









引言
Wenpeng Yin等发表在arXiv上的论文,原文地址:地址
这应该是第一篇提出Attention用于CNN的文章,主要用来解决句子对的问题,作者在answer selection (AS),、paraphrase identification(PI)、textual entailment (TE)三个任务上进行实验,均取得了不错的结果。
作者提出,在以往的很多模型中,都是在特定的任务中对句子进行微调或者独立为每个句子生成语义表示,还有利用语言学上的方法,这些方法都没有考虑到句子间的一些相互依赖的信息,如

其中
s
0
s_0
s0为原始问句,
s
1
+
s^+ _1
s1+与
s
1
−
s^- _1
s1−为对应任务中的正确与错位候选句子,可以看到,在句子对中要找到对应的答案,所需要关注的位置是各不相同的,比如在AS中需要关注 gross 与 earned 等。
模型
BCNN: Basic Bi-CNN
基础的CNN模型,没有Attention,用于对句子对建模。模型中构建了两个并列的CNN层分别对句子进行特征提取,两个层之间共享卷积参数,后续再进行pool等常规操作,最后用一个logistic regression进行分类。
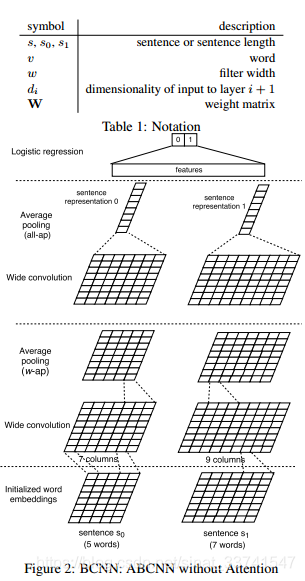
Input layer
上图中,输入句子长度 s s s分别为5和7,词向量维度为 d 0 d_0 d0,构造成两个feature map,大小为 d 0 ✖ s d_0✖s d0✖s
Convolution layer
卷积层使用的是宽卷积的方式,边缘处用0进行padding,最后得到
s
+
w
−
1
s+w-1
s+w−1长度的feature 矩阵,如下:
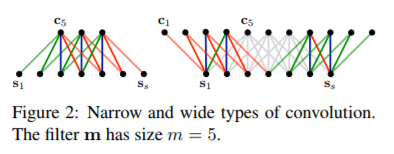
需要注意的是这里并不是per dim卷积的方式,依旧是dim wise卷积,对于每个卷积核最终生成的都是一个
s
+
w
−
1
s+w-1
s+w−1长度的一维向量,之后将多个卷积核生成的结果拼接起来得到Figure 2中的形式,
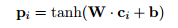
其中W为卷积核,
W
∈
R
d
1
✖
w
d
0
W∈R^{d_1✖wd_0}
W∈Rd1✖wd0,
c
i
c_i
ci为原始featurn map在边缘处padding 0后根据卷积核大小的切片,
c
i
∈
R
w
✖
d
0
c_i∈R^{w✖d_0}
ci∈Rw✖d0,
b
b
b为偏置。
Average pooling layer
w-ap
对于中间层的池化,作者采用了称为"w-ap"的方式,对于待池化矩阵,定义一个池化窗口大小 w w w,逐个窗口进行池化,最后生成 s − w + 1 s-w+1 s−w+1长度的feature map,经过卷积与池化操作最终feature map依旧为输入句子的长度s,因此可以重复进行多次特征提取的操作。
all-ap
对于最后一层pooling,采用了columns wise的方式,最终得到一个row长度的一维向量。
output layer
最终针对特定任务增加一个层,这里做的是分类任务,所以采用了逻辑回归。作者提到,在很多任务中,如果将所有pooling层输出矩阵都进行处理,比如增加一个all-ap后作为输入到分类器中,对于结果会有一定提升,原因是可能不同深度的卷积层能提取到不同维度的信息。
ABCNN: Attention-Based BCNN
ABCNN-1
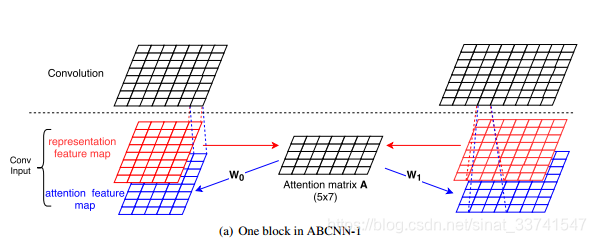
基本的想法是在卷积之前,根据两个句子的feature map生成一个Attention matrix A,之后将矩阵A与参数W进行矩阵乘法,构造一个与原始feature map大小一致的新attention feature map作为卷积输入的另一个通道,之后再进行卷积池化等操作,希望attention feature map能够在卷积操作时起到有关注点的抽取特征,
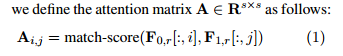
其中
m
a
t
c
h
−
s
c
o
r
e
=
1
/
(
1
+
∣
x
−
y
∣
)
match-score=1/(1 + |x − y|)
match−score=1/(1+∣x−y∣),
∣
x
−
y
∣
|x-y|
∣x−y∣为欧几里得距离。最后得到的矩阵A为
s
✖
s
s✖s
s✖s的矩阵,相当于对句子1中的每一个词,都对句子2中的每一个词求相似度,结果组合成一个矩阵。
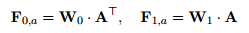
根据矩阵A就可以得到attention feature map,其中W为待训练参数。
ABCNN-2
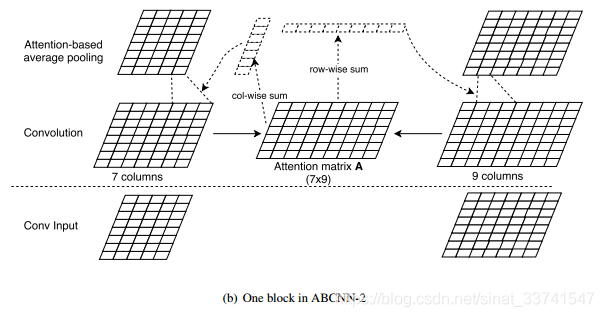
相比方法1在卷积前进行attention,方法2在pooling层前进行attention操作,构造attention matrix A的方式与方法1一致,但是在池化前对卷积的输出进行re-weight,具体的是分别对A进行col-wise sum与row-wise sum,分别得到一个对应的一维向量,即权重,之后再对卷积后的表达重新加权,池化等操作。
相比方法1,方法2的attention在更高维度上起作用,在卷积层之前的attention在词级别上起到作用,那进入池化层之前的attention则在短语级别起到作用,短语的长度取决于卷积的大小;同时方法2相对方法1来说计算量小了,没有参数W,在对抗过拟合方面会更强壮。
ABCNN-3
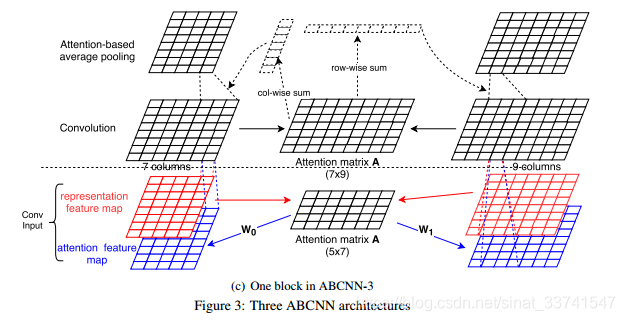
结合方法1和方法2的优点,作者提出了方法3,就是将两个模型合了起来。
实验
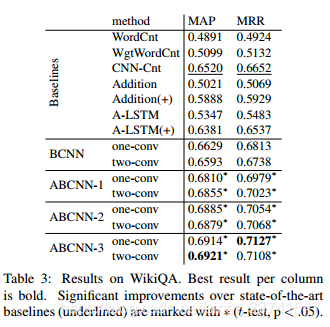
Answer Selection
Answer Selection(答案选择):给定一个问题,从候选答案池中找到最可能的正确答案。
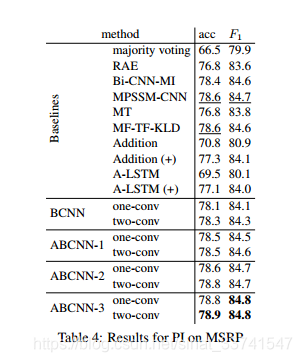
Paraphrase Identification
Paraphrase Identification(释义识别):给定两个句子,判断它们是不是表达同一个意思。
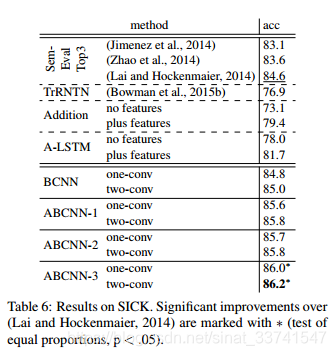
Textual Entailment
Textual entailment(文本蕴含):给定一句话作为前提,另一句话作为假说,去判断能否根据前提得到假说。
总结
提出了在CNN中使用attention的思路,后续很多工作都基于此展开。
引用
1、ABCNN: Attention-Based Convolutional Neural Network for Modeling Sentence Pairs
2、A Convolutional Neural Network for Modelling Sentences














 723
723











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









