




目录
随着AI的飞速发展,各种创新的AI自动化测试工具如雨后春笋般涌现,为软件测试领域带来了全新的活力和可能性。
自动化测试作为保障软件质量的关键手段,正经历着一场由AI驱动的深刻变革。在这场变革中,Github中一个高达51K Stars(截止2025.4.1)的Browser Use项目犹如一颗璀璨的新星,脱颖而出。

Browser Use是什么?
Browser Use是基于Playwright的增强工具,专注于将AI代理与浏览器自动化结合,通过简化操作和扩展功能提升了开发效率。
具体来说,Browser Use围绕Playwright做了以下增强:
- AI驱动的自动化能力:通过集成GPT-4、Gemini等大模型,用户可以直接用自然语言描述任务,Browser Use自动生成Playwright脚本并执行。
- 视觉与HTML结合:同时分析网页的视觉布局和HTML结构,帮助AI更精准理解页面元素,处理动态渲染内容。
- 多标签页自动化:支持自动管理多个浏览器标签页,并行处理复杂工作流(如同时监控多个页面数据)。
- 持久化会话:允许保持浏览器窗口长期运行,保存历史记录和状态,方便调试和状态复用。
- 自定义浏览器集成:直接连接用户本地的Chrome等浏览器实例,无需重新登录或处理认证问题。
- 自动重试机制:在操作失败时自动尝试恢复(如重新加载页面、调整点击位置等),提升自动化脚本的鲁棒性。
- 错误日志与追踪:记录详细的操作日志和错误信息,便于定位问题。
- 预置动作库:封装了Playwright的底层API,提供如“点击元素”“滚动到指定位置”等高阶操作接口,简化代码编写。
- 自定义动作扩展:支持添加用户自定义动作(如保存数据到数据库、触发通知等),适应多样化场景。
- 多模型兼容性:除了OpenAI,还支持Anthropic、DeepSeek、Ollama等模型,用户可按需选择。
- 低成本方案适配:提供硅基流动等低成本模型的接入选项,降低AI代理的使用门槛。
- 结构化数据提取:自动从网页中提取表格、列表等结构化数据,减少手动解析代码的编写。
- 上下文关联操作:记录用户点击元素的XPath路径,确保后续操作的一致性(如重复执行相同流程)。
Browser Use通过自然语言交互、智能化错误恢复、多模型支持等特性,降低了浏览器自动化的技术门槛,同时扩展了复杂场景(如多标签并行、长会话任务)的处理能力。对于需要快速实现自动化且对稳定性要求较高的项目(如数据爬虫、自动化测试),Browser Use提供了更高效的解决方案。
Playwright简介
如何设计一个UI自动化测试框架,特别是如何利用Playwright这一现代化工具,结合实践中的挑战和未来趋势,帮助团队构建更为高效的自动化测试体系是自动化测试成功的关键。
框架设计的核心目标与原则
在设计 UI 自动化测试框架时,核心目标在于提升测试效率、增强可维护性,并确保框架具备良好的扩展能力。一个高质量的测试框架不仅能加快测试执行速度,还要保证测试用例的高复用性,同时确保测试结果的稳定可靠。在构建过程中,以下设计原则至关重要:
简洁性
框架应当保持精简,避免不必要的复杂性。优先满足核心需求,而非追求面面俱到的完美设计。
可复用性
测试框架应支持测试用例在不同场景中复用,以减少重复代码,提高开发效率。
稳定性
框架需要具备较强的稳定性,能够适应 UI 变更及环境波动,确保测试流程的可靠性和健壮性。
可扩展性
随着项目的发展,框架应具备灵活扩展的能力,以适应新的业务需求。架构设计应提前规划好,便于后续功能模块的无缝集成。
Playwright 在 UI 自动化测试中的优势
在众多 UI 自动化测试工具中,Playwright 以其强大的功能和高效的执行能力脱颖而出,成为测试工程师的优选方案。相比传统工具(如 Selenium),Playwright 具备诸多优势,尤其适用于现代 Web 应用的 UI 自动化测试。
跨浏览器兼容性
Playwright 原生支持 Chromium、Firefox 和 WebKit,无需额外配置,即可在多个浏览器环境中运行测试,极大提升了跨浏览器测试的便捷性。
高效且稳定
由于 Playwright 直接与浏览器通信,其测试执行速度快于 Selenium,并且在处理复杂 JavaScript 交互时表现更为稳定,减少了因元素加载或异步操作导致的测试失败。
丰富的 API 支持
Playwright 提供全面的 API,涵盖截图、视频录制、网络拦截、浏览器上下文管理等功能,使自动化测试更加灵活,可满足多种复杂测试场景。其强大的功能将在下文详细介绍。
如何高效拦截错误
可能有同学说,出现错误时对页面截图很容易,类似的selenium也可以实现。但是达到同样的效果,playwright可能会更加简便,示例代码:
from playwright.sync_api import sync_playwright, TimeoutError
def run(playwright):
browser = playwright.chromium.launch(headless=False)
context = browser.new_context()
page = context.new_page()
try:
# 这里放置你的测试代码
page.goto("https://example.com")
# 假设这里有一个会导致异常的操作
element = page.locator("non-existing-element").click(timeout=5000)
except TimeoutError as e:
# 当元素未找到时,捕获异常并保存截图
page.screenshot(path="error_screenshot.png")
print(f"An error occurred: {e}")
finally:
# 无论是否发生异常,都要确保关闭浏览器上下文
context.close()
browser.close()
with sync_playwright() as playwright:
run(playwright)在这个例子中,如果定位到不存在的元素时触发了TimeoutError异常,则会捕捉该异常并保存一个名为error_screenshot.png的截图。
实现视频录制
要录制测试过程中的视频,需要在创建浏览器上下文时,通过 record_video_dir 参数指定视频的存储路径。测试完成后,调用 context.close() 方法,以确保视频成功保存。以下示例演示了具体的实现方式:
from playwright.sync_api import sync_playwright
def run(playwright):
browser = playwright.chromium.launch(headless=False)
context = browser.new_context(record_video_dir="videos/") # 指定视频存储目录
page = context.new_page()
page.goto("https://example.com")
# 执行需要录制的操作
page.fill("#username", "test_user")
page.fill("#password", "password123")
page.click("button[type='submit']")
# 测试完成后,关闭上下文以保存视频
context.close()
browser.close()
with sync_playwright() as playwright:
run(playwright)在这个例子中,所有的操作都会被录制下来,并且视频文件会被保存在videos/目录下。每个视频文件都将有唯一的名称。
UI自动化框架设计的挑战
尽管构建UI自动化框架能够显著提高工作效率,但在实际开发过程中,我们常常会面临一系列难题。这些难题主要体现在以下几个方面:
框架的可维护性难题
随着测试用例数量的不断增加,框架的维护工作可能会变得愈发棘手。为了确保框架的稳定性和可扩展性,保持代码简洁明了、采用模块化设计理念显得尤为重要,这有助于降低后续维护的难度。
测试数据的管理挑战
UI测试高度依赖大量测试数据,如何高效管理这些数据并确保其准确性和有效性,是测试过程中不容忽视的一环。采用数据驱动的设计方法,可以有效提升测试数据的复用率,从而优化测试流程。
与开发团队的协同合作
自动化测试框架的设计离不开与开发团队的紧密配合。双方需共同协作,确保测试框架能够全面覆盖所有关键功能,同时避免遗漏任何重要的UI组件,以保障软件质量。
测试框架的结构与模块化设计
UI自动化测试框架的结构设计直接影响到其可维护性和可扩展性。常见的设计模式包括:
- 页面对象模型(Page Object Model,POM)
POM是UI自动化测试中最常用的设计模式。它通过将页面元素和操作封装在单独的类中,使得测试用例与UI实现解耦,提高了框架的可维护性。
- 数据驱动测试
数据驱动测试允许通过不同的数据集运行相同的测试用例,极大提高了测试的覆盖率和复用性。
- 行为驱动开发(BDD)
BDD可以帮助团队用更接近自然语言的方式描述测试场景,便于不同职能的人之间的沟通。
通过将框架分为多个模块,每个模块只负责特定的功能,能够有效提升框架的可维护性和扩展性。
自动化测试不是银弹
- 结合目前的现状看,自动化测试与手工测试还得结合使用,
虽然UI自动化测试能够显著提升测试工作的效率,但它并非适用于所有情况的全能解决方案。当面对那些界面极为复杂、交互操作频繁,或是需要精准模拟用户多样化行为模式的测试场景时,手工测试所展现出的灵活性和细致入微的观察力,依然有着自动化测试无法替代的独特优势。
正因如此,将自动化测试与手工测试有机结合,形成优势互补的测试策略,能够更全面、更深入地覆盖各种测试场景,从而有效提高测试工作的完整性和准确性。此外,我们也不应忽视其他新兴技术的潜力,例如人工智能(AI)技术,它在测试领域的应用同样值得我们深入探索和实践。
- 要不要自动化?
在项目启动之初,团队需审慎评估自动化测试的必要性。对于周期仅三个月的短期项目而言,投入自动化测试往往显得不切实际,此时应优先考虑更为灵活高效的测试策略。构建一个高效的UI自动化测试框架,不仅是对技术能力的严峻考验,更是团队协作精神的集中体现。
通过精心规划框架架构、巧妙运用Playwright等前沿测试工具,团队能够显著提升测试执行效率,有效降低后续维护成本。在软件开发环境日趋复杂的当下,这种以高效自动化测试框架为支撑的测试体系,将成为团队保持核心竞争力、应对各种挑战的关键所在。
走进Browser Use
横空出世的背景与意义
在互联网技术日新月异的当下,网页应用的功能日益多元,交互体验愈发丰富。从最初单纯的信息展示页面,到如今功能完备的在线办公系统、交易繁忙的电商平台,网页应用的复杂程度呈几何级数攀升,其测试难度也随之水涨船高。传统的自动化测试工具,在应对这些复杂多变的网页应用时,逐渐暴露出诸多短板,显得捉襟见肘。
就在这一困境之中,Browser Use 闪亮登场。它凭借前沿的 AI 技术,成功突破了传统测试工具的桎梏。Browser Use 能够迅速且精准地模拟用户在浏览器中的各种操作行为,对网页应用展开全方位、深层次的测试。它的出现,为网页自动化测试领域注入了全新的活力,带来了别具一格的思路与高效实用的方法。通过 Browser Use 的应用,测试效率与质量得到了显著提升,更为整个软件测试行业的蓬勃发展提供了强大助力。
核心功能介绍
1. 通用大型语言模型(LLM)兼容支持
Browser Use 展现出卓越的通用性,能够与多种主流大型语言模型(LLM)实现无缝对接,像 OpenAI 的 GPT 系列、Google 的 BERT 等均在其兼容列表之中。这一特性赋予用户极大的自主选择权,可依据自身需求与偏好,挑选最契合的语言模型来驱动测试流程。
以某些对语言理解精度要求严苛的测试场景为例,GPT 系列模型凭借其强大的自然语言解析能力,能够精准剖析复杂的指令,为测试工作提供坚实有力的支持。不同的大型语言模型在各自擅长的应用场景中优势尽显,Browser Use 的这种高度兼容性,使用户能够充分挖掘各模型的长处,从而达成最佳的测试效果。
2. 网页交互元素智能检测
Browser Use 具备一项令人瞩目的能力——自动检测网页交互元素。当加载一个网页时,它能以极快的速度识别出页面中的各类交互元素,如按钮、文本框、下拉菜单、链接等。
这一功能极大地简化了测试脚本的编写流程。在过去,测试人员需要手动定位这些元素的位置和属性,不仅操作繁琐,还极易出错,且效率低下。如今,Browser Use 自动完成这一工作,为后续的自动化测试操作筑牢了基础。例如,在测试电商网站的购物流程时,它能迅速定位“添加到购物车”按钮、“结算”按钮等关键交互元素,为模拟用户购物操作做好充分准备。
3. 便捷的多标签管理功能
在实际的网页浏览与测试过程中,多标签操作屡见不鲜。Browser Use 的多标签管理功能,让用户能够在一个测试会话中轻松驾驭多个浏览器标签。用户可以在不同标签间自由切换、操作,就如同日常浏览网页一般自然流畅。
这一功能在需要同时测试多个页面交互的场景中尤为实用。比如,在测试社交平台时,可能需要在一个标签中登录账号,在另一个标签中查看好友动态。通过多标签管理功能,Browser Use 能够轻松模拟这种复杂的操作流程,有效提升测试的全面性和准确性。
4. 强大的 XPath 数据提取能力
XPath 作为在 XML 文档中定位元素的重要语言,在网页测试中对于精准获取特定元素数据起着关键作用。Browser Use 提供了强大且高效的 XPath 提取功能,用户借助它可以快速、准确地从网页中抓取所需数据。
无论是网页中的文本内容、图片链接,还是表格数据等,都能通过 XPath 表达式轻松获取。例如,在进行数据抓取任务时,通过编写合适的 XPath 表达式,Browser Use 可以从新闻网站页面中提取出所有文章的标题、作者、发布时间等信息,为后续的数据分析和处理提供了极大便利。
5. 先进的视觉模型支持
为进一步提升自动化测试的准确性,Browser Use 引入了视觉模型支持。它能够模拟人类的视觉感知,“看”到网页的视觉内容,并通过分析页面的布局、颜色、图像等信息,更深入地理解网页的结构和功能。
这一功能在处理基于视觉的交互场景时尤为重要。例如,在测试图片编辑应用时,Browser Use 可以通过视觉模型识别出图片的裁剪区域、滤镜效果等,从而更精准地模拟用户操作,确保应用在各种视觉交互方面的功能正常运行。
6. 灵活的自定义动作功能
考虑到每个测试项目都有其独特需求,Browser Use 贴心地提供了自定义动作功能。用户可以根据自身测试需求,编写特定代码来定义新的操作。
例如,在测试特定行业的专业软件时,可能存在一些特殊的业务流程和操作方式。通过自定义动作,用户可以将这些特殊操作融入测试流程中,使 Browser Use 能够满足各种个性化的测试需求。
7. 出色的动态内容处理能力
现代网页应用中充斥着大量动态内容,如实时更新的新闻资讯、滚动加载的商品列表等。Browser Use 在处理动态内容方面表现卓越,它采用先进技术手段,能够实时监测网页内容的变化,确保在动态环境下也能精准执行测试任务。
例如,在测试股票交易平台时,股票价格等数据实时动态变化,Browser Use 可以及时捕捉这些变化,验证平台在数据更新和显示方面的正确性,有力保障了测试的有效性。
8. 链式思维提示与记忆功能
在处理长期复杂的任务时,Browser Use 的链式思维提示与记忆功能发挥着重要作用。它能够依据之前的操作和结果,生成合理的下一步操作建议,仿佛拥有了自主“思考能力”。
同时,它还能牢记之前的操作步骤和相关信息,避免重复劳动,提高测试效率。比如,在模拟用户在电商平台上的长期购物行为时,它可以记住用户已浏览过的商品、添加到购物车的商品等信息,并根据用户的购买习惯和操作逻辑,继续进行后续操作,如结算、选择配送方式等。
9. 高效的自我纠正机制
在自动化测试过程中,难免会遇到各种意外情况导致测试出错。Browser Use 具备自我纠正功能,当检测到测试出现错误时,它能够自动分析错误原因,并尝试进行自我修复。
例如,在点击一个按钮时,如果因网络延迟等原因导致点击失败,它可以自动重试,或者调整操作策略,确保测试能够顺利推进,大大提高了测试的稳定性和可靠性。
Browser Use的核心原理
1、自然语言处理(NLP)的非凡魅力
Browser Use 能够精准理解用户输入的自然语言指令,这背后离不开其卓越的自然语言处理能力。它借助前沿的 NLP 算法,对用户输入的文本展开深度剖析,涵盖词法分析、句法分析以及语义理解等多个层面。
在词法分析阶段,它会将输入的文本巧妙拆解为一个个独立的单词或词组,并精准判定它们的词性;句法分析则聚焦于解析这些单词之间的语法关联,精心构建出句子的语法架构;而语义理解则是在前两者的坚实基础上,充分结合上下文信息,精准把握用户的真实意图。
以用户输入“点击页面上的登录按钮”这一指令为例,Browser Use 的 NLP 模块会迅速识别出“点击”为动作动词,“登录按钮”为动作对象。随后,通过对网页结构的细致分析,精准定位到对应的按钮元素,并果断执行点击操作。
2、与大型语言模型(LLM)的深度融合创新
Browser Use 与大型语言模型的深度融合,是其攻克复杂自动化测试任务的核心技术法宝之一。LLM 经过海量数据的精心训练,具备强大的语言理解和生成能力。
Browser Use 会将用户的测试需求巧妙转化为语言模型能够轻松理解的格式,并发送给它进行处理。LLM 凭借其深厚的知识储备和丰富的经验,生成与之对应的测试步骤和操作指令。之后,Browser Use 再将这些指令无缝转化为实际的浏览器操作。
比如,在测试一个复杂的在线表单填写功能时,用户输入“填写所有必填字段并提交表单”这样的指令。LLM 会深入分析表单中需要填写的各个字段,并精心生成相应的填写内容和操作步骤。Browser Use 则严格按照这些步骤,在浏览器中完美模拟用户的填写和提交操作。
3、浏览器自动化技术的精湛施展
Browser Use 巧妙运用了一系列先进的浏览器自动化技术,实现对浏览器的精准操控。它通过调用浏览器的开发者工具接口,能够高度模拟用户的各种操作,如点击、输入、滚动等。同时,它还能实时监控浏览器的各类事件,如页面加载完成、元素出现或消失等。
以模拟用户登录操作为例,Browser Use 可以通过接口精准定位到用户名和密码输入框,模拟用户输入账号和密码,然后触发登录按钮的点击事件。在页面加载过程中,它会实时跟踪页面的加载状态,确保在页面完全加载后再推进下一步操作,从而有力保障测试的准确性和稳定性。
Browser Use实战示例
1. 环境安装
在开始使用 playwright 之前,需要安装相关依赖,建议在Python3.11以上环境操作:
pip3 install playwright
playwright install
如果使用 pytest 进行自动化测试,可额外安装:
pip install pytest pytest-playwright
2、添加API密钥
如果使用的是需要API密钥的语言模型(如OpenAI的GPT系列),需要将API密钥添加到环境变量中。在Linux或macOS系统上,可以在终端中运行:
export OPENAI_API_KEY = your api key
3、代码示例
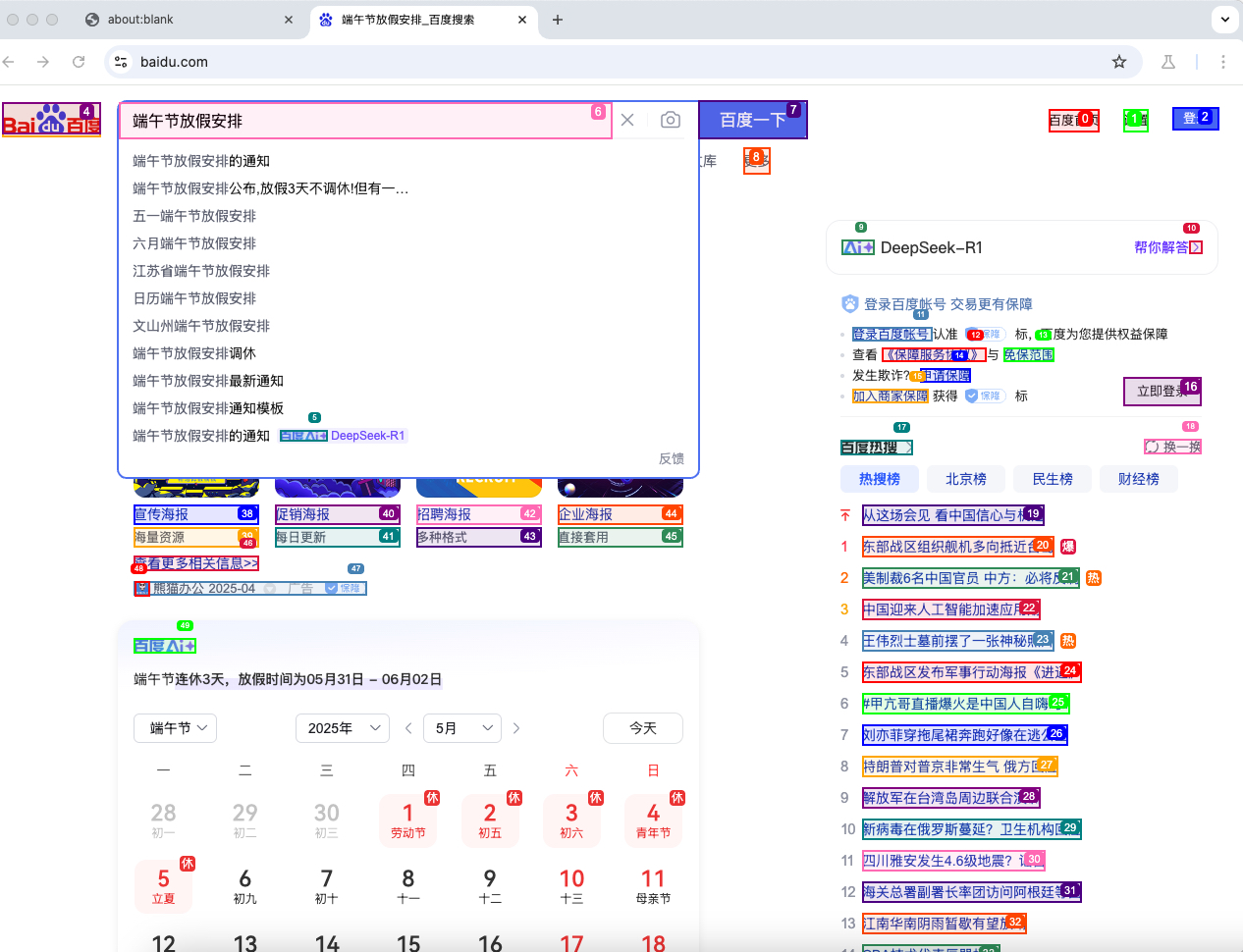
需求:打开百度自动查询今年的端午节放假日期,
browser_use_demo.py
from langchain_openai import ChatOpenAI
from browser_use import Agent
import asyncio
llm = ChatOpenAI(model="gpt-4o")
async def main():
agent = Agent(
task="打开百度首页,在输入框中输入:端午节放假安排,然后点击百度一下按钮,最后从搜索结果中找出准确的放假时间,要求使用中文输出结果。",
llm=llm,
)
result = await agent.run()
# print(result)
asyncio.run(main())
运行脚本后,预期控制台的输出结果如下, 可以看出可以准确的输出结果:端午节的放假时间为5月31日至6月2日。
INFO [browser_use] BrowserUse logging setup complete with level info
INFO [root] Anonymized telemetry enabled. See https://docs.browser-use.com/development/telemetry for more information.
/opt/homebrew/lib/python3.13/site-packages/browser_use/agent/message_manager/views.py:59: LangChainBetaWarning: The function `load` is in beta. It is actively being worked on, so the API may change.
value['message'] = load(value['message'])
INFO [agent] 🚀 Starting task: 打开百度首页,在输入框中输入:端午节放假安排,然后点击百度一下按钮,最后从搜索结果中找出准确的放假时间,要求使用中文输出结果。
INFO [agent] 📍 Step 1
INFO [agent] 🤷 Eval: Unknown - No previous action was performed.
INFO [agent] 🧠 Memory: 0 out of 1 tasks completed. Need to open Baidu and search for holiday schedule.
INFO [agent] 🎯 Next goal: Open the Baidu homepage.
INFO [agent] 🛠️ Action 1/1: {"open_tab":{"url":"https://www.baidu.com"}}
INFO [controller] 🔗 Opened new tab with https://www.baidu.com
INFO [agent] 📍 Step 2
INFO [agent] 👍 Eval: Success - Baidu homepage opened.
INFO [agent] 🧠 Memory: 0 out of 1 tasks completed. Need to search for Duanwu Festival holiday arrangements.
INFO [agent] 🎯 Next goal: Input '端午节放假安排' into the search box and click '百度一下' button.
INFO [agent] 🛠️ Action 1/2: {"input_text":{"index":12,"text":"端午节放假安排"}}
INFO [agent] 🛠️ Action 2/2: {"click_element":{"index":13}}
INFO [controller] ⌨️ Input 端午节放假安排 into index 12
INFO [agent] Something new appeared after action 1 / 2
INFO [agent] 📍 Step 3
INFO [agent] 👍 Eval: Success - Search was performed for '端午节放假安排'.
INFO [agent] 🧠 Memory: 0 out of 1 tasks completed. Found accurate holiday dates for Duanwu Festival. Dates are May 31st to June 2nd.
INFO [agent] 🎯 Next goal: Conclude the task by summarizing the holiday dates.
INFO [agent] 🛠️ Action 1/1: {"done":{"text":"端午节的放假时间为5月31日至6月2日。","success":true}}
INFO [agent] 📄 Result: 端午节的放假时间为5月31日至6月2日。
INFO [agent] ✅ Task completed
INFO [agent] ✅ Successfully
因为我们没有开无头模式,所以在执行过程中也可以看到模拟人工的整个操作过程,如:打开浏览器及输入qeury等,示例图如下:
Briwser Uer的局限性和挑战
第一个demo调通后还是比较兴奋的,但实际上后面试了很多场景,都没有一次成功,哪怕是简单的任务:“查询4月3日从北京首都机场到武汉天河机场最便宜的机票,然后打印出结果”。
还得看任务的复杂度,比如:总结网页内容、写一封邮件等这种对于结果容忍度比较高的场景比较合适。
尽管Browser Use已经取得了很大的进展,但在技术上仍面临一些挑战。例如,语言模型的输出有时可能不够稳定,会出现理解错误或生成不合理的操作指令的情况。此外,随着浏览器技术的不断更新,Browser Use需要及时跟进,以支持新的浏览器功能和API。在处理一些复杂的网页结构和动态加载内容时,也可能会遇到性能瓶颈和识别不准确的问题。
在实际应用中,Browser Use可能会遇到一些复杂的场景,如需要处理复杂的验证码、绕过反爬虫机制等。同时,对于一些对安全性要求极高的应用,如何确保Browser Use的操作不会对系统造成安全风险,也是需要解决的问题。此外,在与企业现有的测试流程和工具集成时,可能会面临兼容性和数据交互的问题。
持续关注和学习
1.技术优化:针对语言模型输出不稳定的问题,可以通过增加更多的训练数据、优化模型的训练算法、引入纠错机制等方式来提高其稳定性和准确性。对于浏览器技术更新的问题,测试团队需要密切关注浏览器的发展动态,及时更新Browser Use的代码,以支持新的功能和API。在处理复杂网页结构和动态加载内容时,可采用更先进的解析算法和异步加载处理技术,提升性能和识别的准确性。
2.应用改进:在面对复杂验证码时,可以集成第三方验证码识别服务,或者利用机器学习算法进行自定义的验证码识别训练。绕过反爬虫机制则需要深入研究目标网站的反爬虫策略,采用合理的伪装技术、控制请求频率等方式来规避。为确保安全性,在对敏感应用进行测试前,进行全面的安全评估和模拟攻击测试,确保Browser Use的操作不会被恶意利用。在与企业现有流程和工具集成方面,开发专门的适配器和接口,确保数据能够顺畅交互,并与现有工具形成互补,共同服务于企业的测试流程 。
小结
技术的发展是飞速的,我们需要以开放的心态去拥抱变化,持续关注最新的技术动态,实践出真理,找到合适的场景比随大流更重要。



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











