






一.索引
1.基础知识
一本书的目录
小表优化不用加索引,应用于大表
查看索引
show indexes from emp \G;
2.索引分类
(1).主键索引 (PRIMARY KEY)
最好每张表指定一个主键,但不是必须指定
一个表只能指定一个主键,而且主键的值不能为空
主键有多个候选索引(例如:NOT NULL 不为空,AUTO_INCREMENT 自动增长)
create table indextable3(id int primary key,name varchar(10));
show indexes from indextable3;
(2)唯一索引(UNIQUE)
create table indextable2 as select * from emp;
create unique index index2 on indextable2(empno);
show indexes from indextable2;
(3)常规索引(INDEX)
create table indextable1 as select * from emp;
create index index1 on indextable1(ename);
show indexes from indextable1 \G;
explain select * from indextable1 where ename='KING';
缺点:多占用磁盘空间,会减慢插入,删除,修改操作,需要按照索引列上排序格式执行
(4)全文索引(FULLTEXT)
create table indextable5
(id int auto_increment,
contents text not null,
primary key(id),
fulltext(contents));
执行全文索引:select * from indextable5 where match(contents) against('coffee');
(5)组合索引
create table indextable4 as select * from emp;
在ename和sal创建一个组合索引
alter table indextable4 add index index4(ename,sal);
show indexes from indextable4;
(6)哈希索引
哈希索引(hash index)基于哈希表实现,只有精确匹配索引所有列的查询才有效。对于每一行数据,存储引擎都会对所有的索引列计算一个哈希码(hash code),哈希码是一个较小的值,并且不同键值的行计算出来的哈希码也不一样。哈希索引将所有的哈希码存储在索引中,同时在哈希表中保存指向每个数据行的指针。
Innodb和MyISAM默认的索引是B树索引;而Mermory默认的索引是哈希索引。
create table indextable6
(id int,name varchar(10))
engine=memory;
create index index6 on indextable6(name);
show indexes from indextable6 \G;
3. 优化索引
(1)使用ICP优化索引
ICP是Index Condition Pushdown的简写。它是mysql使用索引从表中检索行数据的一种优化方式,从MySQL 5.6开始支持。MySQL 5.6之前存储引擎会通过遍历索引定位基表中的行,然后返回给Server层,再去为这些数据行进行WHERE后的条件的过滤。MySQL 5.6之后支持ICP后,如果WHERE条件可以使用索引,MySQL 会把这部分过滤操作放到存储引擎层,存储引擎通过索引过滤,把满足的行从表中读取出。ICP能减少引擎层访问基表的次数和 Server层访问存储引擎的次数。
确认是否开启ICP
show variables like 'optimizer_switch';
手动开启
set optimizer_switch='index_condition_pushdown=on';
explain select * from emp where deptno=10 and sal>2500;
alter table emp add index index_deptno_sal(deptno,sal);
(2)使用MRR优化索引
是MySQL优化器将随机IO转化为顺序IO以降低查询过程IO开销的一种手段
MRR适用场景
是辅助索引,如INDEX(key1),查询key1在n到m范围内的数据
使用限制就是MRR适用于range、ref、eq_ref的查询
(3)使用BKA优化索引
是MySQL优化器提高join性能的一种手段,它是一种算法
使用限制:使用BKA特性,必须要启用MRR特性
BKA主要适用于join表上有索引可利用的情况,否则只能使用BNL
二.表对象
1.数据类型
char 和varchar 的区别 char不存储空格
2.表操作
ALTER TABLE 表名 ACTION;
我们可以对表进行修改字段,添加字段,删除字段,添加索引,删除索引,更改表名称,更改字段名称,更改auto_increment属性的初始值等
修改字段
我们使用change或者modify关键字
ALTER TABLE `users` CHANGE `username` `uname` VARCHAR(32) NOT NULL
ALTER TABLE `users` MODIFY`username` VARCHAR(32) NOT NULL default ''
change可以改变字段的名称,modify不可以
添加字段
ALTER TABLE `users` ADD `tname` VARCHAR(32) NOT NULL after userpass(在userpass字段后面添加新字段);
删除字段
ALTER TABLE `users` DROP `tname`
更改表名称
ALTER TABLE 旧表名 RENAME AS 新表名
更改AUTO_INCREMENT初始值
ALTER TABLE 表名称 AUTO_INCREMENT=1
添加索引
ALTER TABLE `users` ADD INDEX/UNIQUE/PRIMARY KEY/索引名(字段名称)
删除索引
ALTER TABLE `users` DROP INDEX/UNIQUE/PRIMARY KEY 索引名(字段名称)
可以使用show indexes from 表名\G: 查看当前索引
创建表
create table test4(id int,name varchar(20),age int);
show create table test4;
desc test4; 完整:describe test4;
show columns from test4;
删除表
drop table 表名
3.数据的约束:对表中的数据的一种限制条件
(1)主键约束
(2)唯一约束
(3)检查约束:假设:薪水 [0,20000]
create table testcheck
(id int primary key,
name varchar(10),
salary int,
check (salary>=0 and salary<=20000));
insert into testcheck values(1,'Tom',3000);
insert into testcheck values(2,'Mike',50000);
(4)非空约束
(5)默认值约束
(6)外键约束
父表
create table testparent
(id int primary key,name varchar(10));
子表
create table testchild
(id int primary key,
name varchar(10),
parentid int,
foreign key (parentid) references testparent(id));
4.表中的碎片
在InnoDB中删除行的时候,这些行只是被标记为“已删除”,而不是真正从物理存储上进行删除了,因而空间也没有真的被释放回收。InnoDB的Purge线程会异步的来清理这些没用的索引键和行。但是依然没有把这些释放出来的空间还给操作系统重新使用,因而会导致页面中存在很多空洞。如果表结构中包含动态长度字段,那么这些空洞甚至可能不能被InnoDB重新用来存新的行。另外,删除数据就会导致页(Page)中出现空白空间,大量随机的DELETE操作,必然会在数据文件中造成不连续的空白空间。而当插入数据时,这些空白空间则会被利用起来,于是造成了数据的存储位置不连续。物理存储顺序与逻辑上的排序顺序不同,这种就是数据碎片
查看员工表的状态信息
show table status like 'emp' \G;
数据总大小:Data_length + Index_length = 32768
实际表空间文件大小: 行数*行的平均长度
Rows * Avg_row_length = 16380
碎片长度=数据总大小-实际表空间文件大小
清理表上的碎片
alter table emp engine = innodb;
5.表的统计信息
数据库的统计的信息反映的是数据的分布情况。MySQL执行SQL会经过SQL解析和查询优化的过程,解析器将SQL分解成数据结构并传递到后续步骤,查询优化器发现执行SQL查询的最佳方案、生成执行计划。查询优化器决定SQL如何执行都依赖于数据库的统计信息。因此,数据库的统计信息对于SQL的优化非常的重要。
统计信息存于information_schema数据库
(1).统计每个库的大小。
mysql> select table_schema,
sum(data_length)/1024/1024/1024 as data_length,
sum(index_length)/1024/1024/1024 as index_length
from information_schema.tables
where table_schema !='information_schema' and table_schema != 'mysql'
group by table_schema;
(2).查看数据表量较大的前10张表。
mysql> SELECT TABLE_SCHEMA AS database_name,
TABLE_NAME AS table_name,
TABLE_ROWS AS table_rows,
ENGINE AS table_engine,
ROUND((DATA_LENGTH)/1024.0/1024, 2) AS Data_MB,
ROUND((INDEX_LENGTH)/1024.0/1024, 2) AS Index_MB,
ROUND((DATA_LENGTH+INDEX_LENGTH)/1024.0/1024, 2) AS Total_MB,
ROUND((DATA_FREE)/1024.0/1024, 2) AS Free_MB
FROM information_schema.tables AS T1
WHERE T1.`TABLE_SCHEMA` NOT IN
('performance_schema','mysql','information_schema')
ORDER BY T1.`TABLE_ROWS` DESC
LIMIT 10;
(3).查看数据表空间较大的前10张表。
mysql> SELECT TABLE_SCHEMA AS database_name,
TABLE_NAME AS table_name,
TABLE_ROWS AS table_rows,
ENGINE AS table_engine,
ROUND((DATA_LENGTH)/1024.0/1024, 2) AS Data_MB,
ROUND((INDEX_LENGTH)/1024.0/1024, 2) AS Index_MB,
ROUND((DATA_LENGTH+INDEX_LENGTH)/1024.0/1024, 2) AS Total_MB,
ROUND((DATA_FREE)/1024.0/1024, 2) AS Free_MB
FROM information_schema.tables AS T1
WHERE T1.`TABLE_SCHEMA`
NOT IN('performance_schema','mysql','information_schema')
ORDER BY
ROUND((DATA_LENGTH+INDEX_LENGTH)/1024.0/1024, 2)
DESC LIMIT 10;
(4).查看碎片较多的前10张表。
mysql> SELECT
TABLE_SCHEMA AS database_name,
TABLE_NAME AS table_name,
TABLE_ROWS AS table_rows,
ENGINE AS table_engine,
ROUND((DATA_LENGTH)/1024.0/1024, 2) AS Data_MB,
ROUND((INDEX_LENGTH)/1024.0/1024, 2) AS Index_MB,
ROUND((DATA_LENGTH+INDEX_LENGTH)/1024.0/1024, 2) AS Total_MB,
ROUND((DATA_FREE)/1024.0/1024, 2) AS Free_MB,
ROUND(ROUND((DATA_FREE)/1024.0/1024, 2)/
ROUND((DATA_LENGTH+INDEX_LENGTH)/1024.0/1024, 2)*100,2)
AS Free_Percent
FROM information_schema.tables AS T1
WHERE T1.`TABLE_SCHEMA` NOT IN
('performance_schema','mysql','information_schema')
AND ROUND(ROUND((DATA_FREE)/1024.0/1024, 2)/
ROUND((DATA_LENGTH+INDEX_LENGTH)/1024.0/1024, 2)*100,2)
>10
AND ROUND((DATA_FREE)/1024.0/1024, 2)>100
ORDER BY Free_Percent DESC
LIMIT 10;
(5).手动收集统计信息
analyze table 表名;
6.临时表
MySQL 临时表在我们需要保存一些临时数据时是非常有用的。临时表只在当前会话的连接可见,当关闭连接时,Mysql会自动删除表并释放所有空间。由于临时表只属于当前的会话,因此不同会话的临时表可以重名。如果有多个会话执行查询时,使用临时表不会有重名的担忧。所有临时表都存储在临时表空间,并且临时表空间的数据可以复用。MySQL的InnoDB存储引擎、MyISAM存储引擎和Memory存储引擎都支持临时表。
create temporary table temptable(
tid int primary key,
tname varchar(10)
);
三.存储引擎
MySQL 中具体与文件打交道的子系统。根据MySQL AB公司提供的文件访问层抽象接口定制的一种文件访问机制
MySQL5.6之前默认存储引擎MyISAM,5.6之后默认存储引擎InnerDB
show create table 表名; 查看创建表的语句
(1)MyISAM:非事务存储引擎,在5.1版本之前,默认的存储引擎
create table test2(tid int,tname varchar(20),money int) engine=myisam;
(2)Memory:基于内存的存储引擎
create table test3(tid int,tname varchar(20),money int) engine=memory;
(3)InnoDB
四. InnoDB存储引擎
1、存储结构:逻辑、物理
(1)逻辑存储结构:
表空间:最高层、所有的数据都是存放在表空间中
共享表空间ibdata1:存储系统的相关数据
mysql> show variables like '%per_table%';
+-----------------------+-------+
| Variable_name | Value |
+-----------------------+-------+
| innodb_file_per_table | ON |
+-----------------------+-------+
1 row in set (0.00 sec)
段:表空间由段组成,表段和索引段
区:由连续的数据页,大小:1M
页:是最小的逻辑存储单元,表示一次IO读写的数据量
16K
mysql> show variables like 'innodb_page_size';
+------------------+-------+
| Variable_name | Value |
+------------------+-------+
| innodb_page_size | 16384 |
+------------------+-------+
(2) 物理存储结构:硬盘上的文件
数据文件
重做日志文件:redo log
redo log是InnoDB存储引擎层生成的日志,主要为了保证数据的可靠性和 事务的持久性。每个redo log默认的大小是1G,由参数“innodb_log_file_size”参数决定。
mysql> show variables like "innodb_log_file_size";
(*)存放的是客户端的事务操作
(*)只要redolog写入成功,就算事务操作成功
(*)路径:
[root@mysql10 data]# ls ib_logfile*
ib_logfile0 ib_logfile1
撤销日志文件:undo log,记录的是旧版本的数据,当我们对记录做了变更操作时就会产生undo记录。当一个旧的事务需要读取数据时,为了能读取到老版本的数据,需要顺着undo链找到满足其可见性的记录
参数文件:
[mysqld] 服务器端的配置参数
server-id=1 标识MySQL数据库的ID
port=3306 监听的端口号
basedir=/usr/local/mysql MySQL的安装目录
datadir=/usr/local/mysql/data 数据目录的路径
log-error=/usr/local/mysql/data/error.log 错误日志文件
socket=/tmp/mysql.sock 用于本地连接的Socket套接字文件
pid-file=/usr/local/mysql/data/mysql.pid MySQL的进程标识文件
character-set-server=utf8 服务器端的字符集
lower_case_table_names=1 控制表名、列名的大小写
1:忽略大小写 0:大小写敏感
innodb_log_file_size=1G 重做日志文件的大小
default-storage-engine=INNODB 默认采用InnoDB的存储引擎
default_authentication_plugin=mysql_native_password 用户的密码认证插件
[client] 客户端的配置参数
port=3306
default-character-set=utf8
错误日志:tail error.log
二进制日志文件:binlog ,由应用程序产生
(*)功能上,类似redo log
(*)作用:数据恢复、主从复制、主主复制
慢查询日志:慢查询日志可以把超过参数long_query_time时间的所有SQL语句记录进来,帮助DBA人员优化所有有问题的SQL语句。通过mysqldumpslow工具可以查看慢查询日志
(1)查看是否启用了慢查询
show variables like '%slow_query%';
(2)long_query_time:默认10秒
show variables like '%long_query_time%';
(3)修改参数
set global slow_query_log = 'ON';
set session long_query_time = 2;
全量日志
(*)功能上,类似binlog
(*)由应用程序产生,并且会记录所有的SQL
show variables like '%general_log%';
中继日志
主从复制中,中继日志是从服务器上一个很重要的文件。主从复制的工作原理分为以下3个步骤:
(1)主服务器(master)把数据更改记录到二进制日志(binlog)中。
(2)从服务器(slave)把主服务器的二进制日志复制到自己的中继日志(relay log)中。
(3)从服务器重做中继日志中的日志,把更改应用到自己的数据库上,以达到数据的最终一致性。
Pid文件
Socket文件
2.内存结构
(1)SGA、PGA
SGA:System Global Area 系统的全局区
PGA:Program Global Area 程序的全局区
(2)Buffer缓冲区的状态
(3)内存刷新机制:检查点
(*)完全检查点:正常关机
(*)增量检查点:模糊检查点
3.线程结构
(1)主线程
(2)IO线程
(3)其他线程
五.MySQL 用户管理与访问控制
系统表:mysql.user表
默认的用户:
| mysql.infoschema | 系统用户,用来管理和访问系统自带information_schema
| mysql.session | 提供给MySQL的插件使用
| mysql.sys | 用于MySQL数据库中对象的定义
| root | 超级用户,用于所有的权限,可以执行任何的操作
1、用户管理
(1)创建用户、重命名用户、删除用户
创建一个名叫user002用户,密码Welcome_1
create user user002 identified by 'Welcome_1';
create user 'user002'@'localhost' identified by 'Welcome_1';
重命名用户,user002 --> user003
rename user user002 to user003;
(2)管理用户的密码
(*)修改密码
alter user 'user003'@'%' identified by 'abc123'
(*)丢失了root用户的密码
停止MySQL数据库实例
systemctl stop mysqld
修改my.cnf
[mysqld]最后
skip-grant-tables
重启MySQL
systemctl start mysqld
登录 mysql
mysql> use mysql
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
mysql> select host,user from user where user='root';
+-----------+------+
| host | user |
+-----------+------+
| localhost | root |
+-----------+------+
直接通过修改user表中的authentication_string重置root用户的密码
mysql> update user set authentication_string='' where user='root';
Query OK, 1 row affected (0.01 sec)
Rows matched: 1 Changed: 1 Warnings: 0
生效修改
mysql> flush privileges;
2、权限管理
(1)MySQL的权限系统
全局权限: 针对整个数据库实例
mysql.user
数据库权限:针对某个具体的数据库
mysql.db
对象权限: 针对某个具体的数据库对象:表、列、存储过程、存储函数
mysql.tables_priv
mysql.columns_priv
mysql.procs_priv
六、性能优化与运维管理
1.使用explain查看SQL执行计划
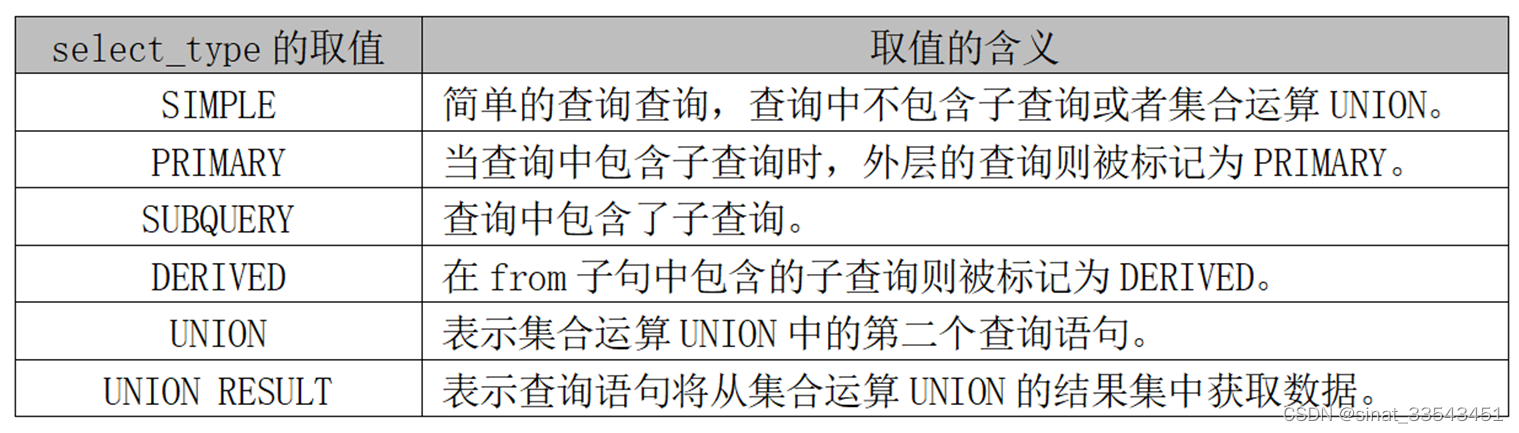
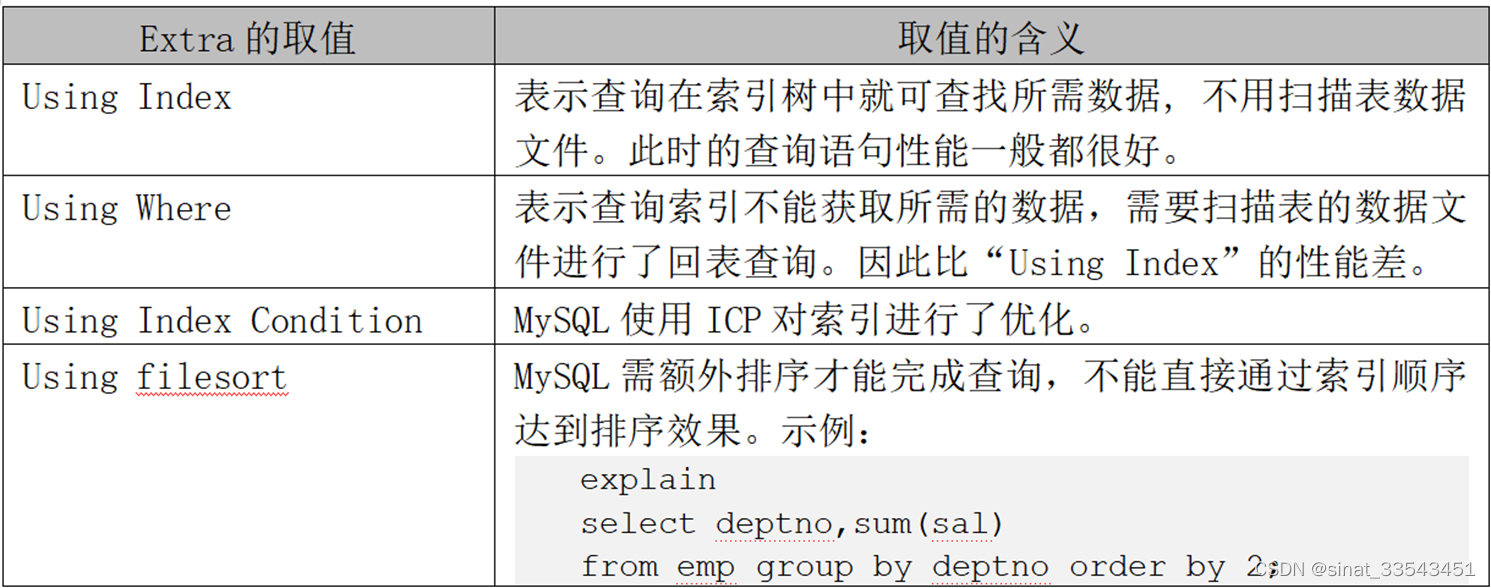
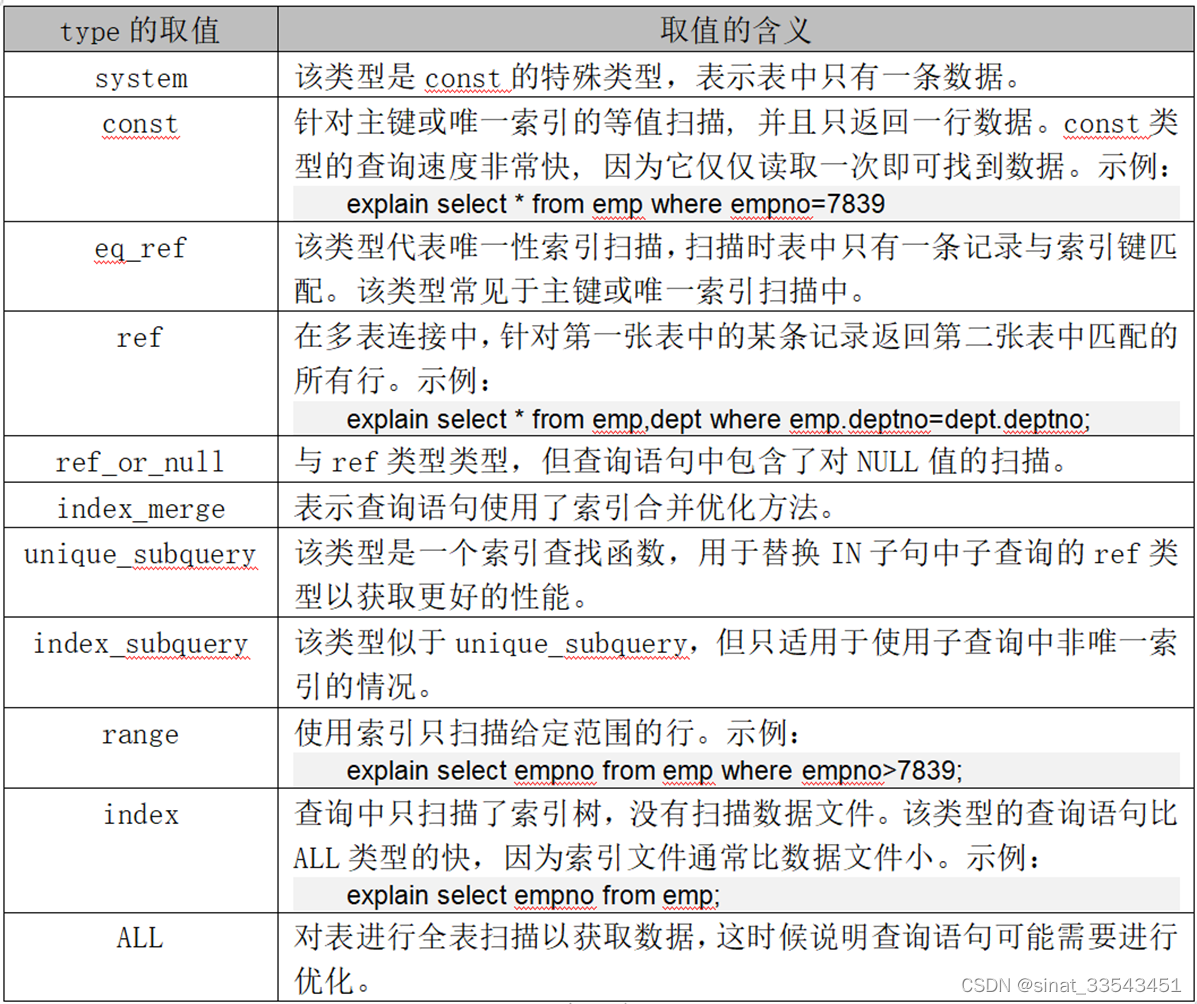
2、使用profile查看SQL的资源消费
(1)查询Profile的参数设置
show variables like '%profiling%';
+------------------------+-------+
| Variable_name | Value |
+------------------------+-------+
| have_profiling | YES |
| profiling | OFF |默认情况下,关闭
| profiling_history_size | 15 |保存最近执行过的SQL
+------------------------+-------+
3 rows in set (0.03 sec)
(2)开启Profile
set profiling = ON;
(3)执行SQL
(4)show profiles \G;
(5)查看ID为3的SQL资源消费情况
show profile cpu,block io,memory for query 3;
Status: SQL语句执行的状态
Duration:SQL每一步耗时
CPU_user:当前用户占有的CPU
CPU_system:系统占用的CPU
Block_ops_in:输入
Block_ops_out:输出
七、事务与锁
1、什么是事务(transaction)?特征
(*)DML:Data Manipulation Language 数据操作语言
insert、update、delete
(*)事务:由一组DML语句组成;要么都执行成功,都执行失败
(*)特征:A(原子性)C(一致性)I(隔离性)D(持久性)
2、控制事务
开启事务:start transaction;
set autocommit=0;
注意:Oracle是自动开启事务
操作事务:DML
提交事务:commit、DDL(Data Definition Language)创建删除表视图、正常关机
回滚事务:rollback、隐式回滚 (客户端发生异常)
rollback 保存点
(start transation;
insert
savepoint a;定义一个保存点
insert
delete
rollback to savepoint a; 直接写rollback的话还是全部回滚,保存点没意义 )
create table myaccount(id int,name varchar(10),money int);
insert into myaccount values(1,'Tom',1000);
insert into myaccount values(2,'Mike',1000);
转账操作:
start transaction;
update myaccount set money=money-100 where id=1;
update myaccount set money=money+100 where id=2;
commit;
3、事务的并发
(1)事务的隔离级别
为了解决数据在并发访问时,数据的一致性问题。MySQL数据库提供了四种事务的隔离级别,它们分别是:读未提交(READ-UNCOMMITTED)、读已提交(READ-COMMITTED)、可重复读(REPEATABLE-READ)和可序列化读(SERIALIZABLE)。执行下面的语句可以得到MySQL默认的事务隔离级别是可重复读。
mysql> show variables like '%isolation%';
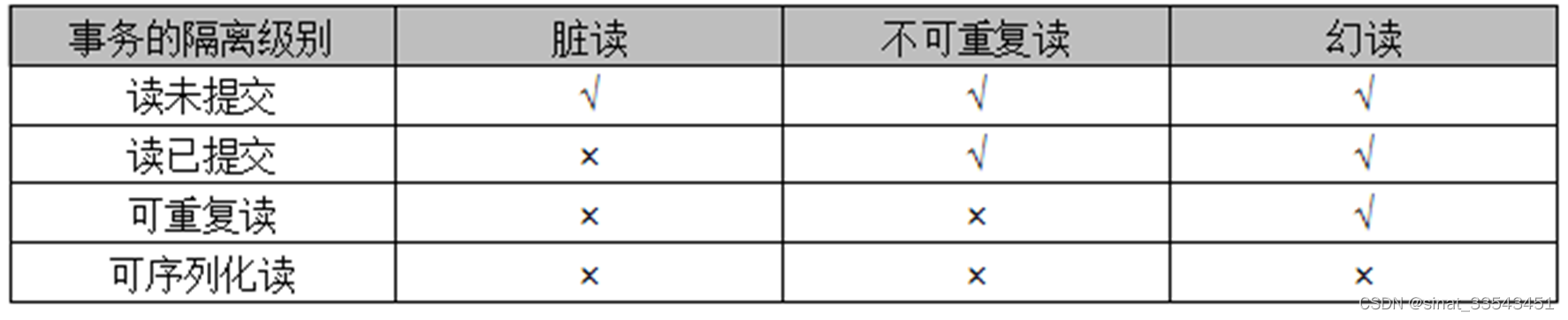
(2)演示Demo:
(*)脏读:在一个事务中读取到了另一个事务还没有提交的数据
会话1:Mike 卖家
set session transaction isolation level read uncommitted;
set session transaction isolation level read committed;
start transaction;
select * from myaccount where id=2;
会话2:Tom 买家
start transaction;
update myaccount set money=money+100 where id=2;
(*)不可重复读:在同一个事务中,前后两次读取的数据不一致
示例:银行-储户
会话1:银行
set session transaction isolation level read committed;
set session transaction isolation level repeatable read;
start transaction;
上午:select sum(money) from myaccount;
下午:select sum(money) from myaccount;
会话2:储户
start transaction;
中午:update myaccount set money=money+100 where id =1;
commit;
(*).在一个事务里读取到另一个事务新插入的数据
4.MySQL的锁
(1)、InnoDB锁的类型:行锁、表锁
MyISAM存储引擎和Memory存储引擎采用的表级锁。而InnoDB存储引擎既支持行级锁,也支持表级锁。但InnoDB默认采用的行级锁。值得注意的是,InnoDB的行锁是通过索引实现的,这就意味着只有通过索引查询检索数据时,InnoDB引擎才会使用行锁。否则,InnoDB存储引擎将使用表锁。
InnoDB默认采用的是行级锁,并实现了以下两种类型的行级锁:
共享锁(S):也叫作读锁。在同一个数据对象上可以有多把共享锁。如果一个事务在数据对象上加上了共享锁,则该事务可以读取数据但不能修改数据。其他的事务也可以在该数据对象上继续添加共享锁,也可以读取该数据,但同样也不能修改数据。
排他锁(X):也叫作写锁。在同一个数据对象上只允许有一把排它锁,获取到数据排它锁的事务可以读取数据和修改数据。一旦数据被加上了排它锁,其他事务就不允许再对该数据添加任何类型的行锁。
InnoDB为了实现同时支持行级锁和表级锁,在其内部使用了两种类型的意向锁(Intention Locks)来实现多粒度锁机制。这两种意向锁都是表锁。
意向共享锁(IS):事务在给数据添加行级共享锁之前,必须先取得该表的意向共享锁。
意向排他锁(IX):事务在给数据添加行级排他锁之前,必须先取得该表的意向排他锁。
(2)、死锁
死锁是指两个或两个以上事务在执行过程中,因互相的等待或者争抢锁资源而造成的互相等待的现象。
当产生死锁时,执行下面的语句查看innodb引擎的状态。
mysql> show engine innodb status \G;
如何避免死锁
(*)大事务拆小。大事务更倾向于死锁,如果业务允许,将大事务拆小。
(*)为表添加合理的索引。可以看到如果不走索引将会为表的每一行记录添加上锁,死锁的概率大大增大。
(3)、监控MySQL的阻塞















 42万+
42万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









