









参考了Crossin的编程教室http://res.crossincode.com/wechat/python.html正则表达式的章节和Python官方文档中re模块https://docs.python.org/3/library/re.html
的说明。
对正则表达式有了简单的了解。
1.1 r
不对字符串进行转译。
>>> import re
>>> text = "Hi,I am Shirley Hilton. I am his wife."
>>> m = re.findall(r"hi",text)
>>> print(m)
['hi', 'hi'] 1.2 \b 和 \B
\b
Matches the empty string, but only at the beginning or end of a word.
匹配单词和空格的边界。
\B
Matches the empty string, but only when it is not at the beginning or end of a word.
>>> import re
>>> text = "Hi,I am Shirley Hilton. I am his wife."
>>> m = re.findall(r"\bhi\b",text)
>>> print(m)
[]
>>> m = re.findall(r"\Bhi\B",text)
>>> m
['hi']
>>> 1.3 []
匹配[]中的任意内容。[Hh]可以忽略大小写。
>>> import re
>>> text = "Hi,I am Shirley Hilton. I am his wife."
>>> m = re.findall(r"\b[Hh]i\b",text)
>>> print(m)
['Hi']
>>> m = re.findall(r"[Hh]i",text)
>>> print(m)
['Hi', 'hi', 'Hi', 'hi']1.4 .
(Dot.) In the default mode, this matches any character except a newline. If the DOTALL flag has been specified, this matches any character including a newline.
>>> import re
>>> text = "Hi,I am Shirley Hilton. I am his wife."
>>> m = re.findall(r".",text)
>>> print(m)
['H', 'i', ',', 'I', ' ', 'a', 'm', ' ', 'S', 'h', 'i', 'r', 'l', 'e', 'y', ' ', 'H', 'i', 'l', 't', 'o', 'n', '.', ' ', 'I', ' ', 'a', 'm', ' ', 'h', 'i', 's', ' ', 'w', 'i', 'f', 'e', '.']
>>> m = re.findall(r"i.",text)
>>> m
['i,', 'ir', 'il', 'is', 'if']1.5 \S
Matches any character which is not a Unicode whitespace character. This is the opposite of \s.
>>> import re
>>> text = "Hi,I am Shirley Hilton. I am his wife."
>>> m = re.findall(r"\S",text)
>>> m
['H', 'i', ',', 'I', 'a', 'm', 'S', 'h', 'i', 'r', 'l', 'e', 'y', 'H', 'i', 'l', 't', 'o', 'n', '.', 'I', 'a', 'm', 'h', 'i', 's', 'w', 'i', 'f', 'e', '.']1.6 \s
和\S相对,匹配空格键
>>> import re
>>> text = "Hi,I am Shirley Hilton. I am his wife."
>>> m = re.findall(r"\s",text)
>>> m
[' ', ' ', ' ', ' ', ' ', ' ', ' ']1.7 *
Causes the resulting RE to match 0 or more repetitions of the preceding RE, as many repetitions as are possible.
贪婪匹配。
>>> import re
>>> text = "Hi,I am Shirley Hilton. I am his wife."
>>> m = re.findall(r"I.*e",text)
>>> m
['I am Shirley Hilton. I am his wife']
>>>
>>>#“*”表示任意数量连续字符,这种被称为通配符。但在正则表达式中,任意字符是用“.”表示,而“*”则不是表示字符,而是表示数量:它表示前面的字符可以重复任意多次(包括0 次),只要满足这样的条件,都会被表达式匹配上。
>>> 1.8 *?
懒惰匹配
>>> import re
>>> text = "Hi,I am Shirley Hilton. I am his wife."
>>> m = re.findall(r"I.*?e",text)
>>> m
['I am Shirle', 'I am his wife']
>>> 1.9 小练习
匹配出所有s开头,e结尾的单词。
>>> text1 = 'site sea sue sweet see case sse ssee loses'
>>> mm = re.findall(r"\bs\S*?e\b",text1)
>>> mm
['site', 'sue', 'see', 'sse', 'ssee']
>>> r,raw,不进行转译
\b 匹配单词和空格的边界,\bs匹配空格和s的边界,e\b匹配e和空格的边界
\S 不匹配空格键,保证是独立的单词。保证不会出现’sea sue’这样的匹配结果。
*?懒惰匹配
上面的\b,\S,* 在正则表达式中叫做元字符。还有更多的元字符和功能的介绍。
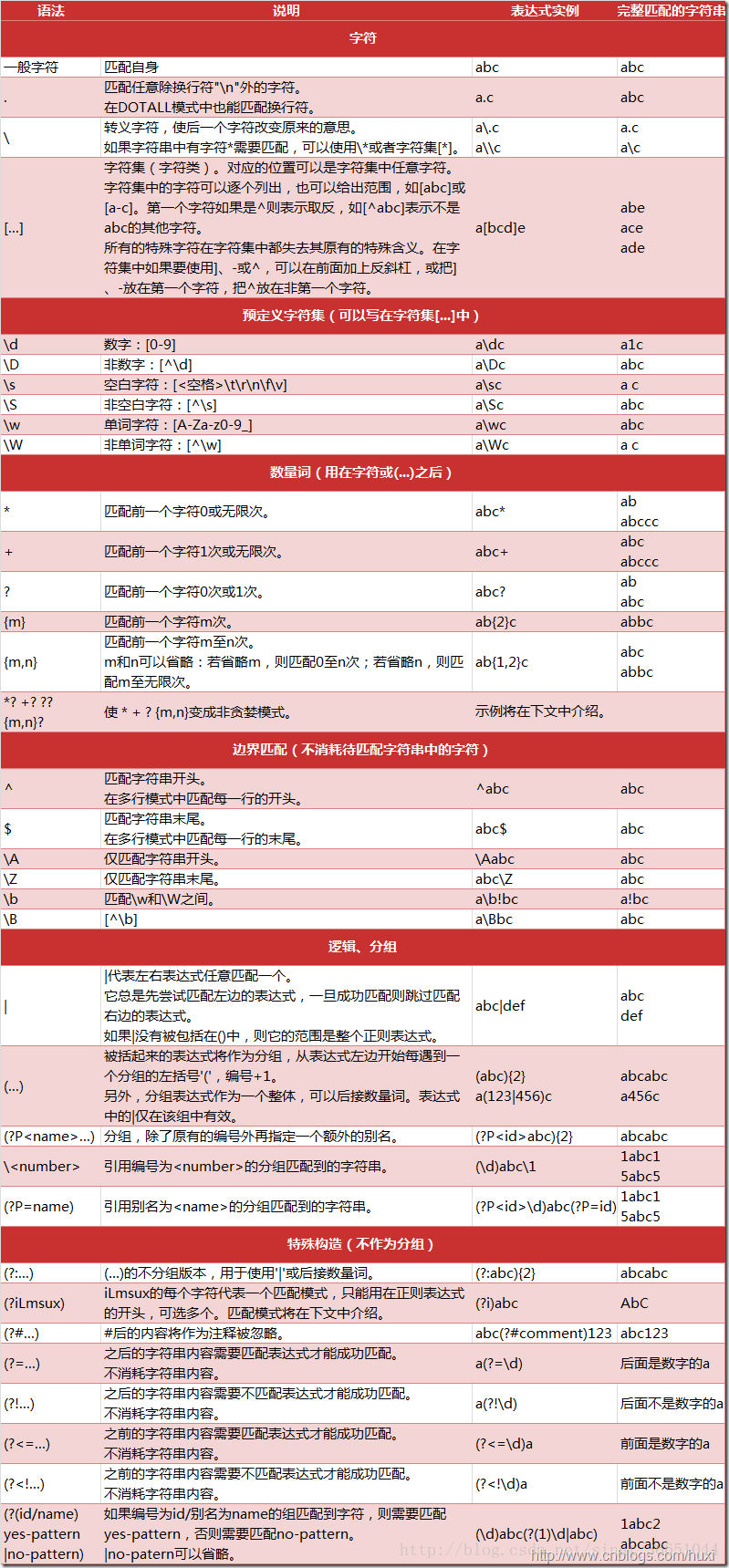
图片来自AstralWind作者的文章,Python正则表达式指南http://www.cnblogs.com/huxi/archive/2010/07/04/1771073.html














 5860
5860











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









