






 文章讨论了在LLM中上下文长度受限的问题,提出FOT方法解决分心问题,通过对比学习改进键值结构。FOT易实现且不改变模型架构,但在大内存需求和分布式训练方面有局限。
文章讨论了在LLM中上下文长度受限的问题,提出FOT方法解决分心问题,通过对比学习改进键值结构。FOT易实现且不改变模型架构,但在大内存需求和分布式训练方面有局限。
Abstract
LLM 能够以上下文的方式整合新信息,但由于有效上下文长度限制,这种能力会受到限制。解决这个问题的一种方案是赋予注意力层访问外部存储器的能力,该存储器由键值对组成。然而,随着文档数增加,不相关键增加,导致模型更多地关注不相关键。
分心问题(the distraction issue)指的是链接到不同语义值的键可能重叠,使得它们难以区分。Focused Transformer(FOT)采用受对比学习启发的训练过程来解决这个问题。这种方法增强了键值空间结构,允许扩展上下文长度。
Contribution
1. 指出分心问题是在 Transformer 模型中扩展上下文长度的重大挑战和主要障碍,特别是在多文档场景中。
2. 提出了 FOT,旨在缓解分心问题。FOT包括一个独特的训练目标,它改进了(键、值)结构,允许使用广泛的外部内存和k近邻查找来扩展上下文长度
3. 方法易于实现,并且提供了在不修改现有模型的架构的情况下用内存增强现有模型的好处。在 openLLaMA 3B 和 7B 上进行了验证
Limitations
1. 需要扩大内存。存储超过16M(键,值)对将需要一个分布式多节点系统。
2. 训练需要 batch
Method
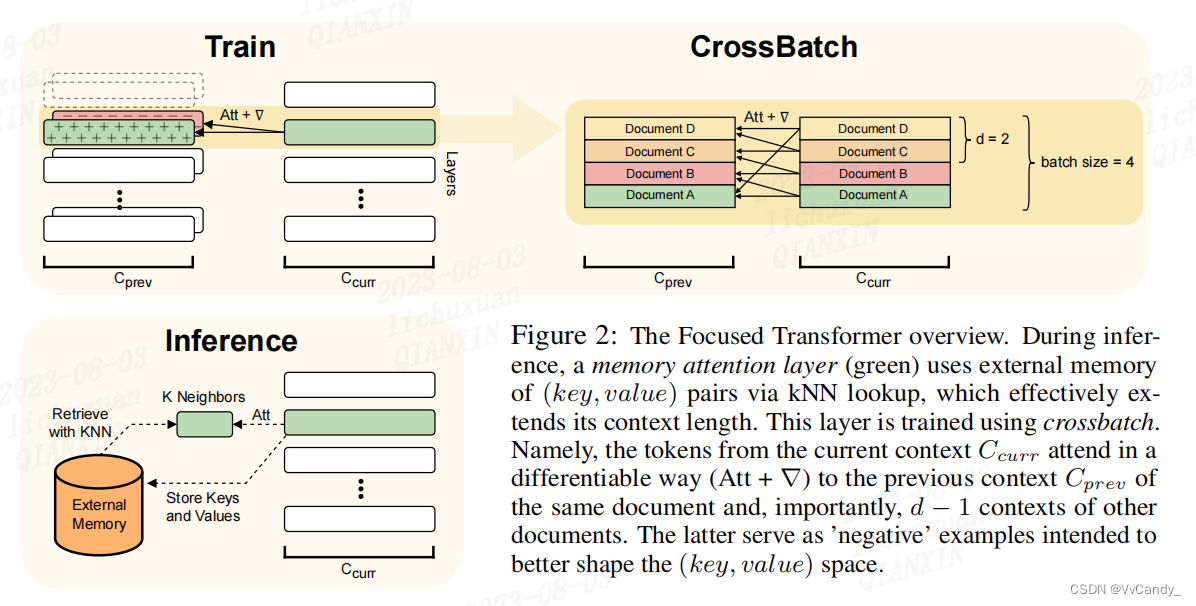
Memory attention layers
Memory attention 层 L 在推理期间可以访问外存数据库。L 中的每一层 l 关注局部上下文前面的 key 以及内存中最匹配的 k 个key。内存中的 key 与 query 做内积后排序,使用 kNN 算法检索。内存中会逐渐填充由 l 预先处理的键值对
CrossBatch training procedure
关键思想是:将 l 暴露给来自给定文本的当前和先前的局部上下文的键值对(正),以及来自不相关文本的 d-1 上下文(负),这些用可微分的方式完成。
为了实现这点,本文使用数据管道,每个batch中的元素对应于不同的文本,为每个已经处理过的文本嵌入先前的(cprev)和当前的(ccur)局部上下文
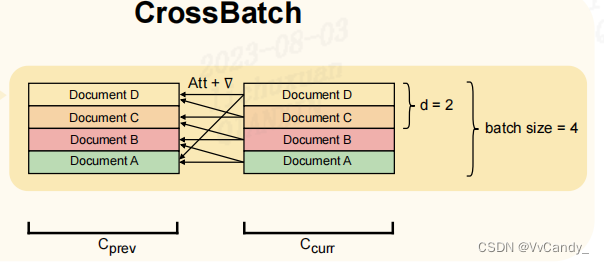
对于 ccur 中的每个文本(Document),创建大小为 d 的由键值对组成的集合,集合元素来自于之前的 positive 局部上下文


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









