







#从dataframe中将两列符合条件的行取出来
def info_duplicates(base_info):
base_info['miss'] = base_info.isnull().sum(axis = 1)
tmp_miss_df = base_info['miss'].groupby(base_info['patient_id']).min()
zip_list = list(zip(tmp_miss_df.index,list(tmp_miss_df)))
base_info.index = pd.MultiIndex.from_arrays([list(base_info['patient_id']),list(base_info['miss'])])
base_info['flag'] = base_info.index.isin(zip_list)
base_info = base_info.reset_index()
del base_info['level_0']
del base_info['level_1']
base_info = base_info[base_info['flag'] == True]
base_info = base_info.drop_duplicates(subset = ['patient_id'],keep = 'last')
del base_info['miss']
del base_info['flag']
gc.collect()
return base_info生成连续时间
date_range = pd.date_range('20150101','20191231',freq = '1D')
date_range_list = [x.strftime('%Y-%m-%d') for x in date_range]随机抽取80%数据集作为训练集,剩下的作为测试集
train_dataset = dataset.sample(frac = 0.8,random_state = 0)
test_data_set = dataset.drop(train_dataset.index)对dataframe中的字段中含有符号的记录进行分裂形成多列

实现如下数据转化目标

import pandas as pd
df = pd.DataFrame({'商户':['a','a','b','b','c','c'],'时段':[2,4,5,6,1,5],'笔数':[3,4,22,9,33,11],'金额':[123,456,789,222,111,44]})
df.set_index(['商户','时段'],inplace = True)#转化为双索引
tmp_df = df.unstack()
tmp_df.fillna(0,inplace = True)
tmp_df.columns = ['时段_'+str(x[1])+'_'+x[0] for x in tmp_df.columns]运用re对字符串中的中文进行连续提取
regStr = ".*?([\u4E00-\u9FA5]+).*?"
mend_res = re.findall(regStr, x)
运用loc快速将符合条件的数据提取出来
def combine(data,var_list):
cond_1 = (data[var_list[1]].isna() == True)&(data[var_list[2]].isna() == False)
data.loc[cond_1,var_list[1]] = data.loc[cond_1,var_list[2]].values
cond_2 = (data[var_list[0]].isna() == True)&(data[var_list[1]].isna() == False)
data.loc[cond_2,var_list[0]] = data.loc[cond_2,var_list[1]].values
return data
#var_list = ['RBC.1', 'RBC.2', 'RBC.3']运用map()对列值进行匹配替换
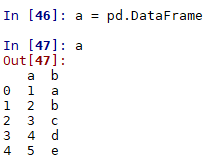
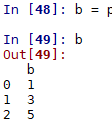
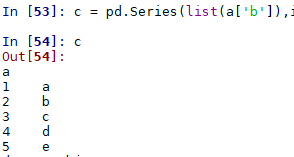

应用tfidf实现文本相似度计算,实现模糊匹配
class Text_similarity(object):
def __init__(self):
self.all_doc = []
with open('AID_标准名.txt','r') as f:
for line in f.readlines():
doc = line.split('\t')[1].strip()
self.all_doc.append(doc)
self.all_doc_list = []
for doc in self.all_doc:
doc_list = [word for word in jieba.cut(doc)]
self.all_doc_list.append(doc_list)
self.model()
def model(self):
self.dictionary = corpora.Dictionary(self.all_doc_list)
corpus = [self.dictionary.doc2bow(doc) for doc in self.all_doc_list]
self.tfidf = models.TfidfModel(corpus)
self.index = similarities.SparseMatrixSimilarity(self.tfidf[corpus], num_features=len(self.dictionary.keys()))
def jieba_cut_test(self,doc_test):
doc_test_list = [word for word in jieba.cut(doc_test)]
doc_test_vec = self.dictionary.doc2bow(doc_test_list)
sim = self.index[self.tfidf[doc_test_vec]]
tmp_result = sorted(enumerate(sim), key=lambda item: -item[1])
result = self.all_doc[tmp_result[0][0]]
val = tmp_result[0][1]
return result,valpython实现多线程
results = Parallel(n_jobs=-1, backend='multiprocessing',verbose = 1)(delayed(main)(file) for file in tqdm(visit_list))main是函数名,file是函数参数,可以传入多个,visit_list是数据文件集合列表
python将dataframe导入到sqlserver
import pandas as pd
from sqlalchemy import create_engine
import gc
from tqdm import tqdm
'''
将该py文件与数据集放置同一路径下,将参数file_name改为sas的数据表名称即可
'''
def sas_to_sql(file_name = 'tx_ki',batch_size = 100000):
data_tmp = pd.read_sas(file_name+'.sas7bdat',chunksize = batch_size)
for df in tqdm(data_tmp):
engine = create_engine('mssql+pymssql://user_name:key@ip/database')
df.to_sql(file_name, engine, if_exists='append', index=False)
del df
gc.collect()
if __name__ == '__main__':
sas_to_sql(file_name = 'tx_ki',batch_size = 100)#file_name为表名,batch_size为分批读取数据的数据量,可防止一下读取过多数据内存爆掉得到excel表中所有sheet的名称
file_document = pd.ExcelFile('file.xlsx')
sheet_name = file_document.sheet_names #得到sheet的名称list
for sheet in sheet_name:
df = file_document.parse(sheet)#得到对应sheet的数据表关于时间的处理
Timestamp格式转化为字符:tt.strftime("%Y-%m-%d)
![]()
![]()
得到前一天的日期:tt+datetime.timedelta(days=-1)
![]()















 2446
2446











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









