







说明
数字图像处理书中对分水岭算法的定义和实现描述的很清楚,但都是专业术语,理解起来比较困难,需要多看几遍。网上原理讲的比较多,但代码基本没有,都是使用的Matlab或者OpenCV中现成的。
这边参照迷宫生成的方式,来一步步地将所有像素进行归类,然后进行处理,建议先去看下生成迷宫的代码,这样比较好理解一点,链接在最下面。
处理步骤
- 根据图片大小,生成所有可以拆卸的墙,这边的墙指的是两个像素点之间的空隙,通过这两个像素点的下标来指定一个唯一的墙,不可拆卸的墙指的是图片最外围一圈的墙无法拆除,墙的拆除顺序很大程度上影响程序的执行效率。图片遍历的坐标系在左上角,为了减少代码中find2()函数的循环次数,墙的拆除顺序需要从右下角开始,从右往左,从下往上,比从左上角开始快几个数量级,早上在床上想到通过调整拆墙顺序来解决执行慢的问题。
- 生成水面,并统计水面下的山谷的数量。这边代码分为两步,第一步生成山谷,生成山谷比较简单,将所有的墙都拆一遍,如果墙两边的像素点都在水面之下,直接拆掉,并把两个像素点合并为一个连通量,否则不拆除。这样最后所有的连通量就都在数组allArea 中了。第二步,遍历数组allArea 统计每个连通量的大小,将数量小于10的剔除掉。
- 水面上涨一个像素点,重新统计水面下山谷的数量,如果出现增多的情况,不用管。如果出现减少的情况,就说明有两个连通量合并了,我们需要找到导致两个连通量合并的那个像素点。
- 模拟最后一次水面上涨的情况,也就是导致两个连通量合并的那次水面上涨,重新拆墙,每拆一堵墙,判断一下连通量数量是不是少了,如果少了,那么就找到导致两个区域合并的那个墙了,也就找到对应的像素点了,我们需要在这个像素点建立一个高于水面的大坝,这样这个崩溃点就处理好了。然后还没有结束,我们继续拆墙,因为可能还存在其他的崩溃点,就这样,在当前水面高度下,找到所有崩溃点,并建立大坝。
- 提升水面,重复上面两个步骤,直到所有像素点都在水面之下,留下的突出水面之上的就是我们最后需要的大坝了。
效果图
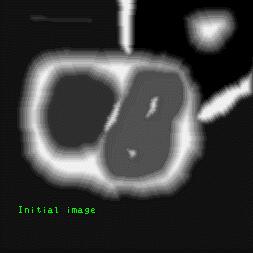
那一圈白色就是我们建立的大坝

代码部分
引入jar包
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<!-- java图片工具 https://mvnrepository.com/artifact/net.coobird/thumbnailator -->
<dependency>
<groupId>net.coobird</groupId>
<artifactId>thumbnailator</artifactId>
<version>0.4.12</version>
</dependency>
package com.example.watershed;
import net.coobird.thumbnailator.Thumbnails;
import org.junit.jupiter.api.Test;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.IOException;
import java.util.*;
class WatershedApplicationTests {
// ================================================---0624---=================================================
// 迷宫的大小
private int size = 200*200;
// 迷宫的阶数
private int sqrt = (int)Math.sqrt(size);
// 记录每个像素点所属的连通分量
private int[] allArea = new int[size];
// 舍弃面积小于minArea的区域
private int minArea = 100;
public void initial2() {
// 初始化各个单元格所属的集合
for (int j = 0; j < size; j++) {
allArea[j] = -1;
}
}
/**
* 返回 i 所在集合的最大值
*
* @param i 单元格编号
* @return
*/
public int find2(int i) {
int result = i;
while (allArea[result] != -1) {
result = allArea[result];
}
return result;
}
/**
* 将 i 和 j 所在集合进行合并
*
* @param i 单元格编号
* @param j 单元格编号
*/
public void union2(int i, int j) {
int result1 = find2(i);
int result2 = find2(j);
if (result1 == result2){
return;
}
if(result1 > result2) {
allArea[result2] = result1;
}
else {
allArea[result1] = result2;
}
}
/**
* 获取崩溃点(编号)和被合并的区域(头节点)
* @param i
* @param j
* @param waterHeight
* @param tempAllArea
* @return
*/
public Map<String, Integer> unionAndPrint(int i, int j, int waterHeight, int[] tempAllArea) {
int result1 = i;
while (tempAllArea[result1] != -1) {
result1 = tempAllArea[result1];
}
int result2 = j;
while (tempAllArea[result2] != -1) {
result2 = tempAllArea[result2];
}
if (result1 == result2){
return null;
}
// 用于将合并后的两个集合重新分开来
int loser = 0;
if (result1 > result2) {
tempAllArea[result2] = result1;
loser = result2;
} else {
tempAllArea[result1] = result2;
loser = result1;
}
// 判断区域是否减少
// 对每个区域的头节点进行寻根操作,如果最终寻得的根比头节点的数量少,表示区域减少了,因为水面是一直扩张的,所以寻根操作是可行的
Set<Integer> rootPoints = new HashSet<>();
for (Integer temp2 : areaHeadPoints) {
int result3 = temp2;
while (tempAllArea[result3] != -1) {
result3 = tempAllArea[result3];
}
rootPoints.add(result3);
}
// 区域减少
if (rootPoints.size() < areaCount) {
Map<String, Integer> rtMap = new HashMap<>();
rtMap.put("loser", loser);
//rtMap.put("breakPoint", i);
System.out.println("溃堤点:" + i);
return rtMap;
}
return null;
}
/**
* 带编号的
* 统计数组中的区域以及区域的大小
* @return
*/
public Map<Integer, Integer> statisticsArea(int waterHeight) {
Map<Integer, Integer> map = new HashMap<>();
Map<Integer, Integer> retMap = new HashMap<>();
for (int i=0; i<allArea.length; i++) {
int area = find2(i);
if (map.containsKey(area)) {
map.put(area, map.get(area) + 1);
} else {
map.put(area, 1);
}
}
// 舍弃面积小于minArea的区域
for (Map.Entry<Integer, Integer> item : map.entrySet()) {
if (item.getValue() > minArea) {
retMap.put(item.getKey(), item.getValue());
//System.out.println("水位:" + waterHeight + ", 区域:" + item.getKey() + ", 数量:" + item.getValue());
}
}
return retMap;
}
/**
* 获取所有的可拆的墙
* 从右下角开始,从右往左,从下往上,比从左上角开始快很多很多
* 因为极大的减少了find2()方法的耗时
*/
public List<Wall> getAllWalls() {
ArrayList<Wall> allWalls = new ArrayList<>();
// 保存下来所有的墙
// 一共size个元素
//for (int i = 0; i < (size - 1); i++) {
for (int i = (size - 2); i > 0; i--) {
// 右边的墙
int k = i + 1;
// 下面的墙
int l = i + (int) Math.sqrt(size);
// 排除掉最右边的墙
if ((i + 1) % ((int) Math.sqrt(size)) == 0) {
allWalls.add(new Wall(i, l));
continue;
}
// 排除掉最下面的墙
if ((size - Math.sqrt(size)) <= i) {
allWalls.add(new Wall(i, k));
continue;
}
allWalls.add(new Wall(i, k));
allWalls.add(new Wall(i, l));
}
return allWalls;
}
/**
* 保存关于墙所有的信息
*/
public class Wall {
// 墙对应的第一个单元格
private int firstCellCode = 0;
// 墙对应的第二个单元格
private int secondCellCode = 0;
// 横坐标
private int x = 0;
// 纵坐标
private int y = 0;
// x,y组成的坐标系
private String coordinate = "";
public Wall(int firstCellCode, int secondCellCode) {
this.firstCellCode = firstCellCode;
this.secondCellCode = secondCellCode;
if (sqrt == (secondCellCode - firstCellCode)) {
this.y = (secondCellCode % sqrt) * 2 + 1;
} else if (1 == (secondCellCode - firstCellCode)) {
this.y = (secondCellCode % sqrt) * 2;
}
this.x = firstCellCode / sqrt + 1;
this.coordinate = x + "," + y;
}
public int getFirstCellCode() {
return firstCellCode;
}
public int getSecondCellCode() {
return secondCellCode;
}
public String getCoordinate() {
return coordinate;
}
public int getX() {
return x;
}
public int getY() {
return y;
}
}
// 连通分量数量,用于判断连通分量是否存在合并的情况
private int areaCount = 0;
// 各个区域的头节点(各连通分量的编号)
private Set<Integer> areaHeadPoints = new HashSet<>();
/**
*
* @param bufferedImage
* @param waterHeight 水面高度
* @return
*/
private BufferedImage binaryImage22(BufferedImage bufferedImage) {
BufferedImage grayImage = new BufferedImage(200, 200, BufferedImage.TYPE_INT_RGB);
int width = grayImage.getWidth();
int height = grayImage.getHeight();
// 获取所有可拆卸的墙
List<Wall> wallList = getAllWalls();
// 初始化数组
initial2();
// 图片中所有像素点的值
int[] pixels = new int[width * height];
// 输出图像
int[] outPixels = new int[width * height];
// 水面最低高度
int startWaterHeight = 97;
// 水面最大高度
int endWaterHeight = 255;
// 读取图片,将所有像素点保存到pixels数组中
bufferedImage.getRGB(0, 0, width, height, pixels, 0, width);
// 记录所有被水淹没的区域
// 用于存储所有被水面淹没的区域,以及区域的面积(像素的个数)
Map<Integer, Integer> map = new HashMap<>();
// 记录上一步每个像素点所属的连通分量
// 用于找出水平面为n时,所有的溃堤点,值会变,不能用于恢复上一步状态
int[] tempAllArea = new int[size];
// 记录上一步每个像素点所属的连通分量
int[] tempAllArea2 = new int[size];
// 记录水平面上升时所有的溃堤点,也就是我们最终需要的大坝
Set<Integer> breakPoints = new HashSet<>();
// 从0开始提升水平面
for (int i=startWaterHeight; i<endWaterHeight; i++) {
// 复制数组
for (int j=0; j<allArea.length; j++) {
tempAllArea[j] = allArea[j];
tempAllArea2[j] = allArea[j];
}
// 速度比不初始化快点
initial2();
// 这边通过拆墙的方式来将两个相邻的像素进行合并,最终得到水平面为i时的淹没情况
// 查找水面下的像素,并添加到各自连通分量中
for (Wall item : wallList) {
int firstCode = item.getFirstCellCode();
int secondCode = item.getSecondCellCode();
int firstColor = pixels[firstCode];
int secondColor = pixels[secondCode];
int fb = firstColor & 0xff;
int sb = secondColor & 0xff;
// 如果两个相邻的像素点都在水面下,就把它们放到同一个连通分量中
if (fb < i && sb < i) {
union2(firstCode, secondCode);
}
}
// 统计当前有多少个连通分量(被水淹没的不相连的山谷)以及连通分量的大小
// System.out.println("水面高度:" + i);
map = statisticsArea(i);
// 如果区域减少,说明上一步的合并操作将两个连通分量合并为了一个连通分量,也就是存在溃堤点,
// 我们需要找到溃堤点,然后在溃堤点建立大坝
if (map.keySet().size() < areaCount) {
System.out.println("水面高度:" + i);
// 用于存放所有的疑似溃堤点
Set<Integer> pointSet = new HashSet<>();
// 疑似溃堤点,溃堤点存在于溃堤前和溃堤后的差别中
for (int j=0; j<allArea.length; j++) {
if (tempAllArea[j] != allArea[j]) {
pointSet.add(j);
}
}
// 对最后一次合并进行重现,从而发现溃堤点
// 重新执行拆墙,这些墙是疑似溃堤点对应的墙
for (Wall item : wallList) {
// 获取墙上面或者左面的像素点
int firstCode = item.getFirstCellCode();
// 获取墙下面或者右面的像素点
int secondCode = item.getSecondCellCode();
// 获取像素值
int firstColor = pixels[firstCode];
int secondColor = pixels[secondCode];
// 获取单色通道蓝色的值,灰色图像的rgb三个值是一样的
int fb = firstColor & 0xff;
int sb = secondColor & 0xff;
// 崩溃点比水面高度小1
if ((fb+1) == i || (sb+1) == i) {
// 只对疑似崩溃点对应的墙进行拆除
if (pointSet.contains(firstCode) || pointSet.contains(secondCode)) {
// 获取崩溃点(编号)和被合并的区域(头节点)
Map<String, Integer> rtMap = unionAndPrint(firstCode, secondCode, i, tempAllArea);
// 区域减少
if (rtMap != null && rtMap.get("loser") > -1) {
int point = 0;
// 崩溃点比水面高度小1
if ((fb + 1) == i) {
point = firstCode;
} else {
point = secondCode;
}
breakPoints.add(point);
// 将溃堤点从疑似溃堤点集合中移除
pointSet.remove(point);
// 将溃堤点补齐到水面上方
pixels[point] = 0xFFFFFF;
// 将两个合并的区域重新分开
tempAllArea[rtMap.get("loser")] = -1;
}
}
}
}
// 返回上一步,区域未合并的状态
for (int j=0; j<tempAllArea2.length; j++) {
allArea[j] = tempAllArea2[j];
}
i--;
} else {
// 如果连通分量不变,或者增多,则需要对连通分量数量进行更新
areaCount = map.keySet().size();
areaHeadPoints = new HashSet<>();
for (Integer item : map.keySet()) {
areaHeadPoints.add(item);
}
}
}
// 生成色卡
Map<Integer, Integer> colorMap = new HashMap<>();
for (Map.Entry<Integer, Integer> item : map.entrySet()) {
if (item.getValue() > minArea) {
Random random = new Random();
int r = random.nextInt(255);
int g = random.nextInt(255);
int b = random.nextInt(255);
int color = (clamp(r) << 16) | (clamp(g) << 8) | clamp(b);
colorMap.put(item.getKey(), color);
}
}
// 为每个像素点设置颜色
for (int i=0; i<allArea.length; i++) {
int area = find2(i);
if (map.get(area) != null && map.get(area) > minArea) {
outPixels[i] = colorMap.get(area);
}
if (breakPoints.contains(i)) {
outPixels[i] = (clamp(255) << 16) | (clamp(255) << 8) | clamp(255);
}
}
grayImage.setRGB(0, 0, width, height, outPixels, 0, width);
return grayImage;
}
/**
* 如果像素点的值超过了0-255的范围,予以调整
*
* @param value 输入值
* @return 输出值
*/
private static int clamp(int value) {
return value > 255 ? 255 : (Math.max(value, 0));
}
private int picWidth = 200;
@Test
public void testWaterShed() throws IOException {
String fromPic = "C:\\Users\\Administrator\\Pictures\\QQ截图20210626052237.jpg";
//String fromPic = "C:\\Users\\Dell\\Pictures\\QQ截图20210609144431.jpg";
BufferedImage bufferedImage = ImageIO.read(new File(fromPic));
// 压缩图片
BufferedImage compactImage = Thumbnails.of(bufferedImage).size(picWidth, 2000).asBufferedImage();
BufferedImage binaryImage = binaryImage22(compactImage);
// 保存图片
File newFile = new File("e:\\test8.jpg");
ImageIO.write(binaryImage, "jpg", newFile);
}
// ================================================---0624---=================================================
}















 7697
7697











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









