







笔记作者:王小草
日期:2018年10月30日
欢迎关注我的微信公众号“AI躁动街”

1 Background
说起深度学习和神经网络,图像处理一呼百应的“卷积神经网络CNN“也好,还是自然语言处理得心应手的”循环神经网络RNN”,都简直是脍炙人口、妇孺皆知。前者助力处理高维特征,后者聚焦掌控序列记忆,时而分道而行,时而也互相取暖,但也终是各司其职,自有短长。
然而,在深度学习中,还有一个不可或缺的灵魂角色,那就是注意力机制(attention machanisms),在本文要介绍的论文之前,attention machanisms还只是个在CNN和RNN襁褓中的配角,协助主角表现更优,虽也算不上是跑龙套,但也绝不会在剧情里独当一面。而本文要介绍的这篇发表于2017 NIPS 会议上的论文,不仅高捧attention,而且让它上位到了“is all you need”的至高点,吸睛的论文标题中不仅体现了学者们对于学术敢于创新与拍前浪的精神,也深刻体现了,恩,我们不只会搞硬学术,还会标题党和PR呢~(你就说像不像你妈妈转发的朋友圈“这个冬天,就吃这样东西就够了!”,“震惊!原来它有这样的作用!”)
2 Why is attention all we need?
抛开标题党的成分,为什么作者竟敢如此“鼓吹”attention的作用呢?自然也是有理有据,不打诳语。
1.文中,推翻原来使用CNN或RNN构建的encoder-decoder 网路,直接构建了一个只有attention machanisims的encoder-decoder 网络,取名为“transformer"
2.这个transformer,结合了CNN和RNN的优点,即善于平行计算,提高训练效率,又能有序列上的记忆,不逊于RNN的表现。
3.文中做了两个机器翻译的实验来证明:英文-德文翻译,英文-法文翻译,都取得了state of art 的成绩。
3 Why shoud we read this paper?
那么为什么2017年的这篇老论文,现在都2018年末了还要拿出来老生常谈呢?是不是已经过时了呢?然而并没有呢。许多传统的模型和传统的问题都巧妙借用了这篇论文的思想,甚至许多最新的文献中省去了介绍模型结构的篇幅,只说“细节你们自己去看’attention is all you need’那篇论文,我用的就是它的”,对,就是这么屌。
4 How Transformer works?
写了这么多废话,终于进入了期待已久的高潮,按照论文的结构,(1)先介绍整个模型的结构,有一个全局观;(2)再对模型中的每一个小结构详细介绍。就像男生看到美女,先上下全身打量一下,恩,一个字,美,然后再细看脸,胸,腰,臀,大长腿。不过有些男生看到这里可能要不高兴我妄加比喻:我们明明是只看胸好吗?行行行,你开心就好。
4.1 the architecture of full model
理解这个模型要分两个部分:encoder部分和decoder部分,只是这里的encoder和decoder中使用的已经不是CNN或者RNN的结构了,而是attention机制。先看一眼整个模型的结构图:
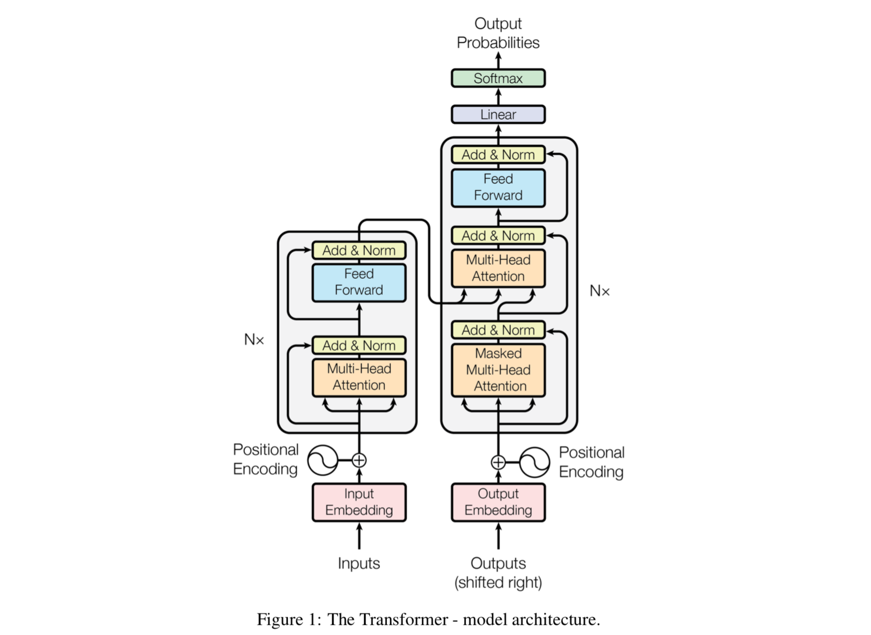
左边是encoder部分,右边是decoder部分,两部分以某种暧昧的方式藕断丝连地牵扯着。
4.1.1 Encoder
先来说说Encoder部分。
Encoder部分由特定的6个layer连接而成,这6个layer是6胞胎,性格长相一模一样,手拉手组成了encoder。于是我们只需要介绍其中一个layer的结构,也就明白了encoder的全貌了。下图是一个完整的layer所示:
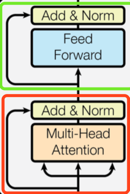
一个layer中包含两个sub layer.从下往上,第一个sub layer取名为multi-head self-attetion mechanisim(红框),第二个sub layer是positional wise fully connected feed-forward network(绿框)。
multi-head self-attetion mechanisim层的过程是:
(1)输入:x
(2)multi-head attetion计算:SubLayer(x)
(3)residul connection计算:x+ SubLayer(x)
(4)layer normalization计算:Layer Norm(x+ SubLayer(x))
positional wise fully connected feed-forward network层的过程是:
(1)输入:x(也就是multi-head self-attetion mechanisim层的输出)
(2)feed forward: x+ SubLayer(x)
(3)residul connection计算:x+ SubLayer(x)
(4)layer normalization计算:Layer Norm(x+ SubLayer(x))
该层的layer normalization的输出将会是下一个layer中第一个sub layer的输入,以此循环往复,直到第6个layer的positional wise fully connected feed-forward network层的输出,即为transformer中encoder的最终输出,这个最终输出要稍安勿躁得等待deocder的抛来爱的橄榄枝,即它将作为decoder的其中一个输入。
4.1.2 Decoder
在来说说Decoder部分。
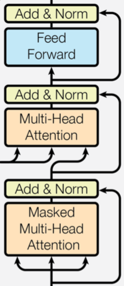
Decoder也有6个layer 组成,且巧了,这6个decoder也是一模一样的6胞胎。与encoder中不同的是,每个layer中有3个sub layer,新增的这个sub layer是插在3层的中间位置,它不仅接受decoder中上一个sublayer层的输入,而且还会将encoder的输出作为输入。 在每一个sub layer中,同样也使用了residul connection和layer normalization。
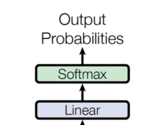
6层layer后面又接了一个linear层,因为输出其实是一个根据概率的分类问题,因此后面又接了一层softmax层。
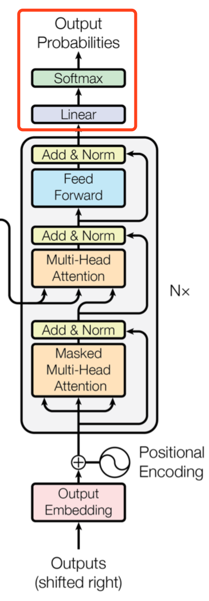
至此,我们大概了解了transformer model的大致结构,分成encoder和decoder两步,每步中各自有6个相同的layer。
4.2 详解Attention
了解了模型的整体架构,接下来就对模型的核心成员attention来做个认知吧~首先会介绍Scaled Dot-Product Attention,接着会介绍Multi-Head Attention。
4.2.1 Scaled Dot-Product Attention
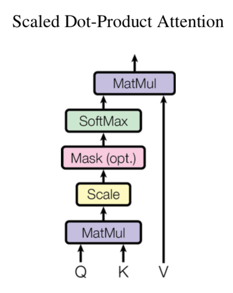
先来说一说这个叫Scaled Dot-Product Attention的东东。输入attention的一般是3个元素:queries(Q表示), keys(K表示,维度d_k), values(V表示,维度d_v),
计算的过程用文字描述是这样的:
(1)首先将Q和K进行点乘
(2)然后将乘积规模化,统一除以d_k开根号
(3)接着(2)的结果部分mask掉(可选)
(4)进过softmax层
(5)将(4)的结果与value进行点乘,得到最终的attention输出
用流程图描述是这样:
用公式描述是这样:
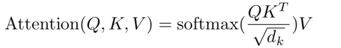
4.2.2 Multi-Head Attention
再来说说Multi-Head Attention,也就是上文architecture中屡次提到的,作为核心成员的注意力机制。同样是3个元素:queries, keys(K表示,维度d_k), values(Q表示,维度d_v)。
计算的过程用文字描述是这样的:
(1)先对输入的V,K,Q做一个线性变化
(2)然后将线性变化后的三者输入Scaled Dot-Product Attention,并且并行产生h个Scaled Dot-Product Attention
(3)将h个Scaled Dot-Product Attention的结果进行拼接
(4)将(3)的结果再进行线性变化,得到最终的Multi-Head Attention输出。
用流程图描述是这样:
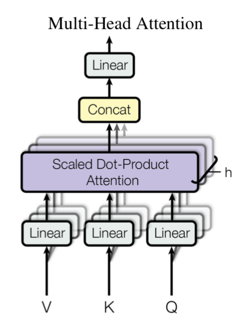
用公式描述是这样:

其中:
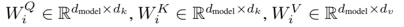
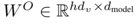
论文中作者采用h=8,并且: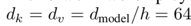 。
。
由于每一个head的维度都降低了,因此总的计算量并没有上升。
4.2.3 Attention在本文transformer模型中的应用
从整个transformer的模型结构中可以看到,有3个地方用了attention,第一是encoder中的self attention;第二是decoder中第一个sub layer,也是self attention;第三是decoder中的第二个sub layer, 接受encoder的输出为输入。
(1)encoder中的self attention中, key, value, quries都是相同的,都是上一层的输出。
(2)同样的,decoder中的self attention中, key, value, quries都是相同的,都是上一层的输出。
(3)特殊的是在"encoder-decoder attention" layer中,queries是来自decoder中上一层的输出,key和value都是encoder的输出。这么一来,允许encoder中的每一个位置都参与输入序列中的所有位置,模仿了在sequence-to sequence模型中的encoder-decoder机制。
3.3 详解Position-wise Feed-Forward Networks
在transformer Model中,除了attention,还有另一个即在encoder layer中又在decoder layer中用到的成员,即Position-wise Feed-Forward Networks(结果图中蓝色部分)。
这是一个全连接的前馈网络,过程如下:
(1)输入:x
(2)首先经过一个线性变换
(3)接着经过RELU激活函数
(4)然后再进行一个线性变换
写成公式如下:
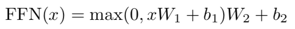
这个过程其实可以看做是做了两个卷积层,其中kenel size = 1,输入与输出的维度是512。
3.4 其他细节
以上分成3节讲述了整个模型的结构与构成,主要的两个组成部分:atttention和position-wise feed-forward network.本节要把剩下的细节和构件都讲述清楚,从而对模型建立全面的认知。
3.4.1 embedding
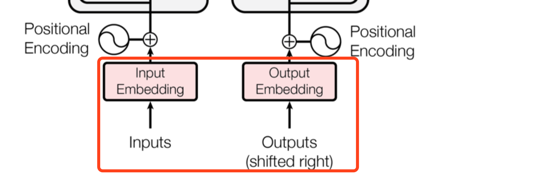
与其他传统的序列模型相似,这里也使用已经预训练好的词向量,将input和output中的词先转换成向量,维度是d_model。
3.4.2 softmax
同样,对于decoder的输出,会先经过一个linear计算,再进行softmax计算,这样就将结果转换成了预测下一个词的概率值。
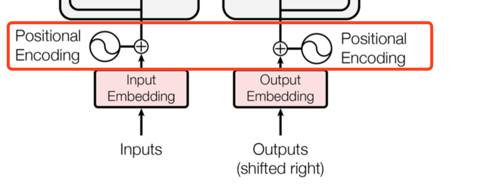
3.4.3 positional encoding
由于该模型中没有循环机制也没有卷积机制,为了使模型也能够利用词在句子中位置的信息,作者也通过某种方式引入了词在序列中的位置信息,那就是“positional encoding".
positional encoding的维度和词向量的维度是一致的:d_model,作者用不同频率的sine和cosine函数来对position形象编码:
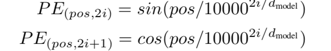
其中,pos是position, i是维度。也就是说,位置编码的每个维度都对应于一个正弦信号,波长组成几何级数从2π10000·2π。选择这个函数是因为我们假设它可以让模型很容易地通过相对位置学习,由于对于任何固定偏移量k, PEpos +k可以表示为PEpos的线性函数。
如何将词向量和位置向量这两个向量结合起来呢,因为维度一致可以直接相加,当然也有其他很多种方啦。
5 Training
现在来说说整个训练模型的过程。
5.1 训练数据
|信息|数据1|数据2
|-|-|
|数据来源|standard WMT 2014 English-German dataset|larger WMT 2014 English-French dataset |
|数据数量|4.5 million个句子对|36 million个句子对|
|总的词数|37000个词|32000个词|
句子对以近似的顺序长度分组在一起。每个培训批次包含一组句子,其中包含大约25000个源词和25000个目标词。
5.2 硬件
机器:one machine with 8 NVIDIA P100 GPUs
|信息|基本模型|大模型(参数更多|
|-|
|每一步训练时间|0.4秒|1秒|
|训练总步数|100000|300000|
|训练总时间|12小时|3.5天|
5.3 优化
优化器:Adam optimizer
|超参数|值|
|-|
|β1|0.9|
|β2|0.98|
|ε|10^-9|
|warm_step|4000|
learning rate:
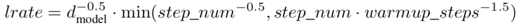
5.4 正则化
5.4.1 residual dropout
有两个地方使用的了dropout.
(1)对模型的每一个sub layer的输出进度dropout,也就是在模型结构图中Add&norm层前面的时候。
(2)在将token embedding和positional embedding相加之后,使用dropout, 而且在encoder和decoder部分都使用了。
因为文中分别构建了一个基本模型和一个大模型,基本模型中的dropout rate=0.1。
5.4.2 label smoothing
训练中,使用标签的平滑值ε = 0.1。
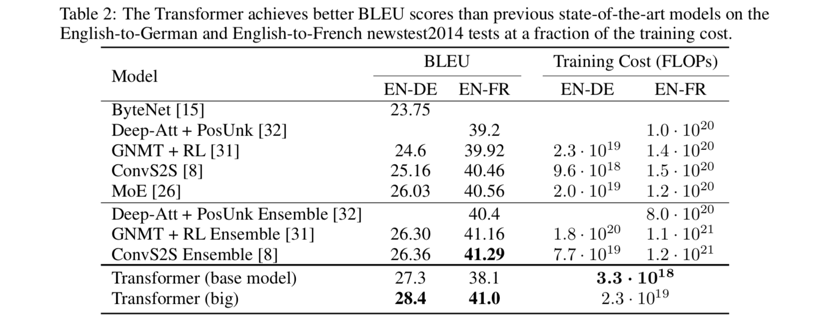
6 Results
作者在两组语言的翻译模型上分别做了实验。最后两行是transformer模型,一个事基本模型,一个较大模型,参数会更多,训练复杂度更高。
从结果看,tranformer比其他的翻译模型都要表现更优,且在训练的成本要小非常多。















 2760
2760











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









