







mysql 查询优化技巧你知道哪些?
1:索引列类型尽可能的小
2:索引覆盖
3:最左匹配原则
4:使用索引扫描来做排序
那么问题来了,为什么索引列类型要尽可能小?索引覆盖又是什么?为什么要最左匹配?为什么要使用索引扫描来做排序?
在回答上述问题前,先简单的介绍一下mysql的索引全文以mysql innodb存储引擎B+树为例
索引数据结构
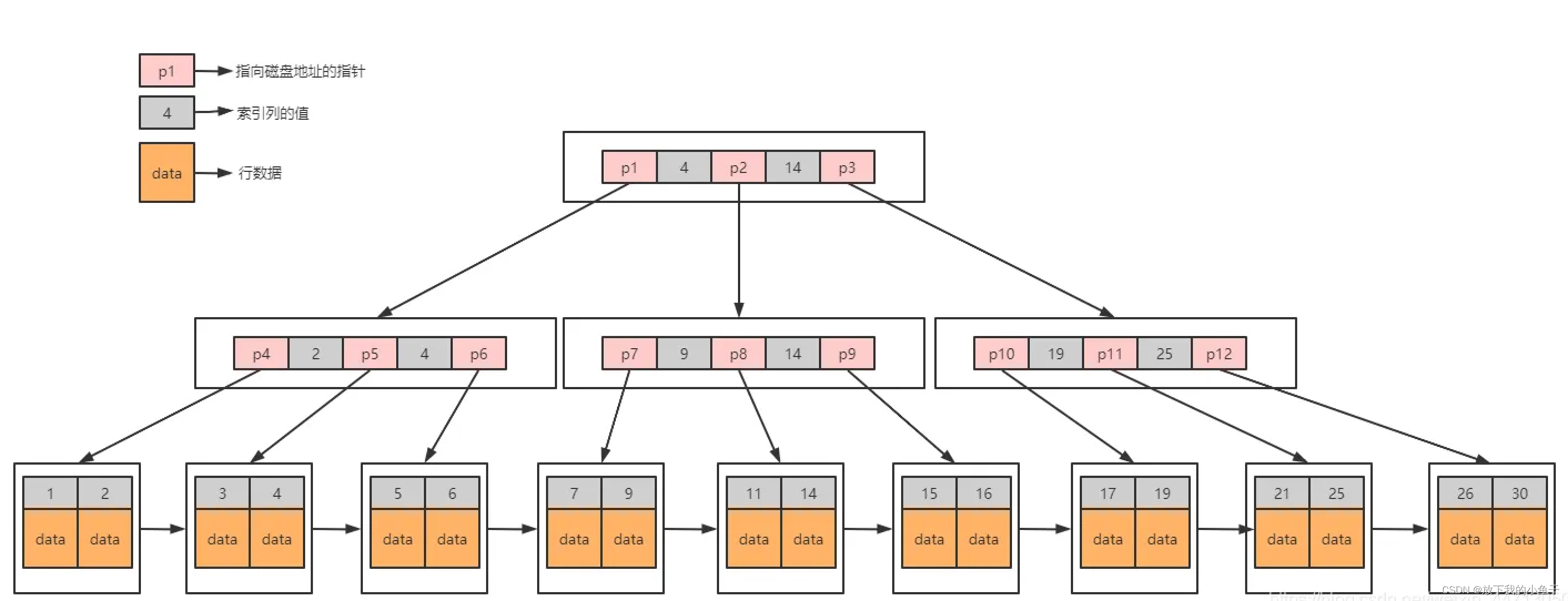
B+树是为磁盘或者其他直接存取辅助设备设计的一种平衡查找树。在B+树中,所有的记录节点都是按照键值的大小顺序存放在同一层的叶子节点上,由各叶子节点指针进行连接。下图B+树,高度为3,每页可存放2条记录,扇出为3
(扇出:是每个索引节点(non-leafPage)指向每个叶子节点(LeafPage)的指针)
(扇出数 = 索引节点(Non-LeafPage)可存储的最大关键字个数+1)
索引列尽可能的小
在数据库中,B+树的高度一般都在2 ~ 4 层,这样就是说查找某一键值的记录时最多需要2 ~ 4 次IO
数据库中数据是存储在磁盘上的,读取数据时就会涉及到io,io一般都是我们系统瓶颈,为了提高查询效率,在从磁盘读取数据时,我们要尽可能的少的去读取数据(次数少、数量少),同时保证读取到的数据足够有效,我们一般系统中数据量大的表数据我们不可能一次把数据全部读取到内存中。因此考虑分块读取。mysql数据库系统中磁盘跟内存进行交互时是以页为单位的。每页默认16k
假设一条数据是1k,mysql读取的一页数据就是16条,也就是一个叶子节点可以存储16条数据。对于非叶子节点,假设ID是bigint类型,那么长度为8B,指针大小在innoDB源码中为6B,一共就是14B,那么一页里面就可以存储16k/14B=1170个(主键+指针)。
一颗高度为2的B+树可以存储的数据为1170 * 16 = 18720条
一颗高度为3的B+树可以存储的数据1170 * 1170 * 16 = 21902400条
根据上面这个计算公式可以看出来,索引列值越小非叶子节点可存放的键值数据越多,在尽可能存储的数据量大的情况下减少io的次数。
索引覆盖
数据库中B+树的索引可分为聚集索引和辅助索引,上图即为我们说的聚集索引,聚集索引就是按照每张表的主键构造一颗B+树,同时叶子节点存放的整张表的行记录。辅助索引是按照我们创建的索引列构造的一颗B+树,叶子节点并不包含行记录的全部数据。叶子节点除了包含键值以外,每个叶子节点中的索引中还包含了一个书签,该书签用来告诉innodb存储引擎哪里可以找到与索引相对应的行数据。
如果一个索引包含(或者说覆盖)所有需要查询字段的值,就称为索引覆盖。
举个例子:假如一张数据表 order,数据如下。
| id | order_no | sku_name | shop_code | shop_name |
|---|---|---|---|---|
| 1 | 1001 | 商品1 | 101 | 门店1 |
| 2 | 1002 | 商品2 | 201 | 门店2 |
| 3 | 1003 | 商品3 | 301 | 门店3 |
| 4 | 1004 | 商品4 | 401 | 门店4 |
| 5 | 1005 | 商品5 | 501 | 门店5 |
| 6 | 1006 | 商品6 | 601 | 门店6 |
| 7 | 1007 | 商品7 | 701 | 门店7 |
以 门店编码 + 商品名称创建索引,那么索引的树结构
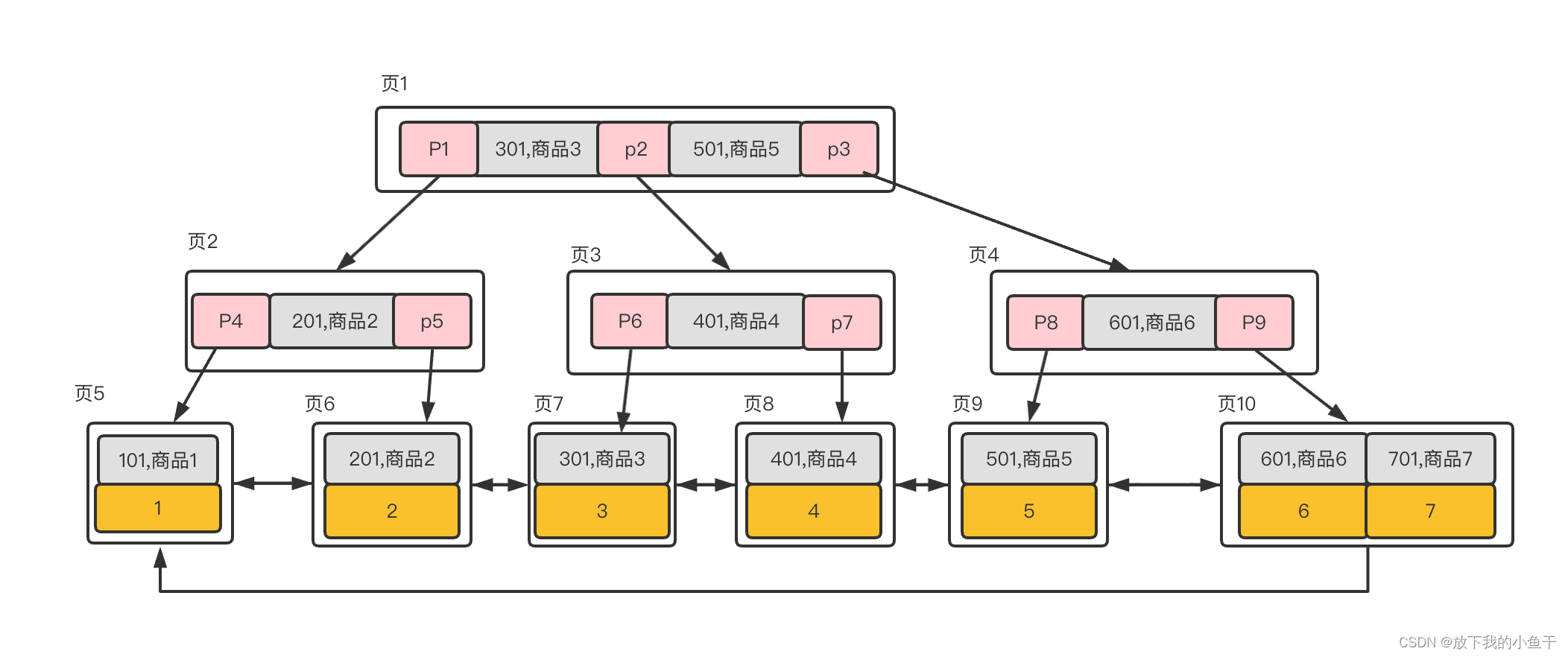
当通过辅助索引来寻找数据时,InnoDB存储引擎会遍历辅助索引并通过叶级别的指针获得指向主键索引的主键,然后通过主键索引来找到一个完整的行记录。
以查询所有列数据,查询条件为shop_code = '701’为例,我们需要遍历页1 ----> 页4 ---->页10在页10拿到对应的主键ID,然后再遍历主键索引,页1 —> 页3 —>页8,最终找到一个完整的行数据所在页,拿到完整的数据。一共需要6次io访问获得最终的数据页。
如果仅查询shop_code, sku_name列,查询条件为shop_code = '701’ 只要有页1、页4、页10 三次io
最左匹配原则
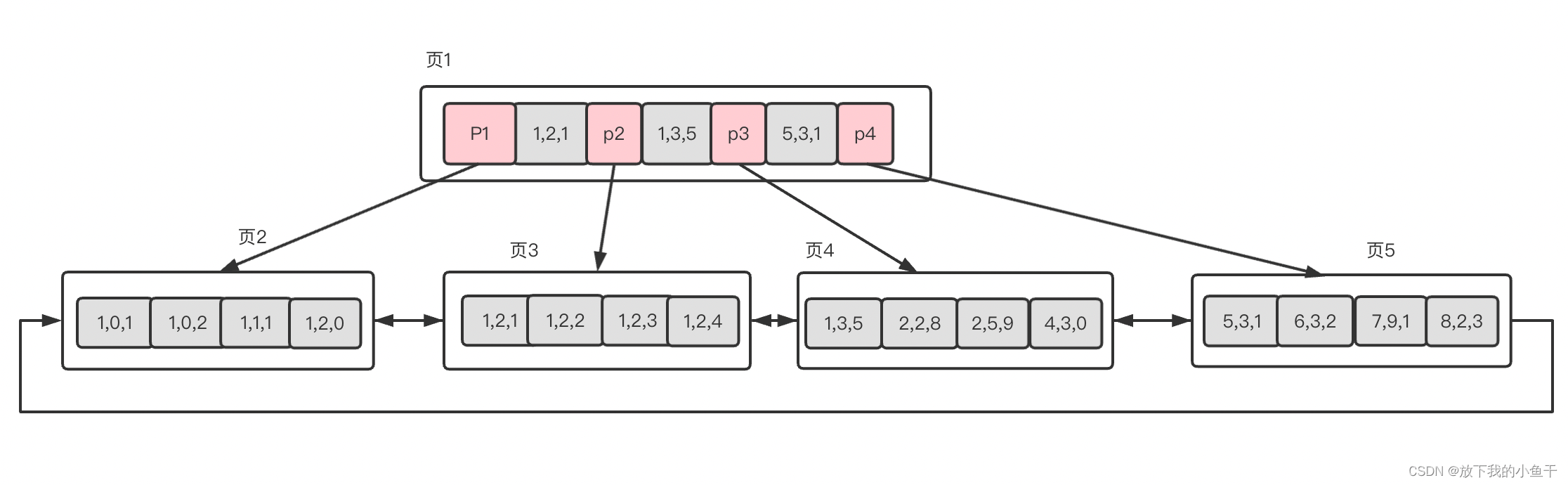
最左匹配主一般说的是在联合索引中的使用,假设用a、b、c三个字段创建索引,在组合索引中叶子节点存放的数据依然是有序的。先按照a排序,然后按照b进行排序,最后按照c进行排序。
根据上图组合索引的排序可以看出来在a列肯定是有序的,b列是在c列值相同的前提下才是有序地,c列是在a、b列相同的前提下有序的。所以查询数据的时候查询条件中只要用到了a列肯定是会走索引的,如果查询条件中不添加a列,那么仅有b、c列,数据查询是不走索引的。
假如查询a=2 的数据,查找数据的过程:
1、根据根节点找到页1,读入内存
2、在内存中根据二分查找算法确定a=2的数据位于p3指针指向的数据页
3、根据p3指针找到页4,读入内存
4、在内存中比较关键字2,找到数据(2,2,8)和(2,5,9)
使用索引扫描来做排序
索引列的顺序意味着索引首先是按照最左列进行排序,其次第二列,等等。所以索引可以按照升序或者降序进行扫描,以满足精确符合列顺序的order by。















 10万+
10万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









