







研究背景
知识图谱补全(KGC)是通过预测知识图谱中缺失的三元组来完善知识图谱的信息。传统方法主要基于嵌入和预训练语言模型,但这些方法往往忽视了知识图谱的结构信息,导致预测效果不佳。
研究目标
本文的研究目标是探索如何将结构信息融入大型语言模型(LLM),以提高其在知识图谱补全任务中的表现。具体来说,是通过结构嵌入预训练和知识前缀适配器(KoPA)来实现结构信息的有效利用。
相关工作
嵌入方法:通过将实体和关系嵌入到连续的向量空间中来预测三元组的可信度。
基于PLM的方法:将知识图谱补全任务视为文本生成任务,通过微调预训练的语言模型来处理。
方法论
数据处理
结构嵌入预训练:
从知识图谱中提取所有的三元组(头实体,关系,尾实体),对每个实体和关系生成描述文本,这些描述可以是从知识图谱中直接提取的简短描述或者相关文档。对应项目中没有给出相应数据示例,而是直接给出了embedding模型。推测训练数据构成如下:
Prompt:爱因斯坦是什么学家?
Pos answer:爱因斯坦是著名的物理学家。他对理论物理学做出了巨大贡献,包括相对论的发展等。
Neg answer:爱因斯坦是著名的化学家。他在化学领域的研究改变了我们对化学物质的理解。
指令调优来微调LLM:

解决方案
首先通过结构嵌入预训练提取KG中实体和关系的结构信息,然后通过结构前缀适配器将这些信息注入输入序列。这种方法避免了将KG的结构信息以文本形式表示所带来的无效或冗余信息。
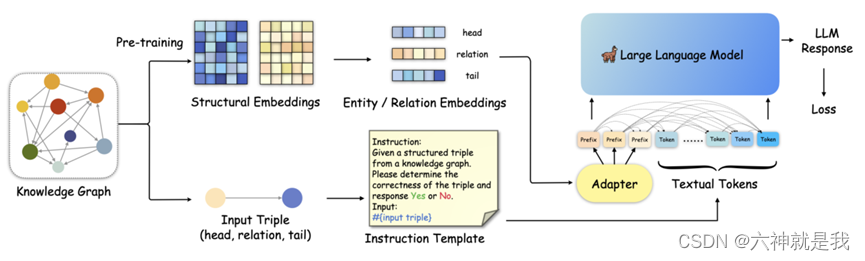
- 结构嵌入预训练,与基于嵌入的KGC方法相反,KoPA从KG中提取实体和关系的结构信息,并将其适应到LLM的文本表示空间中。使用负采样的自监督预训练目标定义得分函数 ( F(h,r,t) ) 来衡量三元组的合理性。通过最小化这种预训练损失,实体和关系的结构嵌入被优化以适应所有相关的三元组。
- 在完成结构嵌入预训练后,通过知识前缀适配器将结构嵌入转换为虚拟知识Token。这些Token作为输入序列的前缀,由于解码器仅在LLM中的单向注意力,所有后续的文本Token都可以看到这些前缀。这样,文本Token可以对输入三元组的结构嵌入进行单向注意,从而在微调和推理期间实现结构感知提示。
实验
实验设计
在三个公开的知识图谱基准数据集上进行实验,包括UMLS、CoDeX-S和FB15K-237N,UMLS是一个经典的医学知识图谱,CoDeX-S是从Wikidata中提取的百科全书式KG,FB15K-237N是从FB15K-237修改而来。
实验比较了KoPA方法与三类基线模型:基于嵌入的方法、基于PLM的方法和基于LLM的方法。对于所有基于LLM的方法,使用Alpaca-7B作为LLM的主干。KoPA使用RotatE和结构嵌入预训练的得分函数,适配器是一个512×4096的线性投影层。
实验结论
- KoPA在所有三个数据集上的准确率和F1得分均优于现有的16种基线模型。与其他基于LLM的方法相比,KoPA表现出更好的结构信息理解能力,尤其在更大、更具挑战性的数据集上表现突出。
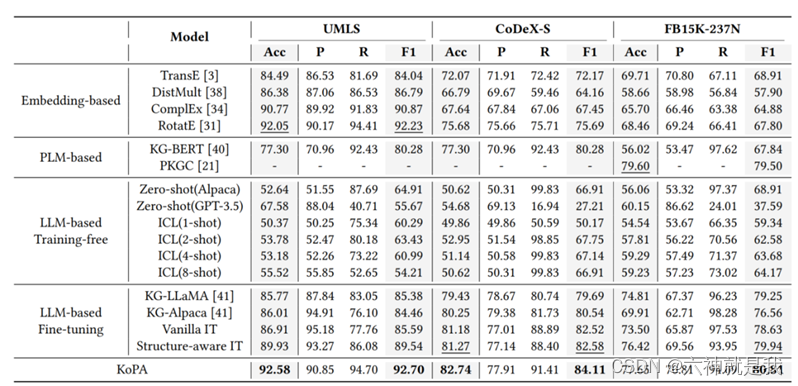
- 通过实验验证了KoPA在处理未见实体时的稳健性和优越性,表明其适配器能够有效地将结构知识转换为有助于推理的文本信息。
- 验证了结构嵌入和知识前缀适配器的有效性,显示了在输入序列前端添加虚拟知识标记的设计合理性。















 13万+
13万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









