







发现简书上有些文章还挺不错,页面如下:
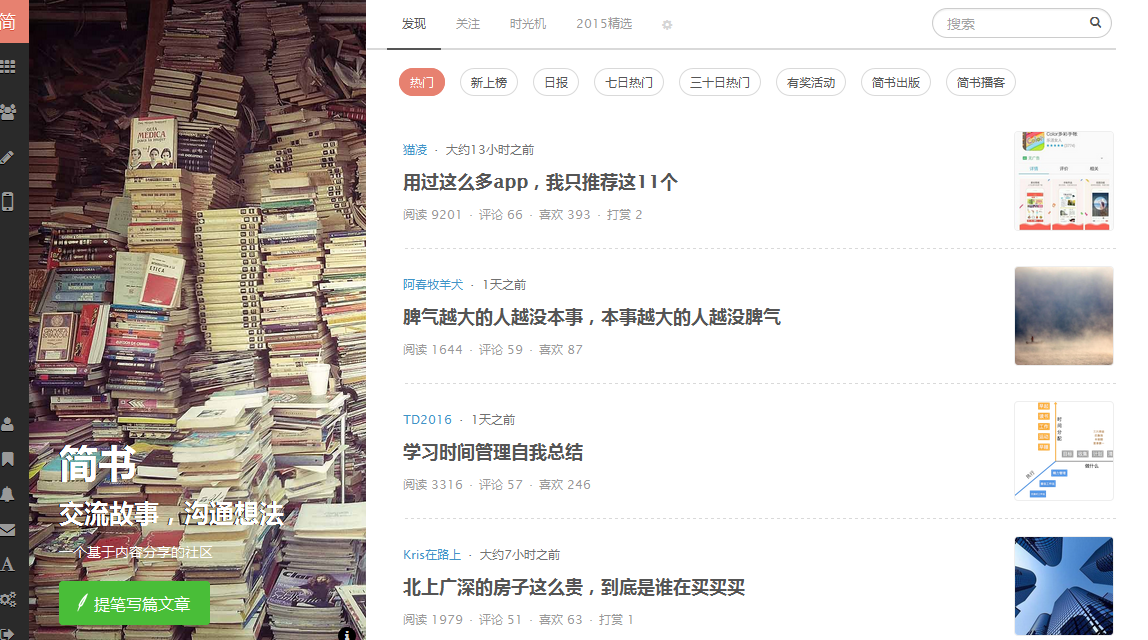
然后就手痒写了几行代码,用xpath匹配的方法将首页推荐的文章的内容抓了下来,它有一个“显示更多的按钮”,每次click一下,就会再出现一些内容,这次我设置的是抓了4次更多。
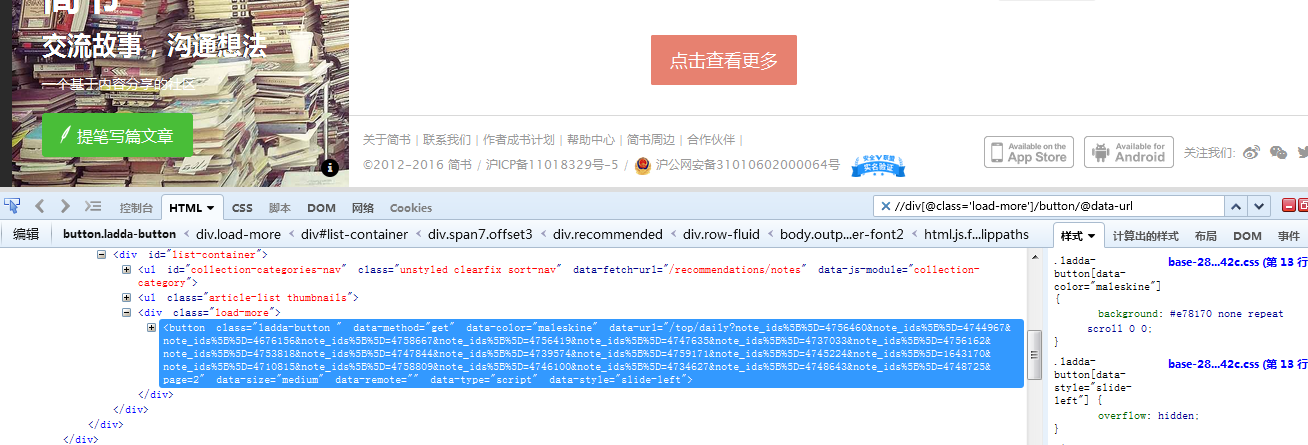
之后就是保存在本地了,代码不多,但是还算实用,只是没有将文章里的图片给配套爬取。
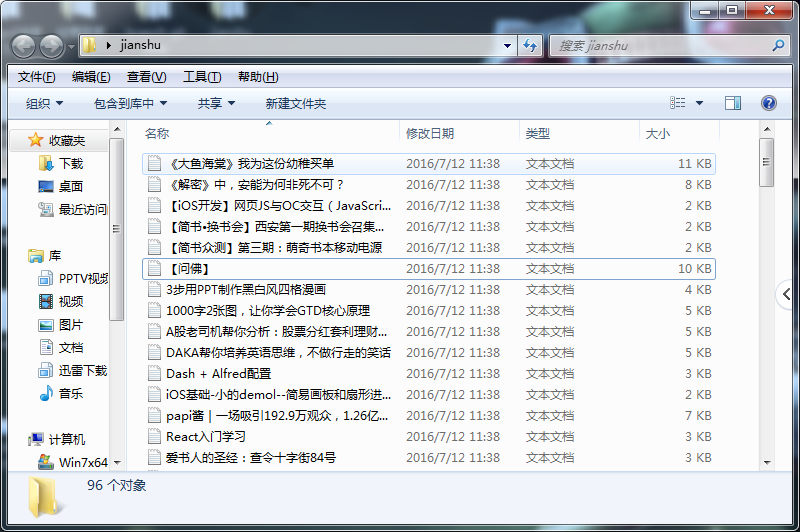
代码如下:
package qita;
import java.io.IOException;
import java.util.Vector;
import java.io.FileWriter;
import com.hpre.spider.common.Function;
import com.hpre.spider.tools.Tools;
public class Download_jianshu {
public static void main(String[] args) throws IOException {
String url = "http://www.jianshu.com/";
byte[] information = Function.download(url);
// System.out.println(new String(information));
Vector<String> hrefs = new Vector<String>();
Vector<String> title = new Vector<String>();
Vector<String> tiaoye = new Vector<String>();
FileWriter writer;
Tools.getMultiResultsByOneXpathPattern(information, "utf-8",
"//div[@class='load-more']/button/@data-url", tiaoye);
Tools.getMultiResultsByOneXpathPattern(information, "utf-8",
"//div[@id='list-container']//li[@class='have-img']/div/h4/a/text()", title);
Tools.getMultiResultsByOneXpathPattern(information, "utf-8",
"//div[@id='list-container']//li[@class='have-img']/div/h4/a/@href", hrefs);
for (int j = 0 ;j<tiaoye.size()&&j<=4;j++){
String page_url = url + tiaoye.get(j);
byte[] more_information = Function.download(page_url);
Tools.getMultiResultsByOneXpathPattern(more_information, "utf-8",
"//div[@class='load-more']/button/@data-url", tiaoye);
Tools.getMultiResultsByOneXpathPattern(more_information, "utf-8",
"//div[@id='list-container']//li[@class='have-img']/div/h4/a/text()", title);
Tools.getMultiResultsByOneXpathPattern(more_information, "utf-8",
"//div[@id='list-container']//li[@class='have-img']/div/h4/a/@href", hrefs);
}
for (int i = 0;i<hrefs.size();i++){
Vector<String> content = new Vector<String>();
String new_href = url + hrefs.get(i);
byte[] detail_information = Function.download(new_href);
Tools.getMultiResultsByOneXpathPattern(detail_information, "utf-8",
"//div[@class='show-content']//p/text()", content);
System.out.println(content.toString());
writer = new FileWriter("C://Users//Administrator//Desktop//jianshu//"+title.get(i).trim().replace("|", "")
.replace("?", "")+".txt");
for (int n = 0;n<content.size();n++){
String lines = content.get(n).trim() + "\r\n";
writer.write(lines);
}
writer.flush();
writer.close();
}
}
}















 3780
3780











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









