







1:偏差&方差
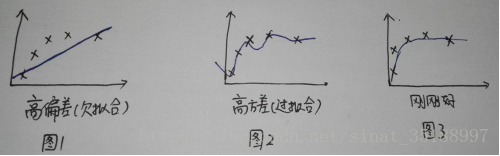
当模型做出与实际情况不符的假设时就会引起错误,这种错误称为偏差,通常是模型太简单。
方差是一种由于训练数据集的波动引起的错误。当学习算法随着训练数据集的不同而呈现出太大的波动时,所引起的错误就称为方差,通常是模型太复杂。
2:有监督&无监督
有监督学习:我们给算法一个数据集,并且给定“正确答案”,算法的目的就是给出更多的正确答案。也就是我们从输入和预期输出中学习得到一个模型,然后我们根据这个模型预测新的实例。比如:SVM,朴素贝叶斯等。
无监督学习:所有的数据都是一样的,没有属性/标签这一概念。可以简单理解为不为训练集提供对应的类别标签。比如聚类。
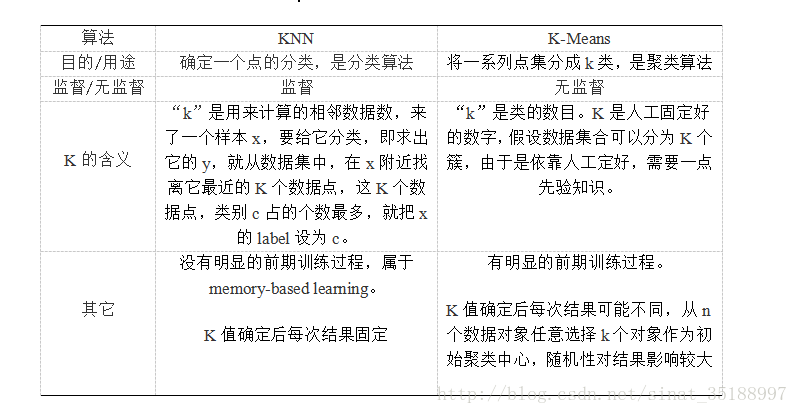
3:KNN & K-Means
KNN和K-Means都包含这样的过程,给定一个点,在数据集中找离它最近的点。即二者都用到了NN(Nears Neighbor)算法,一般用KD树来实现NN。
二者不同之处
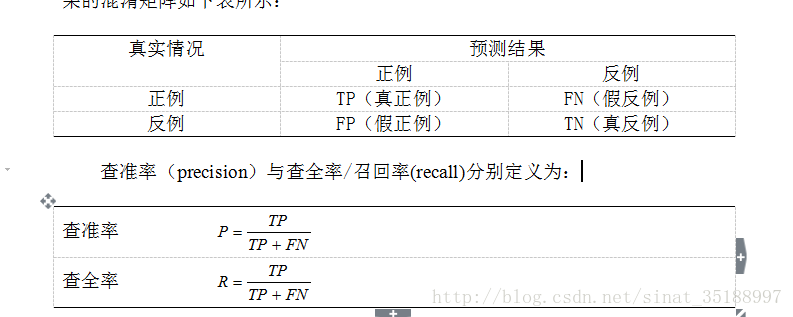
4:准确率&召回率
对于二分类问题,可将样例根据其真实类别与学习器预测类别的组合划分为真正例(TP,true positive),假正例(FP,false positive),真反例(TN,true negative),假反例(FN,false negative)四种情形。显然有TP+FP+TN+FN=样例总数。分类结果的混淆矩阵如下表所示:
5:贝叶斯 & 朴素贝叶斯
贝叶斯定理是关于随机事件A和B的条件概率:
贝叶斯定理可以表述为:后验概率=(相似度*先验概率)/标准化常量
贝叶斯统计作为一个基础算法,在机器学习中占据重要的一席之地。特别是在数据处理方面,针对事件发生的概率以及事件可信度分析上具有良好的分类效果。贝叶斯定理需要大规模的数据计算推理才能凸显效果,它在很多计算机应用领域中都大有作为,如自然语言处理,机器学习,推荐系统,图像识别,博弈论等。

朴素贝叶斯总结过了
6:L1 & L2正则化
正则化项即罚函数,该项对模型向量进行“惩罚”,从而避免单纯最小二乘问题的过拟合问题。奥卡姆剃刀法则
由上表可以看出,L1正则化比原始的更新规则多出了符号函数这一项。当w为正时,更新后的w变小。当w为负时,更新后的w变大,因此它的效果就是让w往0靠,使网络中的权重尽可能为0,也就相当于减小了网络复杂度,防止过拟合。因此,L1正则化更容易获得稀疏的权值,L2正则化更容易获得平滑的权值。

7:分类问题的评价标准
Accuracy , pression , recall, F1, ROC, PR,AOE
8:回归问题的评价标准
MAE , MSE
9:常用
F-Score: F=(αα+1)PR / αα(P+R)
是P和R的调和平均值
α=1时,就是F1值, F1=2PR / P+R
准确率 =(预测正确的样本)/(总样本)
召回率 = (正类预测为正类)/ (所有真正的正类) 目标预测的全不全














 1331
1331











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









