







本章是对推荐算法进行python实战,也是第一次用到较大的数据集,利用python对数据库进行连接。
本文主要分为以下几个部分:
- 数据库连接
- 逐块统计
- 数据清洗
- 数据转换
- 网页分类
- 模型构建
- 总结
数据库连接
在python里,数据库连接主要需要SQLALchemy和PyMySQL,安装完所需的库就可以利用pandas直接read_sql()。
在此之前,需要先将本章所需的数据集导入数据库,在MySQL WorkBench里打开新的SQL Script,一定要选择RUN SQL Script,而不是Open,因为文件太大,选择打开会很久很久。。。。。。且可能崩溃。
然后就可以利用pandas进行数据导入了。
代码如下:
import pandas as pd
#连接数据库
from sqlalchemy import create_engine
#用create_engine建立连接,连接地址的意思依次为“数据库格式(mysql)+程序名(pymysql)+账号密码@地址端口/数据库名(test)”,最后指定编码为utf8;
engine=create_engine('mysql+pymysql://username:password@127.0.0.1:3306/test?charset=utf8')
#all_gzdata是表名,engine是连接数据的引擎,chunksize指定每次读取1万条记录。这时候sql是一个容器,未真正读取数据
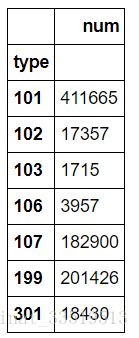
sql=pd.read_sql('all_gzdata',engine,chunksize=10000)逐块统计
上述代码中的sql只是一个容易,并没有真正读取数据,接下来可通过这个容器进行逐块读取数据并统计不同类型网页的数量。
代码如下:
#逐块统计
counts = [ i['fullURLId'].value_counts() for i in sql]
counts = pd.concat(counts).groupby(level=0).sum() #合并统计结果,把相同的统计项合并(即按index分组并求和)
counts = counts.reset_index() #重新设置index,将原来的index作为counts的一列。
counts.columns = ['index', 'num'] #重新设置列名,主要是第二列,默认为0
counts['type'] = counts['index'].str.extract('(\d{3})') #提取前三个数字作为类别id
counts_ = counts[['type', 'num']].groupby('type').sum() #按类别合并
counts_.sort_values('num', ascending = False) #降序排列
输出结果如下:
本章所有的前期统计,即探索性分析,都是如此逐块统计的,比如统计107网页类别的情况代码如下:
#统计107类别的情况
def count107(i): #自定义统计函数
j = i[['fullURL']][i['fullURLId'].str.contains('107')].copy() #找出类别包含107的网址
j['type'] = None #添加空列
j['type'][j['fullURL'].str.contains('info/.+?/')] = u'知识首页'
j['type'][j['fullURL'].str.contains('info/.+?/.+?')] = u'知识列表页'
j['type'][j['fullURL'].str.contains('/\d+?_*\d+?\.html')] = u'知识内容页'
return j['type'].value_counts()
counts2 = [count107(i) for i in sql] #逐块统计
counts2 = pd.concat(counts2).groupby(level=0).sum() #合并统计结果结果如下:

需要注意的是,第一步连接数据库并读取的过程在每一步统计时都要重新运行一遍,否则会报错sql(容器)没有定义。
其他类别的统计跟上面差不多,此处不再赘述。
数据清洗
关于网页的数据有许多内容是无用的,因此需要删去。书中很多意思本人没有完全理解,只能按照自己理解的部分将包含“快车-律师助手”、“咨询发布成功”、 “法律快搜”、“免费发布咨询”、“midques_”以及其他(199)页面的含有?的数据删去。删去之后再删除重复数据,并只保留网址列。
同时,根据分析目标以及探索结果,咨询与知识是其主要业务来源,故需筛选咨询与知识相关的记录。
最后将清洗之后的数据存入数据库。
代码如下:
# -*- coding: utf-8 -*-
import pandas as pd
#连接数据库
from sqlalchemy import create_engine
#用create_engine建立连接,连接地址的意思依次为“数据库格式(mysql)+程序名(pymysql)+账号密码@地址端口/数据库名(test)”,最后指定编码为utf8;
engine=create_engine('mysql+pymysql://username:password@127.0.0.1:3306/test12?charset=utf8')
#all_gzdata是表名,engine是连接数据的引擎,chunksize指定每次读取1万条记录。这时候sql是一个容器,未真正读取数据
sql=pd.read_sql('all_gzdata',engine,chunksize=10000)
###数据清洗
for i in sql:
a=i['pageTitle'].str.contains(u'快车-律师助手')
b=i['pageTitle'].str.contains(u'咨询发布成功')
c=i['pageTitle'].str.contains(u'法律快搜')
d=i['pageTitle'].str.contains(u'免费发布咨询')
e=i['fullURL'].str.contains('midques_')
f=i['fullURLId'].str.contains('199')
g=i['fullURL'].str.contains('\?')
#删去其他类别中含?的行
j=i[(f==False)|(g==False)].copy()
j=j[(a==False)&(b==False)&(c==False)&(d==False)&(e==False)].copy()
#删除重复列
j.drop_duplicates(['userID','timestamp_format','fullURL'])
d=j[['realIP','fullURL']]#只要网址列
#包含关键字且以html结尾
d=d[d['fullURL'].str.contains('\.html')&d['fullURL'].str.contains('lawtime')].copy()
#保存到数据库的cleaned_gzdata表中(表不存在将自动创建)
d.to_sql('cleaned_gzdata',engine,index=False,if_exists='append')这个数据清洗还是有些粗略,书上也并没有完全的清洗代码,暂且当清洗完毕。
数据转换
数据转换过程主要是将翻页网址转换成原始网址,即将包含下划线的网址的下划线后面部分去掉,然后再针对每个用户访问的页面进行去重操作,最后存入数据库。
代码如下:
# -*- coding: utf-8 -*-
import pandas as pd
#连接数据库
from sqlalchemy import create_engine
#用create_engine建立连接,连接地址的意思依次为“数据库格式(mysql)+程序名(pymysql)+账号密码@地址端口/数据库名(test)”,最后指定编码为utf8;
engine=create_engine('mysql+pymysql://username:password@127.0.0.1:3306/test12?charset=utf8')
#all_gzdata是表名,engine是连接数据的引擎,chunksize指定每次读取1万条记录。这时候sql是一个容器,未真正读取数据
sql=pd.read_sql('cleaned_gzdata',engine,chunksize=10000)
###数据变换
for i in sql:
d=i.copy()
d['fullURL']=d['fullURL'].str.replace('_\d{0,2}.html','.html')#将下划线后面部分去掉,规范为标准网址
d['fullURL']=d['fullURL'].str.replace('\?\&from=.*','')
d=d.drop_duplicates()
d.to_sql('changed_gzdata',engine,index=False,if_exists='append')上述代码直接参照的书上所提供的代码,这部分相较前面的数据清洗要简单一些。
网页分类
网页大类分为知识类别与咨询类别,再此基础上,需要再对网址进行手动分类,比如网址中包含’ask’/’askzt’的为咨询类,包含’zhishi’/’faguizt’的为知识类,再往下还可以分,比如网址中包含’faguizhuanti’的将其类别2归为法规专题。
具体可以分类三个类别,如下图:

通过对原始网站进行查看,此处包含的类别实在太多,书上所提供的代码只分了第一个类别,本文又将一些明显的分了第二个类别,其他的也没有继续分下去。
代码如下:
# -*- coding: utf-8 -*-
import pandas as pd
import warnings
warnings.filterwarnings('ignore')
#连接数据库
from sqlalchemy import create_engine
#用create_engine建立连接,连接地址的意思依次为“数据库格式(mysql)+程序名(pymysql)+账号密码@地址端口/数据库名(test)”,最后指定编码为utf8;
engine=create_engine('mysql+pymysql://username:password@127.0.0.1:3306/test?charset=utf8')
#all_gzdata是表名,engine是连接数据的引擎,chunksize指定每次读取1万条记录。这时候sql是一个容器,未真正读取数据
sql=pd.read_sql('changed_gzdata',engine,chunksize=10000)
for i in sql: #逐块变换并去重
d = i.copy()
d['type_1'] = d['fullURL'] #复制一列
d['type_2'] = d['fullURL']
d['type_1'][d['fullURL'].str.contains('(ask)|(askzt)')] = u'咨询类' #将含有ask、askzt关键字的网址的类别一归为咨询
d['type_1'][d['fullURL'].str.contains('(zhishi)|(faguizt)')]=u'知识类'
d['type_2'][d['fullURL'].str.contains('faguizt')]=u'法规专题'
d['type_2'][d['fullURL'].str.contains('guojia')]=u'国家赔偿'
d['type_2'][d['fullURL'].str.contains('minshi')]=u'民事'
d['type_2'][d['fullURL'].str.contains('shuifa')]=u'税法'
d['type_2'][d['fullURL'].str.contains('jiaotong')]=u'交通法'
d['type_2'][d['fullURL'].str.contains('hunyin')]=u'婚姻法'
#......应还有其他类别
d.to_sql('splited_gzdata', engine, index = False, if_exists = 'append') #保存模型构建
本次实验所用的算法为协同过滤中的基于物品的过滤,即将哪个物品推荐给某个用户。关于协同过滤算法,网上有许多资料,此处不再另外说明。
本书中所给的协同过滤算法代码如下:
import numpy as np
def Jaccard(a, b): #自定义杰卡德相似系数函数,仅对0-1矩阵有效
return 1.0*(a*b).sum()/(a+b-a*b).sum()
class Recommender():
sim = None #相似度矩阵
def similarity(self, x, distance): #计算相似度矩阵的函数
y = np.ones((len(x), len(x)))
for i in range(len(x)):
for j in range(len(x)):
y[i,j] = distance(x[i], x[j])
return y
def fit(self, x, distance = Jaccard): #训练函数
self.sim = self.similarity(x, distance)
return self.sim#必须有return
def recommend(self, a): #推荐函数
return np.dot(self.sim, a)*(1-a)
仅以婚姻知识类作为例子,利用上述函数进行模型构建。
提取数据
首先,将经过网页分类之后的数据库中所有包含婚姻关键字的数据提取出来。代码如下:
# -*- coding: utf-8 -*-
import pandas as pd
#连接数据库
from sqlalchemy import create_engine
#用create_engine建立连接,连接地址的意思依次为“数据库格式(mysql)+程序名(pymysql)+账号密码@地址端口/数据库名(test)”,最后指定编码为utf8;
engine=create_engine('mysql+pymysql://username:password@127.0.0.1:3306/test?charset=utf8')
#all_gzdata是表名,engine是连接数据的引擎,chunksize指定每次读取1万条记录。这时候sql是一个容器,未真正读取数据
sql=pd.read_sql('splited_gzdata',engine,chunksize=10000)
def hunyin(i): #逐块变换并去重
j = i.copy()
j=j[['realIP','fullURL']][j['fullURL'].str.contains('hunyin')]
return j
hunyin = [hunyin(i) for i in sql] #逐块
hunyin= pd.concat(hunyin) #合并统计结果
#删除重复列
hunyin.drop_duplicates()#16642 rows × 2 columns最后数据如下:

0-1矩阵转换
然后,将数据转换成0-1指标矩阵,因为以所有的数据进行转换总是出错,因此取了1000个记录。
代码如下:
#将数据转换成指标矩阵
import pandas as pd
import numpy as np
import time
start=time.clock()
hunyin=hunyin[:1000]
hunyin.sort_values(by=['realIP','fullURL'],ascending=[True,True],inplace=True)
realIP = hunyin['realIP'].value_counts().index
realIP = np.sort(realIP)
fullURL = hunyin['fullURL'].value_counts().index #
fullURL = np.sort(fullURL)
data=DataFrame([],index=realIP,columns=fullURL)
for i in range(len(hunyin)):
p1=hunyin.iloc[i,0]
p2=hunyin.iloc[i,1]
data.loc[p1,[p2]]=1
data=data.fillna(0)
end=time.clock()
print ('所用时间为:{}'.format(end-start))
很奇怪,1000个记录用了不到10秒的时间,但是所有数据一起却总是无法输出(应该是需要非常长的时间。。。。。。)。
交叉验证
然后,将数据随机打乱之后分成训练集和测试集,两者比例为9:1,代码如下:
df = data.copy()
simpler = np.random.permutation(len(df))
df = df.take(simpler)# 打乱数据
train = df.iloc[:int(len(df)*0.9), :]
test = df.iloc[int(len(df)*0.9):, :]
df = df.as_matrix()
df_train = df[:int(len(df)*0.9), :]
df_test = df[int(len(df)*0.9):, :]
#由于基于物品的推荐,对于矩阵,根据上面的推荐函数,index应该为网址(即计算网址间的相似度),因此需要进行转置
df_train = df_train.T
df_test = df_test.T模型训练
最后,利用书中函数进行模型训练,计算相似度矩阵,代码如下:
# 建立相似矩阵,训练模型
import time
start1 = time.clock()
r = Recommender()
sim = r.fit(df_train)# 计算物品的相似度矩阵
end1 = time.clock()
a = DataFrame(sim) # 保存相似度矩阵
usetime1 = end1-start1
print (u'建立相似矩阵耗时'+str(usetime1)+'s!' ) #5.345645981682992s
print (a.shape)#(537, 537)
推荐
接下来利用测试集,针对每个用户进行推荐,代码如下:
# 使用测试集进行预测
print( df_test.shape )
start2 = time.clock()
result = r.recommend(df_test)
end2 = time.clock()
result1 = DataFrame(result)
usetime2 = end2-start2
print (u'推荐函数耗时'+str(usetime2)+'s!')
result1结果输出如下所示:

为了查看,将结果的index和column转换成对应的网址的IP。代码如下:
# 将推荐结果表格中的对应的网址和用户名对应上
result1.index = test.columns
result1.columns = test.index结果如下图:

最后需要得到的结果应该是针对每个用户的推荐网址,因此,建立函数输出最应该推荐给用户的网址。函数代码如下:
# 定义展现具体协同推荐结果的函数,K为推荐的个数,recomMatrix为协同过滤算法算出的推荐矩阵的表格化
def xietong_result(K, recomMatrix ):
recomMatrix.fillna(0.0,inplace=True)# 将表格中的空值用0填充
n = range(1,K+1)
recommends = ['xietong'+str(y) for y in n]#推荐网址列名
currentemp = DataFrame([],index = recomMatrix.columns, columns = recommends)
for i in range(len(recomMatrix.columns)):
temp = recomMatrix.sort_values(by = recomMatrix.columns[i], ascending = False)#降序排列,从最上面开始取网址就行了。
k = 0
while k < K:
currentemp.iloc[i,k] = temp.index[k]
if temp.iloc[k,i] == 0.0:#没有点击过相关网址
currentemp.iloc[i,k:K] = np.nan
break
k = k+1
return currentemp应用函数,输出网址,代码如下:
start3 = time.clock()
xietong_result = xietong_result(3, result1)
end3 = time.clock()
print ('按照协同过滤推荐方法为用户推荐3个未浏览过的网址耗时为' + str(end3 - start3)+'s!')
xietong_result # 结果中出现了全空的行,这是冷启动现象输出结果如下图:

总结
本章学习并没有完成的很好,大概是第一次用到这样有些乱又多的数据,最后的模型构建也是折腾了好久又参考小伙伴的才勉强出来,主要是对推荐函数里的recommend结果理解不够。感觉还是要好好地再对推荐算法以及数据处理(特别是转换成0-1矩阵)做一个深入了解与实践。但最后也总算是搞出来了,也算是对数据库以及推荐系统有了一个了解。















 5568
5568

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









