






7-集成学习 Adaboost
一个集成样本不准 另一个准 运用好的样本 性能就能得到提升

Bagging
装袋算法
多个决策树会互补
通过去的分类性能会好于单个分类器 对每个基分类器,多个模型分类同时预测输出然后利用集成器进行集成输出
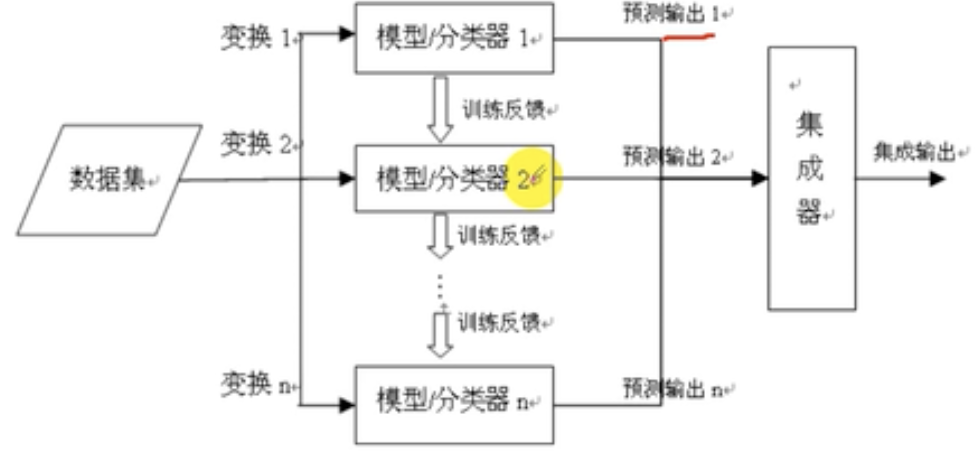
Bagging;又放回的训练集 取众数(投票)至于Bagging训练集取多少次 取决于调参
Bagging:要求不稳定的分类方法:决策树,神经网络算法
不稳定:数据集小的变动能够使得分类结果的显著的变动,列出所有的模型 计算所有的轮数
Bagging特点:
通过降低基分类器的方差改善了泛化误差。
Bagging的性能依赖于基分类器的稳定性:
如果基分类器不稳定(决策树 神经网络)装袋有助于降低训练数据的随机波动导致的误差 稳定算法bagging的性能不会有明显改善
由于每一个样本被选中的概率相同,因此袋装并不侧重于训练数据集中的任何特定实例,因此对于噪声数据,bagging不会太受过分拟合的影响
Boosting
Boosting是一个顺序过程,每个后续模型都会尝试纠正先前模型的错误。后续的模型依赖于之前的模型
第一步:从原始数据集创建一个子集
第二步:最初,所有的数据点都具有相同的权重
第三步:在此子集上创建基础模型
第四步:该模型用于对整个数据集进行预测
最终模型是所有模型的加权平均值 单个模型在整个数据集上表现不佳,但是整体的效果很好


Bagging & Boosting算法区别

Stacking Blending
每次训练一个模型就立刻给他压栈
RF
随机森林 随机有放回的抽样 随机属性选择

随机森林的可解释性比较差,容易发生过拟合 调参需要控制
RF使用
随机森林预测对方是否买车?
分析之后 决策树比随机森林高
gridSearchCV:

随机森林每一次都是最适合的调参去训练
调节最大决策树的个数;注意树的深度,不能太小!!!
样本不够 会导致获得信息不全面 泛化能力不够 需要加强 袋外模型打分具有很强的泛化性能
Adaboost
Adaptive Boosting 自适应提升
很多弱分类器 构成一个强分类器

错误的分类错误 增加权重

GBDT
对树的提升树
决策树可以用于分类 也可以用于回归
GBDT:每一次建立模型是在之前建立模型损失函数的梯度下降方向
是一种迭代的决策树算法,



无监督训练算法的核心就是 没有标签 只需要特征矩阵而其中聚类算法就是一个代表,
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-itXNxrjn-1667828552935)(https://cdn.staticaly.com/gh/hudiework/img@main/image-20221105203409082.png)]
聚类算法常用的两类:层次聚类 K均值聚类
聚类的核心是相似度 或者是距离
K均值聚类算法:

















 993
993











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









