






数据库表设计
统一规范
1.默认存储引擎InnerDB
2.默认字符集utf8mb4
3.关闭大小写
4.开启per-table表空间
表与表之前多对多的关系可以使用交叉表
禁用功能:
enmu、set;blob、text;(检索技能不高很难用索引优化)
视图、event;存储过程、触发器 (功能不完善,调试排错困难。为了存储计算分离这类功能最好在程序计算中实现)
命名规范:
1.所有表名小写
2.不允许使用-(横杠)、空格
3.允许使用其他字符作为名称
4.“见名知意”的原则
表名的命名规范:
临时表:tem,tem_yyyymmdd
备份表:_bak,_bak_yyyymmdd
字典表:_dic
历史归档表:_his
日志表:_log
类型表:_type
大字段blob或text:_lob
代码编码:_code
1.单表仅使用a-z、_
2.分表名称为 表名_编号
3.业务表名代表用途、内容:子系统简称_业务含义_后缀
字段命名规范:
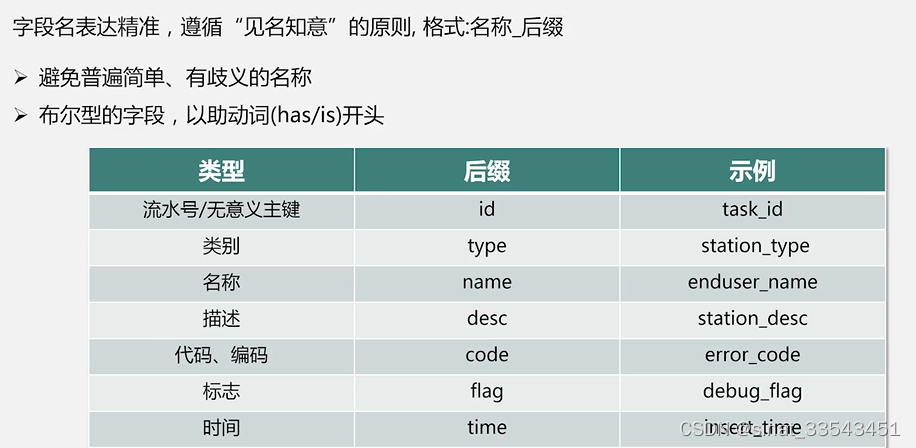
索引名命名规范:
前缀_表名(或缩写)_字段名(或缩写)
主键必须使用前缀"pk_"
UNIQUE约束必须使用前缀"uk_"
普通索引必须使用"idx_"
字段的要求:
合适的类型,最短的长度,NOT NULL
表字段数少而精
IP的处理:用INT UNSIGNED存储IP,非CHAR(15) INET_ATON() INER_NTON()
时间用时间戳
表明id最好识别性比如:bug_id,account_id
高效性能索引
索引设计和工作原理
谓词
条件表达式,通俗讲就是过滤字段,where子句由一个或者多个谓词组成
过滤因子:描述谓词的选择性,即表中满足谓词条件的记录行数所占的比例
简单谓词的过滤因子=谓词结果集的数量/表总行数
组合谓词的过滤因子=谓词1的过滤因子*谓词2的过滤因子
过滤因子越小表示选择性越强,字段越适合创建索引
例:select * from city where city='BeiJing' and last_update='2019-01-02'
city的过滤因子=谓词city结果集的数量/表总行数=select count(*) from city where city='BeiJing'/select count(*) from city=20%
last_update的过滤因子=谓词last_update结果集的数量/表总行数=select(*) from city where last_update='2019-01-02'/select count(*) from city=10%
组合谓词:city过滤因子*last_update过滤因子=20%*10%=2%,组合谓词的过滤因子为2%,即只有表总行数的2%匹配过滤条件,可以考虑创建组合索引
基数
某个键值去重后的行数),索引列不重复记录数量的预估值
执行show index from table_name
会看到Cardinality同时也会触发MySQL数据库对Cardinality值的统计
当发现优化器选择错误的执行计划或者没有走理想索引时,手动执行统计信息
alert table table_name engine=innodb
analyze table table_name
选择率
count(distinct city/count(*)) 选择率越接近于1则更适合创建索引
回表:无法通过索引扫描访问的所有数据,需要回到主表进行数据扫描并返回

创建索引策略
1.为搜索列、排序列、分组列创建索引,必要时加入查询列创建覆盖索引
2.计算字段列基数和选择列,选择率越接近于1越适合创建索引
3.索引选用较小的数据类型(整型优于字符),字符串可以考虑前缀索引
4.不要建立过多的索引,优先调整索引顺序
5.参与比较的字段类型保持匹配并创建做因
调优索引
1.分析执行计划
type:表示表的连接类型
possible_keys:表示查询时,可能使用的索引
key:表示实际使用的索引
key_len:索引字段的长度
ref:列与索引的比较id:选择标识符,从大到小,从上到下的顺序执行
select_type:表示查询的类型
table:输出结果集的表
partitions:匹配的分区
rows:扫描出的行数(估算的行数)
filtered:按表条件过滤行的百分比
Extra:执行情况的描述和说明,use index(覆盖索引)>use where>use file>use filesort
2.更新统计信息
3.Hint优化,方便调优(FORCE INDEX、USE INDEX、IGNORE INDEX、STRAIGHT_JOIN)
4.避免类型转换
5.关注optimizer_switch
6.关注索引优化特性 Muti-Range Read (MRR)、Index Condition Pushdown(ICP)
第三方设计索引助手:Arkcontrol SQL助手
索引创建规范
1.单张表中索引数量不超过5个,单个索引中的字段数不超过5个
2.表必须有主键,推荐使用UNSIGNED自增列作为主键。唯一键由三个以下字段组成,并且字段字段都是整型时,可使用唯一键作为主键。其他情况下,建议使用自增列或发号器作为主键
3.禁止冗余索引【索引(a,b,c) 和索引(a,b)】、禁止重复索引【索引(a)和索引(a,主键ID)】
4.联表查询时,JOIN列的数据类型必须相同,并且要建立索引
5.不在低基数列上建立索引,例如“性别”
6.选择区分(选择率大的列建立索引),组合索引中,区分度(选择率)大的字段放在最前
7.对过长的varchar字段建立索引建议使用前缀索引,或添加CRC32或者MD5位列并建立索引
8.合理创建联合索引(a,b,c) 相当于(a)、(a、b)、(a、b、c)
9.合理使用覆盖索引减少IO,避免排序
如何提升查询性能
1.MySQL查询优化器
查询缓存Query Cache-》解析器Parser-》预处理器-Preprocessor-》查询优化器Query Optimizer-》查询执行引擎Query Execution Engine-》存储引擎Storage Engine
2.为什么range执行效率差
Range Query Optimizer流程:(1)根据查询条件计算所有的possible keys
(2)计算全表扫描代价(cost_all)
(3)计算最小的索引范围访问代价-核心步骤,直接决定了Range的查询效率
对于每个possible keys(可选索引),调用records_in_ranges函数计算范围中的rows
根据rows,计算二级索引访问代价
获取cost最小的二级索引访问代价
选择最小化访问代价:
Cost_all<cost_range,则全表扫描
cost_all>cost_range,则索引范围扫描
原因分析:
查询性能仅次于全表扫描(ALL) 和全索引扫描(Index) 三者需要重点关注。
Range使用records_in_range对估算每个值范围的rows,结果依赖于possible_keys。
possible_keys越多,随机IO代价越大,Range查询效率越差
总结:
减少possible_keys,减少records_in_range调用
删除冗余索引,可以用工具pt-index-usage检查
删除重复索引,可以使用工具pt-duplicate-key-checker检查
分析慢查询常用工具:mysqldumslow (官方慢查询分析工具)、pt-query-digest(常用工具),vc-mysql-sniffer,pt-kill
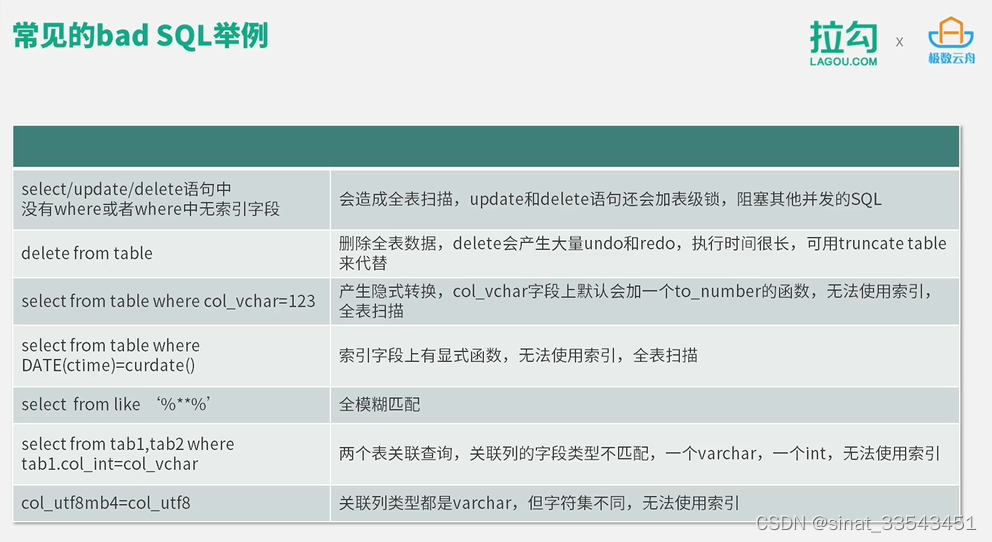
如何优化SQL
1.全表扫描还是索引扫描:小表差别不大,大表需要索引扫描
2.如何建立合适的索引:索引创建后,尽量不要频繁修改。业务可以根据现有的索引情况合理利用索引,而不是每次去修改索引。能在索引中完成的查找,就不要回表查询。比如select具体字段,就有主语实现覆盖索引从而降低IO次数,而达到优化SQL的目
3.如何正确使用索引
4.多表联合查询的索引:
1.多表关联的SQL,关联列上要有索引且字段类型一致,这样mysql在做嵌套循环连接查找时可以使用索引。
2.现实情况中,开发频出SQL中关联列字段类型不一致或传入参数类型与字段类型不匹配,导致无法使用索引
3.索引列上使用函数也不会使用到索引
4.多表关联时,尽量让结果集小的表作为驱动表
5.全模糊查询:当查询条件条件为全模糊like '%%',索引无法使用,要通过添加其他选择度高的列或者条件作为一种不错,从而加快查询速度,可以放到ES或者solr中解决
尽量不要用到子查询,临时表不能用索引
MySQL对于出现在from中的临时表表无所谓顺序,对于where中也无所谓顺序
6.排序与分组:
order by /group by 的SQL涉及到排序:
尽量在索引中包含排序字段,
让排序字段的排序顺序与索引列中的顺序相同,
避免排序或炸减少排序次数
比如where a=? order by b,c :可以创建一个索引(a,b,c),
如果执行计划中出现using filesort,DBA就要重点关注索引字段和顺序
7.复杂查询还是简单查询:不要用一个SQL解决所有事情,可以分步骤做,省时、易理解、优化
8.对于后台管理或者其他统计类的只读场景,可以做读写分离,利用从库分担写库的读压力
9.程序应有捕获SQL异常的处理机制,必要时通过callback回滚
10.limit分页优化
1.走索引避免排序,减少不必要的物理IO
2.每页展示数据确定起始范围,获取条件范围的N条记录即可
3.传递主键(唯一特性),快速定位
11.count优化
1.选择索引key_len最短的二级索引,不要使用全表扫描(PK聚族索引全表扫描)
2.索引key_en越短,读取页面越少,进而IO_COST越小
12.SQL编写规范
1.select 只获取必要的字段,禁止使用select *
2.用IN代替OR。SQL语句中的IN包含的值不宜过多,应少于100个
3.禁止使用order by dand()。order by rand()会为表增加几个伪列,然后使用rand()函数为每一行数据计算出rand()值,最后基于改行排序,这通常都会生成磁盘上的临时表,因此效率非常低。建议使用rand()函数获得随机的主键值,然后通过主键获取数据
4.SQL中避免出现now(),rand(),sydate(),current_user()等不确定结果的函数
数据库服务器硬件优化
1.CPU
每个连接对应一个线程,每个并发query只能使用一个核
优化:Thread Pool
show global variables like '%thread_handling%'
one-connection-per-thread(不建议)
one-thread-per-connection(建议)
1.System Profile:系统配置选择Performance Per Watt Optimized(DAPC),发挥最大功耗性能,而不是节能模式((高运算节点禁用)),节能模式在低高频性能转换时易出现BUG。
2.CPU Frequency:CPU优先选择高主频已提高运算能力;其次选择核数多,可以多线程并发处理和多实例部署
3.Close C1E、C States:关闭C1E(增强型空闲电源管理状态转换)和C States服务器不需要节能和省电运行。默认是开启状态,DB服务器建议关闭已提高CPU效率
总结:数据库服务器选择高主频多核数CPU类型,同时开启最大性能和关闭CPU CIE和C States。高频加速SQL执行,多核解决并发
2.内存
1.Memory Frequency:内存频率选择Maximum Performance(最佳性能)
2.Memory Size:大内存,renice mysql pid 避免OOM时MySQL被强杀。echo -15>/proc/{pid of mysqld}/oom_adj 或 renice -19-p `pid of mysqld`
3.Close NUMA:内存设置菜单中,启用Node Interleaving避免NUMA问题,同时建议修改系统配置关闭NUMA
总结:数据库服务器选择大内存,同时开启最大性能和关闭NUMA
3.磁盘
1.RAID策略:SSD无需RAID,优先RAID10,其次RAID5;优先SSD或PCle SSD 机械盘使用高转速硬盘
2.RAID CACHE&BBU:购置阵列卡需要配备CACHE及BBU模块可提升机械盘IOPS
3.读写策略:WB或Force WB with no battery,严禁WT关闭阵列预读策略,只用作写缓存
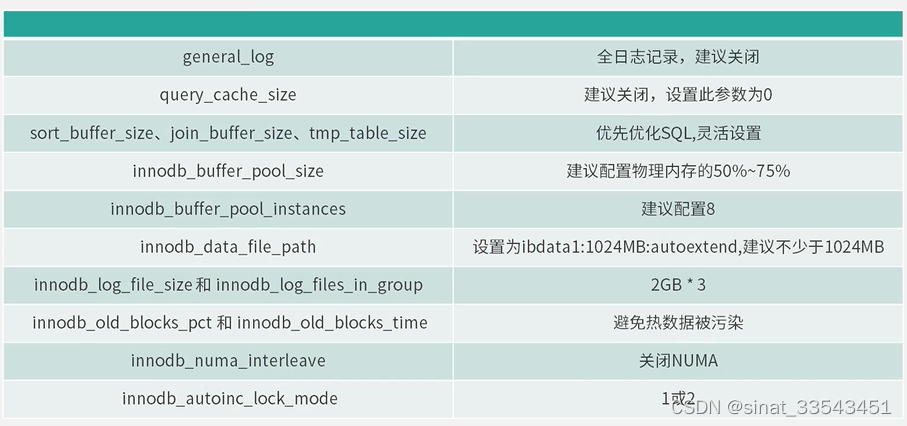
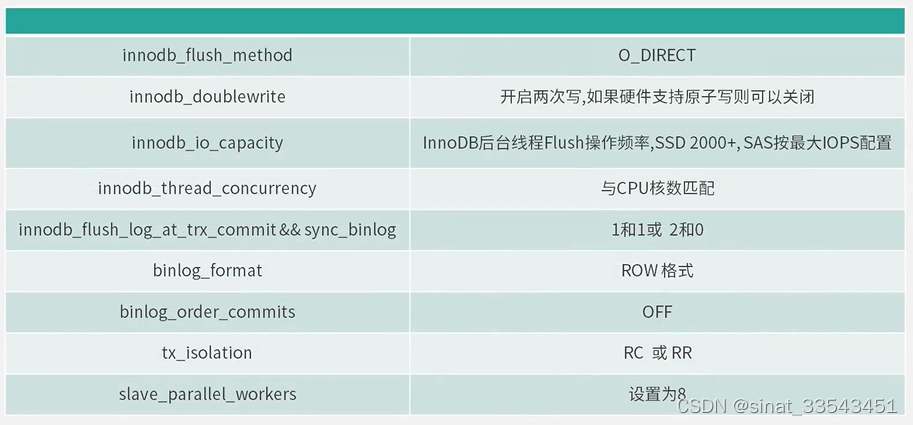
4.参数优化
内存参数=系统全局内存(SGA)+线程全局内存(PGA)


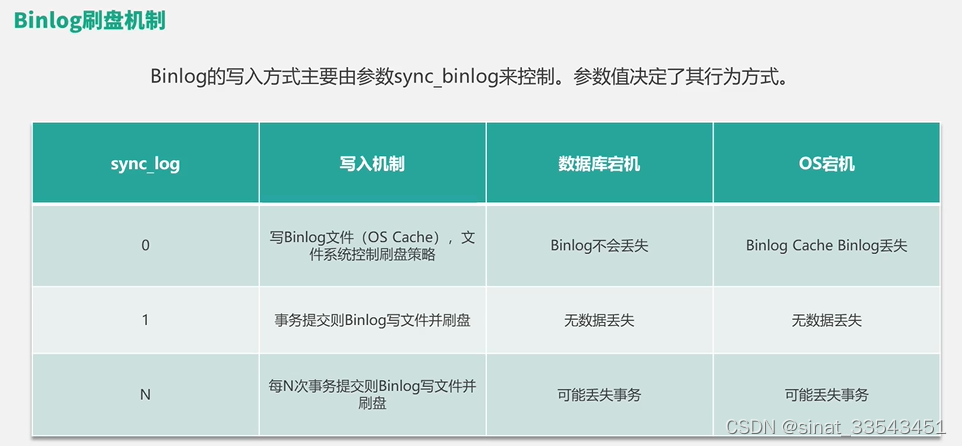
log优化:
innodb_flush_log_at_timeout:每隔N秒写入并刷新日志,默认为1即每秒flush一次,可选[1,2700]。该参数允许增加flush之间的间隔以减少杀心,避免影响二进制日志组提交的性能
innodb_log_file_size:日志文件大小,建议设置1-2GB
innodb_log_files_in_group:日志文件组个数
总结:数据零丢失场景双为1,否则设置为0和2.日志文件大小扩容有助于提高性能
















 3816
3816

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









