







本文是对《Python数据分析与挖掘实战》实战篇第一部分——电力窃漏电用户自动识别中上机实验的一个记录。
实验分为两个部分:
- 利用拉格朗日插值法进行缺失值的补充
- 构建分类模型对窃漏电用户进行识别
第一部分:利用拉格朗日插值法进行缺失值的补充
**(1)拉格朗日插值法公式理解**
本书中,缺失值处理所用的方法是拉格朗日插值法。因此,在应用之前,本人先去查阅了拉格朗日插值法的相关资料,对拉格朗日插值法的公式进行了一个理解。
首先是插值函数的定义:
已知精确函数y=f(x)在一系列节点x0,x1…xn处测得函数值y0=f(x0),y1=f(x1)…yn=f(xn),由此构造一个简单易算的近似函数p(x),满足条件p(xi)=f(xi),(i=0,1…n),这里的p(x)成为f(x)的插值函数。
当插值函数为n次多项式时,则为拉格朗日插值函数,即存在n次多项式
pn(x)=a0+a1x+a2x2+...+anxn
,使得
pn(xi)=f(xi)
由Vanderode行列式可知 pn(x) 存在且唯一。
即有定理一:
给定n+1不同的点 x0,x1...xn∈[a,b]和n+1个值y0,y1,…yn∈R ,存在一个唯一的次数不超过n的多项式 Pn ,满足 pn(xi)=yi,i=0,1...n.
当n=1时,
p1(x)
即过两点
(x0,y0),(x1,y1)
的直线,由两点式可得:
当n=2时, p2(x) 即过三点 (x0,y0),(x1,y1),(x2,y2) 的抛物线,由n=1的结果不如将 p2(x)设为∑ni=0li(x)yi 形式,即设
将三点代入,式子显然是成立的,这个式子称为二次式。
由此可见对于任意n,可设:
则,当 x=xi 时,显然除了 (x−x1xi−x1)(x−x2xi−x2)…(x−xi−1xi−xi−1)(x−xi+1xi−xi+1)(x−xnxi−xn) 这一项为1外,其他项都为0,即,此时, pn(xi)=1∗yi=yi ,因此,将n+1个点代入,式子显然是成立的。
这便是拉格朗日插值法的公式了。
综上所述,拉格朗日插值法的公式为:
所以,拉格朗日插值法本质上是利用多项式函数对缺失值进行补充。
**(2)利用Python对拉格朗日插值法进行应用**
首先是将缺失数据导入:
import pandas as pd
#读入数据
data=pd.read_excel('C:/Python27/Lib/site-packages/xy/chapter6/test/data/missing_data.xls',header=None)缺失数据如下:
| 0 | 1 | 2 |
|---|---|---|
| 235.8333 | 324.0343 | 478.3231 |
| 236.2708 | 325.6379 | 515.4564 |
| 238.0521 | 328.0897 | 517.0909 |
| 235.9063 | NaN | 514.8900 |
| 236.7604 | 268.8324 | NaN |
| NaN | 404.0480 | 486.0912 |
| 237.4167 | 391.2652 | 516.2330 |
| 238.6563 | 380.8241 | NaN |
| 237.6042 | 388.0230 | 435.3508 |
| 238.0313 | 206.4349 | 487.6750 |
| 235.0729 | NaN | NaN |
| 235.5313 | 400.0787 | 660.2347 |
| NaN | 411.2069 | 621.2346 |
| 234.4688 | 395.2343 | 611.3408 |
| 235.5000 | 344.8221 | 643.0863 |
| 235.6354 | 385.6432 | 642.3482 |
| 234.5521 | 401.6234 | NaN |
| 236.0000 | 409.6489 | 602.9347 |
| 235.2396 | 416.8795 | 589.3457 |
| 235.4896 | NaN | 556.3452 |
| 236.9688 | NaN | 538.3470 |
针对读入数据的每一列,参考书中的拉格朗日插值算法进行编程。
代码如下:
###利用拉格朗日插值法进行缺失值的补充
#导入lagrange函数
from scipy.interpolate import lagrange
#构建插值函数,默认取缺失值前5个和后五个值作为参考进行插值
def ployinterp_column(s,n,k=5):
#取数,默认取10个数
y=s[list(range(n-k,n))+list(range(n+1,n+1+k))]
#剔除空值,即取数过程中若发现有空值则直接舍去,以剩下的数据为参考
y=y[y.notnull()]
#插值并返回插值结果
return lagrange(y.index,list(y))(n)
#逐个元素判断是否需要插值
for i in data.columns:
for j in range(len(data)):
if (data[i].isnull())[j]: #如果为空即插值
data[i][j] = ployinterp_column(data[i], j)
#将插值之后的数据导出
data.to_excel('C:/Python27/Lib/site-packages/xy/chapter6/test/data/missing_data_out.xls', header=None, index=False) 导出之后的数据如下,标黑为补上的缺失值。
| 0 | 1 | 2 |
|---|---|---|
| 235.8333 | 324.0343 | 478.3231 |
| 236.2708 | 325.6379 | 515.4564 |
| 238.0521 | 328.0897 | 517.0909 |
| 235.9063 | 203.462116 | 514.8900 |
| 236.7604 | 268.8324 | 493.352591 |
| 237.151181 | 404.0480 | 486.0912 |
| 237.4167 | 391.2652 | 516.2330 |
| 238.6563 | 380.8241 | NaN |
| 237.6042 | 388.0230 | 435.3508 |
| 238.0313 | 206.4349 | 487.6750 |
| 235.0729 | 237.348072 | 609.193564 |
| 235.5313 | 400.0787 | 660.2347 |
| 235.314951 | 411.2069 | 621.2346 |
| 234.4688 | 395.2343 | 611.3408 |
| 235.5000 | 344.8221 | 643.0863 |
| 235.6354 | 385.6432 | 642.3482 |
| 234.5521 | 401.6234 | 618.197198 |
| 236.0000 | 409.6489 | 602.9347 |
| 235.2396 | 416.8795 | 589.3457 |
| 235.4896 | 420.748600 | 556.3452 |
| 236.9688 | 408.963200 | 538.3470 |
**(3)拉格朗日插值与Series自带.interpolate方法的对比**
除了拉格朗日插值法,Pandas的Series自带的.interpolate方法也可以对缺失值进行填充。
因此,这里,再利用.interpolate()对缺失值进行补充,以做一个对比。
代码如下:
import pandas as pd
from pandas import Series
#读入数据
data=pd.read_excel('C:/Python27/Lib/site-packages/xy/chapter6/test/data/missing_data.xls',header=None)
###利用Pandas中interpolate进行缺失值的补充
data_out=data.interpolate()
data_out.to_excel('C:/Python27/Lib/site-packages/xy/chapter6/test/data/missing_data_out_2.xls', header=None, index=False) 结果对比如下,括号里为interpolate方法的填充结果。
interpolate方法的默认填补模型为线性模型,因此可以看出,其填充的值基本介于前一个值和后一个值之间,而拉格朗日插值法是将前后五个数总共10个数作为参考组,所以结果是受更多值的影响。同时通过第二列最后两个数据可以看出,当有两个连续缺失值的时候,interpolate的两个结果就都与前一个数相同,显然,拉格朗日插值法遇到连续缺失值时所受影响会小一些。
| 0 | 1 | 2 |
|---|---|---|
| 235.8333 | 324.0343 | 478.3231 |
| 236.2708 | 325.6379 | 515.4564 |
| 238.0521 | 328.0897 | 517.0909 |
| 235.9063 | 203.462116(298.46105) | 514.8900 |
| 236.7604 | 268.8324 | 493.352591(500.49060) |
| 237.151181(237.08855) | 404.0480 | 486.0912 |
| 237.4167 | 391.2652 | 516.2330 |
| 238.6563 | 380.8241 | 493.342382( 475.79190) |
| 237.6042 | 388.0230 | 435.3508 |
| 238.0313 | 206.4349 | 487.6750 |
| 235.0729 | 237.348072(303.25680) | 609.193564(573.95485) |
| 235.5313 | 400.0787 | 660.2347 |
| 235.314951(235.00005) | 411.2069 | 621.2346 |
| 234.4688 | 395.2343 | 611.3408 |
| 235.5000 | 344.8221 | 643.0863 |
| 235.6354 | 385.6432 | 642.3482 |
| 234.5521 | 401.6234 | 618.197198( 622.64145) |
| 236.0000 | 409.6489 | 602.9347 |
| 235.2396 | 416.8795 | 589.3457 |
| 235.4896 | 420.748600(416.87950) | 556.3452 |
| 236.9688 | 408.963200(416.87950) | 538.3470 |
第二部分:构建分类模型对窃漏电用户进行识别
书中对窃漏电用户进行识别用了两个模型,一个是LM神经网络模型,另一个是CART决策树模型。由于本人安装keras一直出错,因此,LM神经网络模型试验失败,打算先将这一块放放,只尝试CART决策树模型。
**(1)CART决策树模型算法**
关于CART决策树模型算法的分析,本人主要通过以下两个博客的文章做了一个简单的了解:
决策树之CART算法
机器学习经典算法详解及Python实现–CART分类决策树、回归树和模型树
**(2)Python实现CART决策树模型算法**
从Python的科学计算库——sklearn中可以直接导入DecisionTreeClassifier决策树模型
代码如下:
###构建并测试CART决策树模型
#导入决策树模型
from sklearn.tree import DecisionTreeClassifier 在做模型训练之前,首先需要将数据划分为训练数据和测试数据,本文将80%数据用来训练,20%用来测试。样本总量为291,数据基本特征如下:
| 电量趋势下降指标 | 线损指标 | 告警类指标 | 是否窃漏电 |
|---|---|---|---|
| 4 | 1 | 1 | 1 |
| 4 | 0 | 4 | 1 |
| 2 | 1 | 1 | 1 |
| 9 | 0 | 0 | 0 |
| … | … | … | … |
数据划分代码如下:
###数据划分
#导入随机函数,用来打乱数据
from random import shuffle
#将模型的数据导入
data=pd.read_excel('C:/Python27/Lib/site-packages/xy/chapter6/test/data/model.xls')
data=data.as_matrix()
#随机打乱数据
shuffle(data)
#80%的训练数据
data_train=data[:int(len(data)*0.8),:]
#20%的测试数据
data_test=data[int(len(data)*0.8):,:]然后对决策树模型进行建立:
tree = DecisionTreeClassifier() #建立决策树模型
#对模型进行训练
tree.fit(data_train[:,:3], data_train[:,3])
#保存输出模型
from sklearn.externals import joblib
joblib.dump(tree, 'C:/Python27/Lib/site-packages/xy/chapter6/test/tree.pkl')**(3)模型评价**
在模型训练完成之后,需要对模型进行评价,首先利用训练数据构建混淆矩阵对模型分类准确率进行评价。
《Python数据分析与挖掘》书中作者编写的混淆矩阵可视化函数代码如下:
def cm_plot(y, yp):
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y, yp)
import matplotlib.pyplot as plt
plt.matshow(cm, cmap=plt.cm.Greens)
plt.colorbar()
for x in range(len(cm)):
for y in range(len(cm)):
plt.annotate(cm[x,y], xy=(x, y), horizontalalignment='center', verticalalignment='center')
plt.ylabel('True label')
plt.xlabel('Predicted label')
return plt将上述混淆矩阵可视化函数代码放入电脑内Python路径即可直接导入,并画出上述训练出的决策树模型的混淆矩阵,代码如下:
from cm_plot import *
#画出混淆矩阵,.predict()方法可直接给出预测结果,即上述函数代码中的yp
cm_plot(data_train[:,3], tree.predict(data_train[:,:3])).show()画出的混淆矩阵图如下图所示:
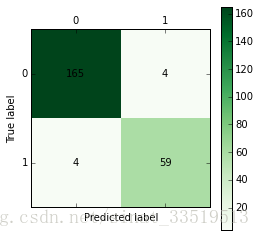
由图可以看出,模型分类准确率为
165+59165+59+4+4
=96.6%,
查准率P=
真1真1+假1=5959+4
=93.7%
查全率R=
真1真1+假0=5959+4
=93.7%
正常用户被误判为窃漏电用户占正常用户的
4165+4
=2.4%
窃漏电用户被误判为正常用户占窃漏电用户的
459+4
=6.3%
为了进一步评估模型的性能,需再利用测试数据对模型进行评价,采用ROC曲线,接下来先对ROC曲线做一个解释。
**(4)ROC曲线**
周志华所著的《机器学习》第二章——模型评估与选择中,有对ROC曲线进行详细介绍。
ROC曲线是根据学习器的预测结果对样例进行排序,按此顺序逐个把样本作为正例进行预测,每次计算出两个重要量的值,分别以它们为横、纵坐标作图。
ROC曲线以“真正例率”为纵轴,以“假正例率”为横轴,两者公式如下:
真正例率TPR=
TPTP+FN=真1真1+假0
假正例率FPR=
FPTN+FP=假1真0+假1
即在本例中,假正例率表示,在正常用户中,被误判为窃漏电用户的用户所占比例;真正例率表示,在窃漏电用户中,被正确判断为窃漏电用户的用户所占比例。
同样在《机器学习》一书中,作者也详细讲述了ROC曲线的绘图过程,现摘录如下:
给定 m+ 个正例和 m− 个反例,根据学习器预测结果对样例进行排序,然后把分类阈值设为最大,即把所有样例均预测为反例,此时真正例率和假正例率均为0,在坐标(0,0)处标记一个点。然后,将分类阈值依次设为每个样例的预测值,即依次将每个样例划分为正例。设前一个标记点坐标为(x,y),当前若为真正例,则对应标记点的坐标为(x,x+ 1m+ );当前若为假正例,则对应标记点的坐标为(x+ 1m− ,y),然后用线段连接相邻点即得。
由以上内容可知,一个优秀的分类器应该更可能多地将点往上移动,即更多的真正例,而不是往右移动,所以画出来的ROC曲线应该尽可能地往左上角靠近。
**(5)Python中ROC曲线绘制**
ROC曲线绘制函数同样可以从Python的科学计算库——sklearn中直接导入,代码如下:
#导入ROC曲线函数
from sklearn.metrics import roc_curve 然后利用matplotlib绘制出最后的ROC曲线图,代码如下:
import matplotlib.pyplot as plt
#fpr即上文提到的假正例率,tpr即上文提到过的真正例率,分别为ROC曲线的横纵坐标,而predic_proba是预测每个分类的概率
fpr, tpr, thresholds = roc_curve(data_test[:,3], tree.predict_proba(data_test[:,:3])[:,1], pos_label=1)
#作出ROC曲线
plt.plot(fpr, tpr, linewidth=2, label = 'ROC of CART', color = 'blue')
#x轴标签
plt.xlabel('False Positive Rate')
#y轴标签
plt.ylabel('True Positive Rate')
#y轴范围
plt.ylim(0,1.05)
#x轴范围
plt.xlim(0,1.05)
#图例
plt.legend(loc=4)
plt.show() 做出的ROC曲线如下图:
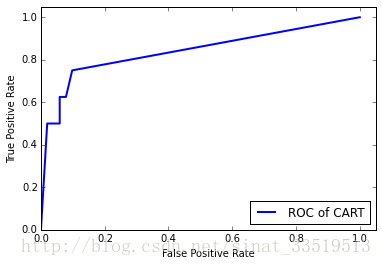
由于LM神经网络模型没有做出来,因此,无法对两个分类器性能进行对比,只能从ROC曲线图看出CART决策树模型的性能还是可以的。
**总结**
本文是对自己学习过程的记录,在做上机实验的同时,对拉格朗日插值法、CART决策树算法、ROC曲线等概念也都进行了资料的查找与了解。
本文中涉及到的代码均是参考《Python数据分析与挖掘实战》中的代码敲出来的,在这个过程中对Python科学计算库中以前不曾了解的函数包都有了更多的了解,包括混淆矩阵函数、决策树模型、拉格朗日函数、ROC曲线函数等等。
写记录一是为了日后自己的回顾,二是对自己学习的潜在督促,如果本文内容可以帮助到同样正在学习的人,那便更好了。
2017.7.17关于LM神经网络的补充
1.theano+keras安装
在之前做上机实验的时候,由于在Python(x,y)的环境下安装theano和keras一直出错,因此,略过了LM神经网络分类模型的训练。这几天还是不甘心,便又进行了尝试。因为网上大部分教程都是推荐Anaconda,一狠心便将电脑上所有Python相关的都卸载删除了,最后按照教程一步一步来。
主要参考的教程为:
手把手教你搭建深度学习平台——避坑安装theano+CUDA
利用这个教程主要安装了Anaconda和mingw,但是在安装theano的时候还是出现各种各样的问题,即使参照教程中所说将缺的文件包补上,也还是不行,最再次卸载已安装的theano,转而参考以下博客才最终完成:
Win10下keras+theano安装教程(极速)
参照这篇文章中的做法先在命令行中输入pip install keras安装keras,默认会同时安装keras和theano,但这个theano测试依旧会出问题,因此从site-packages中删除这个文件包,然后从其他平台上下载theano安装包,将解压包中的theano文件直接复制到site-packages文件中。(注意:用pip setup.py install方法直接安装还是可能会出问题,但直接复制过来是没有问题的。)
最后虽然theano.test()出来有很多警告,但是输入以下代码:
import theano
print theano.config.blas.ldflags结果没有报错,说明theano已经安装成功。
然后输入代码:
import keras这个报错的信息,因为之前在鼓捣的时候博主已经试过无数次了,因此,这一次在安装好keras之后就直接去C:\Users\rt(当前用户名).keras中将keras.json文件中的backend修改为theano,以将默认后端从tensorflow改编为theano(注意1:之所以要修改是因为tensorflow并不适合在Python2.7和Windows环境中。注意2:有些博客中提到将keras文件包中的backend文件夹里的init.py中的backend利用同样的方法修改,经博主尝试,这边改了是没有用的。)
最后,在修改了后端的前提下,本代码的输出结果为:

说明keras已经安装成功,可以使用。
至此,困扰了好几天的theano+keras安装终于成功,这还是没有加GPU加速的情况,考虑到电脑配置问题,博主就先不考虑加速了。
主要思考有以下几点:
1.Anaconda看样子的确要比Python(x,y)更为大众,也更能找到一些参考教程,在刚开始学习Python的时候,还是可以考虑使用Anaconda,不过两个都是集成环境,具体到达哪个更好,博主无法做判断,毕竟网上也的确有使用Python(x,y)安装成功的;
2.不要直接用pip安装theano,虽然很多教程都是这样的,但是经博主实验,直接用pip,基本都会缺文件,而补上文件效果也不理想,还是直接从其他平台下资源比较方便;
3.安装过程中,要多方尝试,不同教程提供的不同解决方案可能有一些适用,有一些不适用,要自我选择。
4.theano安装测试,有些教程推荐theano.test(),但博主亲历,theano.test()实在太费时间,博主花了一个晚上还没有测试完,还是直接使用“print theano.config.blas.ldflags”,至少这个没报错,说明安装时成功了的,缺一些东西对于后面使用keras问题不大,因此就可以直接使用keras了。
2.LM神经网络模型Python实现
在好不容易安装完成之后,博主当然立刻把本文中所使用的LM神经网络分类模型给尝试了。
代码如下:
###构建神经网络分类模型
from keras.models import Sequential #导入神经网络初始化函数
from keras.layers.core import Dense, Activation #导入神经网络层函数、激活函数
net = Sequential() #建立神经网络
net.add(Dense(input_dim = 3, output_dim = 10)) #添加输入层(3节点)到隐藏层(10节点)的连接
net.add(Activation('relu')) #隐藏层使用relu激活函数
net.add(Dense(input_dim = 10, output_dim = 1)) #添加隐藏层(10节点)到输出层(1节点)的连接
net.add(Activation('sigmoid')) #输出层使用sigmoid激活函数
net.compile(loss = 'binary_crossentropy', optimizer = 'adam') #编译模型,使用adam方法求解
net.fit(data_train[:,:3], data_train[:,3], nb_epoch=1000, batch_size=1) #训练模型,循环1000次
net.save_weights('C:/Users/Administrator/Desktop/xy/chapter6/net.model') #保存模型
predict_result = net.predict_classes(data_train[:,:3]).reshape(len(data_train)) #预测结果变形同样绘制混淆矩阵,代码如下:
from cm_plot import * #导入自行编写的混淆矩阵可视化函数
cm_plot(data_train[:,3], predict_result).show() #显示混淆矩阵可视化结果混淆矩阵绘制如下图:

分析同上文中是一样的,此处不再赘述。
最后在同一张图内,画出前文中所用CART决策树模型和这里添加的LM神经网络模型的ROC曲线,以做对比。代码如下:
from sklearn.metrics import roc_curve #导入ROC曲线函数
import matplotlib.pyplot as plt
fpr1, tpr1, thresholds1 = roc_curve(data_test[:,3], net.predict(data_test[:,:3]).reshape(len(data_test)), pos_label=1)
fpr2, tpr2, thresholds2 = roc_curve(data_test[:,3], tree.predict_proba(data_test[:,:3])[:,1], pos_label=1)
plt.plot(fpr1, tpr1, linewidth=2, label = 'ROC of LM', color = 'blue') #作出ROC曲线
plt.plot(fpr2, tpr2, linewidth=2, label = 'ROC of CART', color = 'green')
plt.xlabel('False Positive Rate') #坐标轴标签
plt.ylabel('True Positive Rate') #坐标轴标签
plt.ylim(0,1.05) #边界范围
plt.xlim(0,1.05) #边界范围
plt.legend(loc=4) #图例
plt.show() #显示作图结果最后两种模型的ROC曲线如下图所示:

LM神经网络的ROC曲线完全包住了CART决策树模型的ROC曲线,由此可以看出,LM神经网络模型的性能是比CART决策树模型要好一些的。
至此,这部分上机实验,才算彻底完成。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









