







一、服务熔断基础概念
1.什么是服务熔断?
熔断机制这个词对你来说肯定不陌生,它的灵感来源于我们电闸上的 " 保险丝 ",当电压有问题时(比如短路),自动跳闸,此时电路就会断开,我们的电器就会受到保护。不然,会导致电器被烧坏,如果人没在家或是人在熟睡中,还会导致火灾。所以,在电路世界通常都会有这样的自我保护装置。
同样,在我们的分布式系统设计中,也应该有这样的方式。前面说过重试机制,如果错误太多,或是在短时间内得不到修复,那么我们重试也没有意义了,此时应该开启我们的熔断操作,尤其是后端太忙的时候,使用熔断设计可以保护后端不会过载。在互联网系统中,当下游服务因访问压力过大而响应变慢或失败,上游服务为了保护系统整体的可用性,可以暂时切断对下游服务的调用。
这种牺牲局部,保全整体的措施就叫做熔断。熔断的目的是为了防止异常不扩散,保证系统的稳定性
如果不采取熔断措施和采取熔断措施,我们的系统会怎样呢?我们可以参考下图
比如当前系统中有A,B,C三个服务,服务A是上游,服务B是中游,服务C是下游。
一旦下游服务C因某些原因变得不可用,积压了大量请求,服务B的请求线程也随之阻塞。线程资源逐渐耗尽,使得服务B也变得不可用。紧接着,服务A也变为不可用,整个调用链路被拖垮。
像这种调用链路的连锁故障,叫做雪崩。
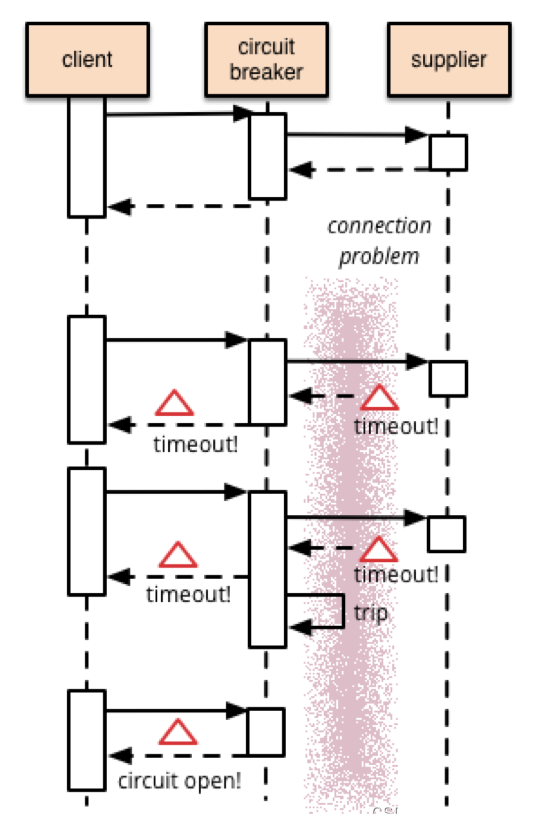
正所谓刮骨疗毒,壮士断腕。在这种时候,就需要我们的熔断机制来挽救整个系统。熔断机制的大体流程和刚才所讲的考试策略如出一辙:
熔断机制实现的另外一个关键是阈值的设计,例如 1 分钟内 30% 的请求响应时间超过 1 秒就熔断,这个策略中的“1 分钟”“30%”“1 秒”都对最终的熔断效果有影响。实践中一般都是先根据分析确定阈值,然后上线观察效果,再进行调优。
2.熔断机制的三种状态
对于熔断机制的实现,Hystrix设计了三种状态:
1.熔断关闭状态(Closed)
服务没有故障时,熔断器所处的状态,对调用方的调用不做任何限制。
2.熔断开启状态(Open)
在进入熔断状态后,后续对该服务接口的调用不再经过网络,直接执行本地的fallback方法。
在固定时间窗口内(Hystrix默认是10秒),接口调用出错比率达到一个阈值(Hystrix默认为50%),会进入熔断开启状态。
3.半熔断状态(Half-Open)
在进入熔断开启状态一段时间之后(Hystrix默认是5秒),熔断器会进入半熔断状态。
所谓半熔断就是尝试恢复服务调用,允许有限的流量调用该服务,并监控调用成功率。
如果成功率达到预期,则说明服务已恢复,进入熔断关闭状态;如果成功率仍旧很低,则重新进入熔断关闭状态。
4.三个状态的转化关系
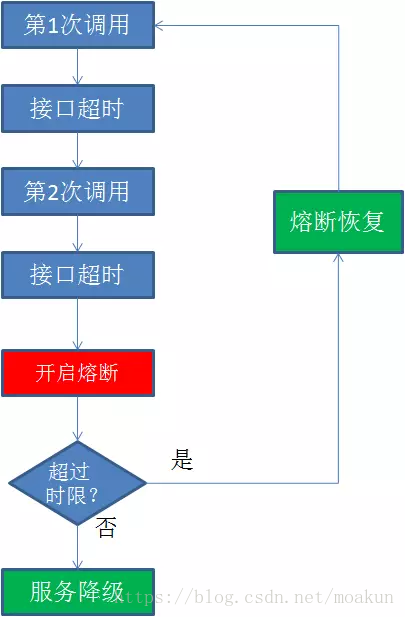
三个状态的转化关系如下图:

我们需要一个调用失败的计数器,如果调用失败,则使失败次数加 1。如果最近失败次数超过了在给定时间内允许失败的阈值,则切换到断开 (Open) 状态。此时开启了一个超时时钟,当该时钟超过了该时间,则切换到半断开(Half-Open)状态。该超时时间的设定是给了系统一次机会来修正导致调用失败的错误,以回到正常工作的状态。在 Closed 状态下,错误计数器是基于时间的。在特定的时间间隔内会自动重置。这能够防止由于某次的偶然错误导致熔断器进入断开状态。也可以基于连续失败的次数。
3.熔断设计的重点
在实现熔断器模式的时候,以下这些因素需可能需要考虑。
-
错误的类型。需要注意的是请求失败的原因会有很多种。你需要根据不同的错误情况来调整相应的策略。所以,熔断和重试一样,需要对返回的错误进行识别。一些错误先走重试的策略(比如限流,或是超时),重试几次后再打开熔断。一些错误是远程服务挂掉,恢复时间比较长;这种错误不必走重试,就可以直接打开熔断策略。
-
日志监控。熔断器应该能够记录所有失败的请求,以及一些可能会尝试成功的请求,使得管理员能够监控使用熔断器保护服务的执行情况。
-
测试服务是否可用。在断开状态下,熔断器可以采用定期地 ping 一下远程服务的健康检查接口,来判断服务是否恢复,而不是使用计时器来自动切换到半开状态。这样做的一个好处是,在服务恢复的情况下,不需要真实的用户流量就可以把状态从半开状态切回关闭状态。否则在半开状态下,即便服务已恢复了,也需要用户真实的请求来恢复,这会影响用户的真实请求。
-
手动重置。在系统中对于失败操作的恢复时间是很难确定的,提供一个手动重置功能能够使得管理员可以手动地强制将熔断器切换到闭合状态。同样的,如果受熔断器保护的服务暂时不可用的话,管理员能够强制将熔断器设置为断开状态。
-
并发问题。相同的熔断器有可能被大量并发请求同时访问。熔断器的实现不应该阻塞并发的请求或者增加每次请求调用的负担。尤其是其中对调用结果的统计,一般来说会成为一个共享的数据结构,它会导致有锁的情况。在这种情况下,最好使用一些无锁的数据结构,或是 atomic 的原子操作,或是使用redis这种高性能组件。这样会带来更好的性能。
-
资源分区。有时候,我们会把资源分布在不同的分区上。比如,数据库的分库分表,某个分区可能出现问题,而其它分区还可用。在这种情况下,单一的熔断器会把所有的分区访问给混为一谈,从而,一旦开始熔断,那么所有的分区都会受到熔断影响。或是出现一会儿熔断一会儿又好,来来回回的情况。所以,熔断器需要考虑这样的问题,只对有问题的分区进行熔断,而不是整体。
-
重试错误的请求。有时候,错误和请求的数据和参数有关系,所以,记录下出错的请求,在半开状态下重试能够准确地知道服务是否真的恢复。当然,这需要被调用端支持幂等调用,否则会出现一个操作被执行多次的副作用。
4.资源隔离
1.线程隔离
Hystrix会给每一个Command分配一个单独的线程池,这样在进行单个服务调用的时
候,就可以在独立的线程池里面进行,而不会对其他线程池造成影响
即每个服务单独一个线程池
2.信号量隔离
客户端需向依赖服务发起请求时,首先要获取一个信号量才能真正发起调用,由于信
号量的数量有限,当并发请求量超过信号量个数时,后续的请求都会直接拒绝,进入fallback流
程。
信号量隔离主要是通过控制并发请求量,防止请求线程大面积阻塞,从而达到限流和防止雪崩
的目的。
5.熔断和降级的关系
熔断和降级是两个比较容易混淆的概念,因为单纯从名字上看好像都有禁止某个功能的意思,但其实内在含义是不同的,原因在于降级的目的是应对系统自身的故障,而熔断的目的是应对依赖的外部系统故障的情况。熔断和降级在实践中一般都会搭配使用,例如当服务发生熔断后,一般会将请求引导在降级的实现方案中,完成整个链路的调用。
二、服务降级基础概念
1.什么是服务降级
所谓的降级设计(Degradation),本质是为了解决资源不足和访问量过大的问题。当资源和访问量出现矛盾的时候,在有限的资源下,为了能够扛住大量的请求,我们就需要对系统进行降级操作。系统可以将某些业务或者接口的功能降低,可以是只提供部分功能,也可以是完全停掉所有功能。例如,论坛可以降级为只能看帖子,不能发帖子;也可以降级为只能看帖子和评论,不能发评论;而 App 的日志上传接口,可以完全停掉一段时间,这段时间内 App 都不能上传日志。
降级的核心思想就是丢车保帅,优先保证核心业务。例如,对于论坛来说,90% 的流量是看帖子,那我们就优先保证看帖的功能;对于一个 App 来说,日志上传接口只是一个辅助的功能,故障时完全可以停掉。也就是说,暂时牺牲掉一些东西,以保障整个系统的平稳运行。
我记得我在伦敦参与诺丁山狂欢节的时候,以及看阿森纳英超足球比赛的时候,散场时因为人太多,所有的公交系统(公交车,地铁)完全免费,就是为了让人通行得更快。而且早在散场前,场外就备着一堆公交车和地铁了,这样就是为了在最短时间内把人疏散掉。
虽然亏掉了一些钱,但是相比因为人员拥塞造成道路交通拥塞以及还可能出现的一些意外情况所造成的社会成本的损失,公交免费策略真是很明智的做法。与此类似,我们的系统在应对一些突发情况的时候也需要这样的降级流程。
一般来说,我们的降级需要牺牲掉的东西有:
- 降低一致性。从强一致性变成最终一致性。
- 停止次要功能。停止访问不重要的功能,从而释放出更多的资源。
- 简化功能。把一些功能简化掉,比如,简化业务流程,或是不再返回全量数据,只返回部分数据。
2.降级的常见策略
1.降低一致性
我们要清楚地认识到,这世界上大多数系统并不是都需要强一致性的。对于降低一致性,把强一致性变成最终一致性的做法可以有效地释放资源,并且让系统运行得更快,从而可以扛住更大的流量。一般来说,会有两种做法,一种是简化流程的一致性,一种是降低数据的一致性。
1.使用异步简化流程
举个例子,比如电商的下单交易系统,在强一致的情况下,需要结算账单,扣除库存,扣除账户上的余额(或发起支付),最后进行发货流程,这一系列的操作。
如果需要是强一致性的,那么就会非常慢。尤其是支付环节可能会涉及银行方面的接口性能,就像双 11 那样,银行方面出问题会导致支付不成功,而订单流程不能往下走。
在系统降级时,我们可以把这一系列的操作做成异步的,快速结算订单,不占库存,然后把在线支付降级成用户到付,这样就省去支付环节,然后批量处理用户的订单,向用户发货,用户货到付款。
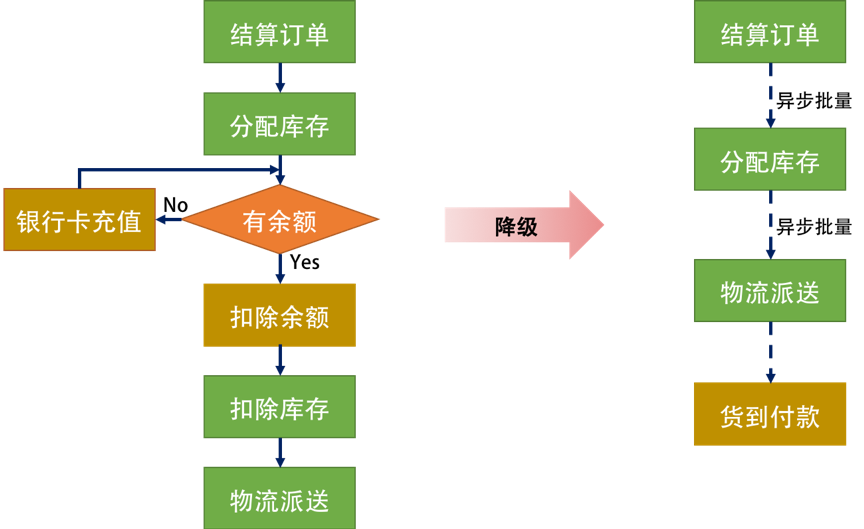
如上图所示,一开始需要的全同步的方式,降级成了全异步的方式,库存从单笔强一致性也变成了多笔最终一致性,如果库存不够了,就只能根据先来后到取消订单了。而支付也从最开始的下单请求时的强一致性,变成了用户到付的最终一致性。
一般来说,功能降级都有可能会损害用户的体验,所以,最好给出友好的用户提示。比如,“系统当前繁忙,您的订单已收到,我们正努力为您处理订单中,我们会尽快给您发送订单确认通知……还请见谅”诸如此类的提示信息。
2.降低数据的一致性
降低数据的一致性一般来说会使用缓存的方式,或是直接就去掉数据。比如,在页面上不显示库存的具体数字,只显示有还是没有库存这两种状态。
对于缓存来说,可以有效地降低数据库的压力,把数据库的资源交给更重要的业务,这样就能让系统更快速地运行。
对于降级后的系统,不再通过数据库获取数据,而是通过缓存获取数据。关于缓存的设计模式,在 CoolShell 中有一篇叫《缓存更新的套路》的文章中讲述过缓存的几种更新模式,你有兴趣的话可以前往一读。在功能降级中,我们一般使用 Cache Aside 模式或是 Read Through 模式。也就是下图所示的这个策略。

- 失效:应用程序先从 cache 取数据,如果没有得到,则从数据库中取数据,成功后,放到缓存中。
- 命中:应用程序从 cache 中取数据,取到后返回。
- 更新:先把数据存到数据库中,成功后,再让缓存失效。
Read Through 模式就是在查询操作中更新缓存,也就是说,当缓存失效的时候(过期或 LRU 换出),Cache Aside 是由调用方负责把数据加载到缓存,而 Read Through 则用缓存服务自己来加载,从而对应用方是透明的。
2.停止次要的功能
停止次要的功能也是一种非常有用的策略。把一些不重要的功能给暂时停止掉,让系统释放出更多的资源来。比如,电商中的搜索功能,用户的评论功能,等等。等待访问的峰值过去后,我们再把这些功能给恢复回来。
当然,最好不要停止次要的功能,首先可以限制次要的功能的流量,或是把次要的功能退化成简单的功能,最后如果量太大了,我们才会进入停止功能的状态。
停止功能对用户会带来一些用户体验的问题,尤其是要停掉一些可能对于用户来说是非常重要的功能。所以,如果可能,最好给用户一些补偿,比如把用户切换到一个送积分卡,或是红包抽奖的网页上,有限地补偿一下用户。
3.简化功能
关于功能的简化上,上面的下单流程中已经提到过相应的例子了。而且,从缓存中返回数据也是其中一个。这里再提一个,就是一般来说,一个 API 会有两个版本,一个版本返回全量数据,另一个版本只返回部分或最小的可用的数据。
举个例子,对于一篇文章,一个 API 会把商品详情页或文章的内容和所有的评论都返回到前端。那么在降级的情况下,我们就只返回商品信息和文章内容,而不返回用户评论了,因为用户评论会涉及更多的数据库操作。
所以,这样可以释放更多的数据资源。而商品信息或文章信息可以放在缓存中,这样又能释放出更多的资源给交易系统这样的需要更多数据库资源的业务使用。
3.降级设计的要点
对于降级,一般来说是要牺牲业务功能或是流程,以及一致性的。所以,我们需要对业务做非常仔细的梳理和分析。我们很难通过不侵入业务的方式来做到功能降级。
在设计降级的时候,需要清楚地定义好降级的关键条件,比如,吞吐量过大、响应时间过慢、失败次数多过,有网络或是服务故障,等等,然后做好相应的应急预案。这些预案最好是写成代码可以快速地自动化或半自动化执行的。
功能降级需要梳理业务的功能,哪些是 must-have 的功能,哪些是 nice-to-have 的功能;哪些是必须要死保的功能,哪些是可以牺牲的功能。而且需要在事前设计好可以简化的或是用来应急的业务流程。当系统出问题的时候,就需要走简化应急流程。
降级的读写设计
降级的时候,需要牺牲掉一致性,或是一些业务流程:对于读操作来说,使用缓存来解决,对于写操作来说,需要异步调用来解决。并且,我们需要以流水账的方式记录下来,这样方便对账,以免漏掉或是和正常的流程混淆。
降级开关
降级的功能的开关可以是一个系统的配置开关。做成配置时,你需要在要降级的时候推送相应的配置。另一种方式是,在对外服务的 API 上有所区分(方法签名或是开关参数),这样可以由上游调用者来驱动。
比如:一个网关在限流时,在协议头中加入了一个限流程度的参数,让后端服务能知道限流在发生中。当限流程度达到某个值时,或是限流时间超过某个值时,就自动开始降级,直到限流好转。
对于数据方面的降级,需要前端程序的配合。一般来说,前端的程序可以根据后端传来的数据来决定展示哪些界面模块。比如,当前端收不到商品评论时,就不展示。为了区分本来就没有数据,还是因为降级了没有数据的两种情况,在协议头中也应该加上降级的标签。
因为降级的功能平时不会总是会发生,属于应急的情况,所以,降级的这些业务流程和功能有可能长期不用而出现 bug 或问题,对此,需要在平时做一些演练。
降级的实现
一般是从整体负荷考虑,就是当某个服务熔断之后,服务器将不再被调用,此时客户端可以自己准备一个本地的fallback回调,返回一个缺省值,这样做,虽然服务水平下降,但好歹,比直接挂掉要强,最关键的不会影响到相关的其他服务。
服务降级处理是在客户端实现完成的,与服务端没有关系。
二、服务熔断组件选型
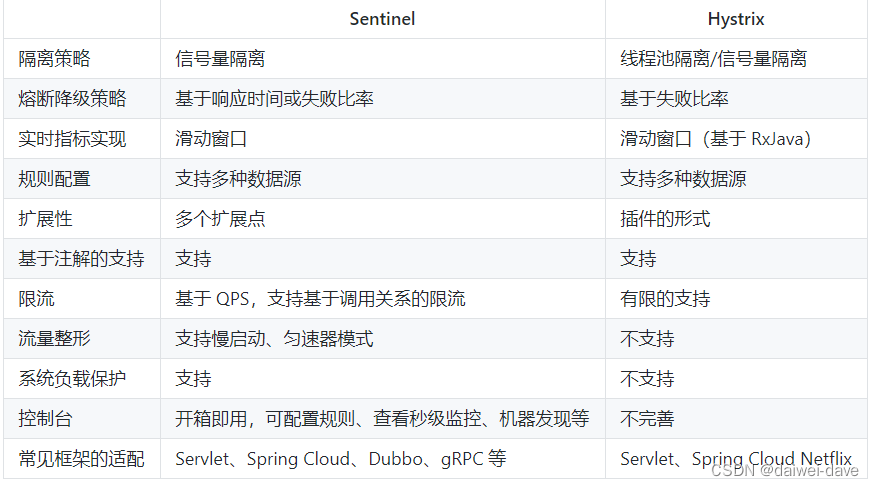
1.Sentinel和Hystrix对比
三、Spring Cloud Hystrix
1.基础概念
Spring Cloud Hystrix是基于Netflix的开源框架Hystrix实现,该框架实现了服务熔断、线程隔离等一系列服务保护功能。
它是一个分布式容错框架,故它有这些特点
- 阻止故障的连锁反应,实现熔断
- 快速失败,实现优雅降级
- 提供实时的监控和告警
2.Hystrix的内部处理流程
1.下图为Hystrix服务调用的内部逻辑:
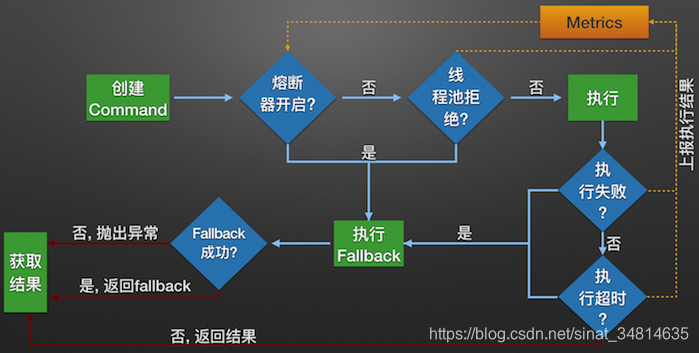
流程节点描述:
1.构建Hystrix的Command对象, 调用执行方法.
2.Hystrix检查当前服务的熔断器开关是否开启, 若开启, 则执行降级服务getFallback方
法.
3.若熔断器开关关闭, 则Hystrix检查当前服务的线程池是否能接收新的请求, 若线程池已
满, 则执行降级服务getFallback方法.
4.若线程池接受请求, 则Hystrix开始执行服务调用具体逻辑run方法.
5.若服务执行失败, 则执行降级服务getFallback方法, 并将执行结果上报Metrics更新服务
健康状况.
6.若服务执行超时, 则执行降级服务getFallback方法, 并将执行结果上报Metrics更新服务
健康状况.
7.若服务执行成功, 返回正常结果.
8.若服务降级方法getFallback执行成功, 则返回降级结果.
9.若服务降级方法getFallback执行失败, 则抛出异常.
2.下图是 Netflix 的开源项目Hystrix中的熔断的代码实现逻辑
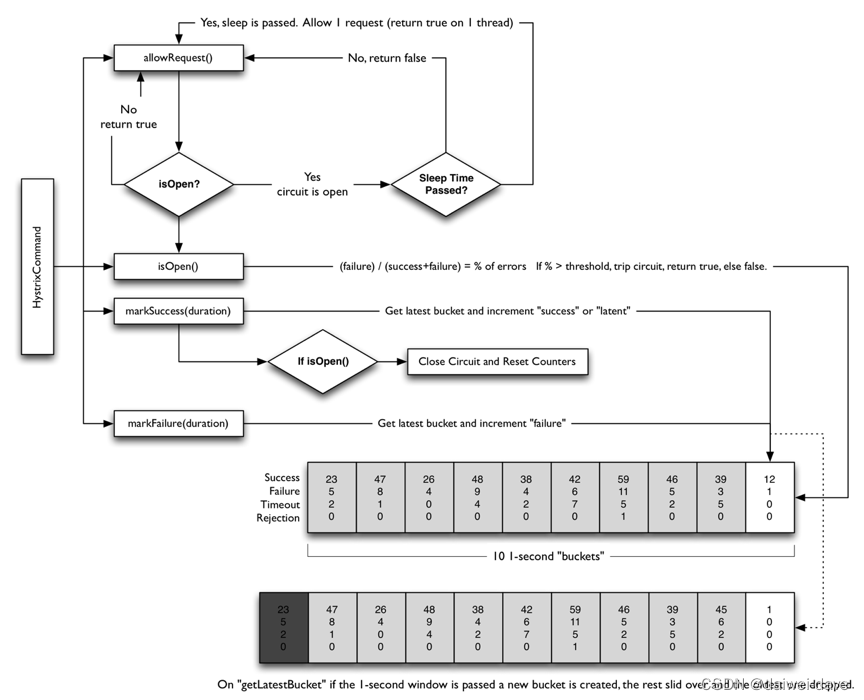
从这个流程图中,可以看到:
-
有请求来了,首先 allowRequest() 函数判断是否在熔断中,如果不是则放行,如果是的话,还要看有没有到达一个熔断时间片,如果熔断时间片到了,也放行,否则直接返回出错。
-
每次调用都有两个函数 markSuccess(duration) 和 markFailure(duration) 来统计一下在一定的 duration 内有多少调用是成功还是失败的。
-
判断是否熔断的条件 isOpen(),是计算一下 failure/(success+failure) 当前的错误率,如果高于一个阈值,那么打开熔断,否则关闭。
-
Hystrix 会在内存中维护一个数组,其中记录着每一个周期的请求结果的统计。超过时长长度的元素会被删除掉。
3.Hystrix Metrics
Hystrix的Metrics中保存了当前服务的健康状况, 包括服务调用总次数和服务调用失败次数等.
根据Metrics的计数, 熔断器从而能计算出当前服务的调用失败率, 用来和设定的阈值比较从而决定熔断器的状态切换逻辑. 因此Metrics的实现非常重要.
4.Hystrix 实战
@FeignClient(contextId = "remoteProPreService", value = ServiceNameConstants.POULTRY_SERVICE, fallbackFactory = RemoteProPreFallbackFactory.class)
public interface RemoteProPreService {
/**
*
* @param req
* @param source
*/
@PostMapping("/proPre/refreshProPre")
public R<Boolean> refreshProPre(@RequestBody(required = false) ProPreRefreshReq req, @RequestHeader(SecurityConstants.FROM_SOURCE) String source);
}指定fallback的实现,这样不仅能实现降级,并且能识别出错误异常原因。
@Component
public class RemoteProPreFallbackFactory implements FallbackFactory<RemoteProPreService> {
private static final Logger log = LoggerFactory.getLogger(RemoteProPreFallbackFactory.class);
@Override
public RemoteProPreService create(Throwable throwable) {
log.error("xxx调用失败:{}", throwable.getMessage());
return new RemoteProPreService() {
@Override
public R<Boolean> refreshProPre(ProPreRefreshReq req, String source) {
return R.fail("xxx失败:" + throwable.getMessage());
}
};
}
}但下面这种方式,无法识别出错误异常栈,不建议这样书写
public class WarnHandlerClientHystrix implements WarnHandlerClient {
@Override
public Result handleWarnMsg(HandleWarnMsgParam handleWarnMsgParam) {
log.info("调用env-server服务降级->方法:handleWarnMsg");
return Result.error(HttpCodeEnum.INTERNAL_SERVER_ERROR);
}
}参考资料
1.漫画:什么是服务熔断 https://blog.csdn.net/moakun/article/details/80222325

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









