





论文:
https://arxiv.org/pdf/2112.04426.pdf
实现:
- GitHub - Langboat/mengzi-retrieval-lm: An experimental implementation of the retrieval-enhanced language model
- RETRO-pytorch/retro_pytorch at main · lucidrains/RETRO-pytorch · GitHub
本文基于预设 token 的局部相似性,通过调节从大型语料库中检索到的文档块来增强自回归语言模型,使用比 GPT-3 少 25 倍的参数量就能达到类似性能。增加模型大小能够改善大量下游任务的性能,增加参数量的益处来源于两个因素:训练和推理时的额外计算以及增强对训练数据的记忆。
贡献:
- 引入基于增强检索的自回归语言模型 RETRO,使用分块交叉注意力模块来合并检索到的文本,时间复杂度与检索到的数据量成线性关系。基于预训练的 frozen Bert 模型的检索很有效,无需训练和更新检索器网络
- 模型可以很好地适应模型大小和数据库大小
- 提出评估测试集与训练文档接近度的方法
方法
增强检索的结构能够从数十亿 token 的数据库中进行检索。为此,本文在连续的 token 块级别而不是单个 token 级别进行检索,这通过一个大的线性因子减少了存储和计算需求。
本方法首先构建 k-v 数据库,其中,值存储原始文本 token 块,键是 frozen BERT embeddings。使用一个 frozen model 来避免在训练期间必须定期重新计算整个数据库的 embeddings。
然后把训练序列分块,用从数据库中检索到的 k 个近邻进行增强。编码器-解码器架构将检索块集成到模型的预测中。
训练集
增强检索的自回归 token 模型
本方法使用检索在小 token 块粒度上增强输入样例。考虑使用文本 tokenizer 获得的 𝕍 = [1, 𝑣] 中的整数 token 序列。将 n 个 token 长度的 样例 ![]() 分成大小为 m = n/l 的 l 块序列
分成大小为 m = n/l 的 l 块序列 ![]() 。本文中 n=2048,m=64。用来自数据库
。本文中 n=2048,m=64。用来自数据库 ![]() 的 𝑘 邻居的集合 Ret D (𝐶𝑢) 扩充每个块𝐶𝑢。 token 的似然由模型提供,由 𝜃 参数化,该模型将先前的 token 及其检索到的邻居作为输入。检索增强序列的对数似然:
的 𝑘 邻居的集合 Ret D (𝐶𝑢) 扩充每个块𝐶𝑢。 token 的似然由模型提供,由 𝜃 参数化,该模型将先前的 token 及其检索到的邻居作为输入。检索增强序列的对数似然:

Ret(𝐶1) = ∅,即来自第一个块的 token 的 likelihood 不依赖于任何检索数据。这个 似然 的定义保留了自回归性:第 u 个块的第 i 个 token 的概率,![]() 只取决于先前看到的 token
只取决于先前看到的 token ![]() ,以及从之前的块中检索到的数据
,以及从之前的块中检索到的数据 ![]() 。因此可以直接用对数概率
。因此可以直接用对数概率 ![]() 进行采样,其中块
进行采样,其中块 ![]() 内的采样以邻居
内的采样以邻居 ![]() 为条件。这使得检索增强模型可以与通过抽样评估的大型语言模型相媲美。
为条件。这使得检索增强模型可以与通过抽样评估的大型语言模型相媲美。
近邻检索
数据库由 k-v 对组成,每个值由两个连续的 token 块组成,用 [N,F] 表示,N 是用于计算 key 的相邻块,F 是在原始文本中的延续。相应的 key 是 N 的 BERT embedding,随时间做平均,表示为 BERT(N)。对于每个块 C,使用 BERT embedding 的 L2 距离从数据库中检索 k 近邻,![]()
模型会接收相应的值
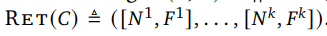
,![]() 和
和![]() 的长度都是 64,因此 RET(C) 维度为 kxr,其中 r=128
的长度都是 64,因此 RET(C) 维度为 kxr,其中 r=128
检索模型结构
模型依赖于编-解码器的 transformer 结构,通过交叉注意力机制整合检索到的数据。首先,RET(C) 被输入 Transformer 编码器,计算 Encoded neighbours E,用 H 表示中间的激活。Transformer 解码器由 RETRO-blocks 和 标准 Transformer blocks 交织组成。
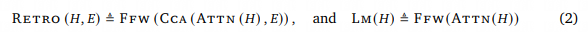
Encoding retrieval neighbours
对于每个块![]() ,其 k 检索邻居 RET() 输入 双向 transformer 编码器,
,其 k 检索邻居 RET() 输入 双向 transformer 编码器,![]() 为邻居的索引。retrieval 编码器是 non-causal transformer。它以
为邻居的索引。retrieval 编码器是 non-causal transformer。它以![]() 块通过交叉注意力层后的激活
块通过交叉注意力层后的激活![]() 为条件,。这允许检索编码器的表示以可微分的方式被检索块调整。更准确的说,第 u 个块的第 j 个邻居的编码
为条件,。这允许检索编码器的表示以可微分的方式被检索块调整。更准确的说,第 u 个块的第 j 个邻居的编码![]() 取决于在 min(P) 层的 attended activation
取决于在 min(P) 层的 attended activation ![]() ,所有块的邻居都被并行编码,产生完整的编码集合
,所有块的邻居都被并行编码,产生完整的编码集合 ![]() 。用
。用![]() 表示 chunk
表示 chunk ![]() 的编码邻居。
的编码邻居。
Chunked cross-attention
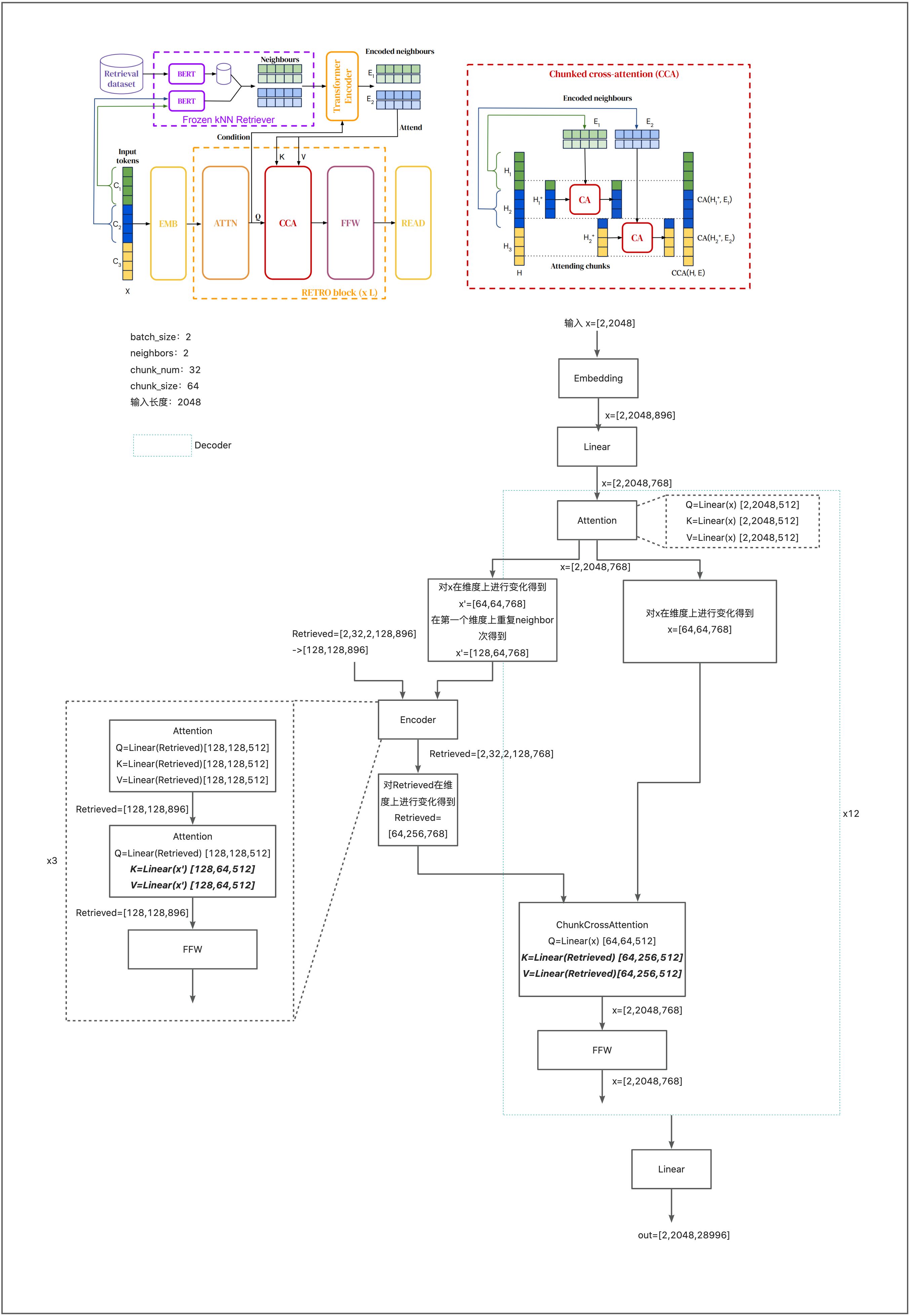
算法运行流程


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









