







一、Pod镜像拉取策略
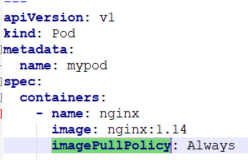
这里的imagePullPolicy就代表了镜像的拉取策略:
1.Always:每次创建pod都会重新拉取一次镜像;
2.IfNotPresent:默认值,镜像不在宿主机上时才进行拉取;
3.Never:Pod永远不会主动拉取这个镜像。
二、Pod资源限制
request:
调度时用于计算所有pod请求的资源,不能超过node提供的总资源,request代表容器的最小资源:
spec.containers[].resources.requests.cpu
spec.containers[].resources.requests.memory
requests.cpu最终转化为docker的参数–cpu-shares,requests.memory在docker中无与之相对应的参数
limit:
限制容器占用的最大资源,如果超过就会终止容器:
spec.containers[].resources.limits.cpu
spec.containers[].resources.limits.memory
limits.cpu最终转化为docker的参数–cpu-quota,limits.memory会被转换成docker的参数–memory
转化为yaml语言如下:

三、Pod重启策略
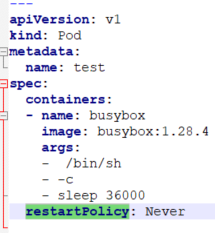
Always: 当容器终止并退出后,总是重启容器,默认策略;应用在一直提供服务的容器。
OnFailure: 当容器异常退出(退出状态码非0)时,才重启容器;
Never: 当容器终止退出,从不重启容器;应用在处理批量任务时。
四、Pod健康检查
有些时候容器running,但是已经有异常了,比如java的内存溢出,就不能单单将容器的running作为健康状态的依据。
1.livenessProbe(存活检查)
如果检查失败,将杀死容器,根据Pod的restartPolicy来进行重启操作。
2.readlinessProbe(就绪检查)
如果检测失败,K8s会把Pod从service endpoints中删除,使用其他容器提供服务。

3.Probe(探针)支持的检测方法如下3种:
http Get
发送HTTP请求,返回200-400之间的状态码,表示成功
exec
执行shell命令返回状态码为0,表示成功
tcpSocket
发起TCP Socket建立,表示成功
五、Pod的创建流程(调度策略)
第1步:
创建Pod的命令发送给API Server,API Server收到请求后,将创建信息的属性信息(metadata)写入etcd,并返回结果

第2步:
(1)API Server通过触发watch机制准备创建pod,把创建信息转发给Scheduler;
(2)Scheduler使用调度算法选择合适的node,并将node信息返回给API Server;
(3)API Server将绑定的node信息写入etcd
(4)返回写入状态

第3步:
API Server再次通过watch机制,调用kubelet,指定pod信息,触发docker run命令创建容器,
创建完成之后反馈给kubelet, kubelet又将pod的状态信息返回给API Server,API Server又将pod的状态信息写入etcd。

kubectl get pods得到的结果就是从etcd中返回的信息。
影响Pod调度的属性
1.Pod资源限制:
request(参考第二点)
2.节点选择器标签(nodeSelector/nodeName)
spec:
nodeSelector:
env_role: dev #将Pod调度到不同的环境中去
开始之前,需要先给同一环境中的节点打上同一个标签:
设置标签:kubectl label node node1 env_role=env
查看标签:kubectl get node node1 --show-labels
查看所有节点的标签:kubectl get node --show-labels
删除标签:kubectl label node node1 env_role-
这个env_role叫做label-key,还可以自定义其他参数作为label-key,用法类似。
除在yaml中通过设置nodeSelector属性指定节点以外,用户也可以在命令行中通过参数-l或者–labels=指定节点的标签:
kubectl run nginx-deployment --image=nginx:1.7.9 --replicas=3 --labels=‘mem=large’
另外一个选择器nodeName:通过指定节点名来确定将Pod部署到哪个node上。
spec:
nodeName: 192.168.1.145
3.节点的亲和性

节点亲和性nodeAffinity和nodeSelector,根据节点上的标签约束来决定Pod被调度到哪些节点上。
硬亲和性:表示必须满足约束条件,否则会一直等待;
软亲和性:表示可以尝试满足这些约束条件,没有符合约束的节点,就去找其他节点调度,不会一直等待;
常用的操作符(operator):
In :values列出的值中
NotIn :不在里面
Exists:存在
Gt:大于
Lt:小于
DoesNotExists:不存在
六、污点(Taint)和污点容忍(Toterot)
nodeSelector和nodeAffinity:属于Pod属性,将Pod调度到某些节点上;
Taint:属于节点属性,节点不做普通的分配调度。
污点的使用场景:
1.指定专用节点去分配Pod
2.根据特定的硬件属性分配到指定节点
3.基于Taint做Pod的驱逐
查看节点的污点情况:

这里污点的值有三个:
NoSchedule:表示一定不会被调度
PreferNoSche:尽量不被调度,也有被调度的可能性
NoExecute:不但不会被调度,还会把已经调度到该节点的Pod给驱逐到其他节点去
为节点添加污点的命令:
kubectl taint node worker-145 key=value:污点值
测试:
kubectl create deployment web --image=nginx #创建一个Pod

kubectl scale deployment web --replicas=5 #扩容到5个副本


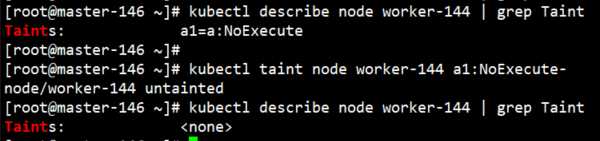
kubectl taint node worker-144 a1=a:NoExecute #设置污点

可以发现,原来144上的Pod全部被驱逐到145上去了。
污点的删除(和label的删除有点类似):
kubectl taint node worker-144 a1:NoExecute-
污点容忍:
即使节点被设置为NoSchedule(一定不会被调度),但是设置了污点容忍,就有被调度的可能。
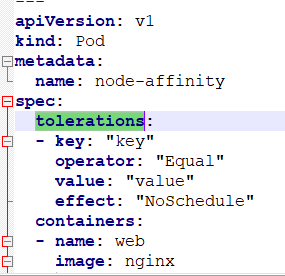
这里面的key和value是添加污点时设置的参数。
















 1904
1904











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











