批次 * 每批数量。
8)每批数量:同时生成多少个图像。
- 增加这个值可以提高性能,但你也需要更多的 VRAM。图像总数是这个值乘以批次数。除 4090 等高级显卡以外通常保持为 1。
9)提示词相关性 CFG:较高的数值将提高生成结果与提示的匹配度。
-
OpenArt 上使用的默认 CFG 是 7,这在创造力和生成你想要的东西之间提供了最佳平衡。通常不建议低于 5。
-
CFG 量表可以分为不同的范围,每个范围都适合不同的提示类型和目标
-
CFG 2 – 6:有创意,但可能太扭曲,没有遵循提示。对于简短的提示来说,可以很有趣和有用
-
CFG 710:推荐用于大多数提示。创造力和引导一代之间的良好平衡
-
CFG 10-15:当您确定提示是详细且非常清晰的,您希望图像是什么样子时
-
CFG 16-20:除非提示非常详细,否则通常不推荐。可能影响一致性和质量
-
CFG >20:几乎无法使用
10)随机种子(Seed):生成每张图片时的随机种子,这个种子是用来作为确定扩散初始状态的基础。如果选用某个固定的种子序号,则会在当前基础上进行修改
5.出图区
1)保存:可以将生成的图片提供下载链接
2)打包下载:多张图一起下载
3)发送到图生图:将当前生成的图片,发送到图生图进行修改
4)发送到重绘:发送到蒙版重绘
5)发送到后期处理
后续会对每个模块进行单独更加细致的教学,现在我们生成一张图试试
正向提示词:((masterpiece, best quality)), 8k, modern architecture style, photo realistic, david chipperfield, urban design,hyper detailed photo,single,early morning,outdoors, building, green plants,<lora:urbanaerial15_1:1>
负面提示词:signature, soft, blurry, drawing, sketch, poor quality, ugly, text, type, word, logo, pixelated, low resolution, saturated, high contrast, oversharpened,Fuzzy structure
使用的模型:realisticVisionV13_v13
lora:urbanaerial15_1.safetensors
使用功能:图生图
原图:

生成的图:





















 4528
4528

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









