






LGnet——具有缺失值的多变量时间序列预测的局部和全局时间动力学联合建模
Joint Modeling of Local and Global Temporal Dynamics for Multivariate Time Series Forecasting with Missing Values
作者: Xianfeng Tang, Suhang Wang
备注:Accepted by AAAI 2020
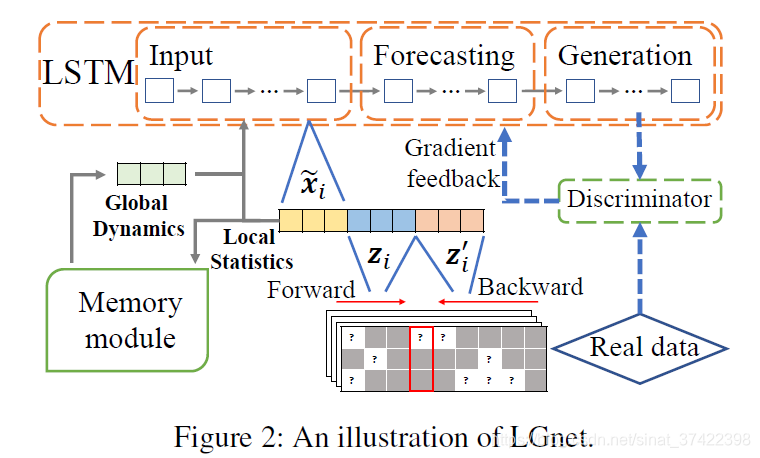
1、MTS forecasting with LSTM
整体预测模型使用LSTM,但是由于数据中有缺失数据,所以在Memory Module进行数据补全。
2、Memory Module
主要思想是存储一个参数矩阵(parameterized memory),用于获取全局特征。对于MTS中每一个变量,首先捕获局部特征(local statistics);然后利用local statistics作为key在memory component中进行查询,获得具有全局信息的表示向量。
两个优点:
1)从全局的角度学习和存储有用的时间模式;
2)利用 时序模式(temporal patterns)知识构建全局表示。我理解就是利用一个时序的数据串,经过特征空间变换,得到另一个表示向量,这个表示向量中含有全局信息。
2.1 Capturing Local Statistics
借用论文[1]衰减率的方法,利用经验平均值(Empirical Mean)和上一个未确实数据(Last Observation)对缺失数据进行填充。
(1)Empirical Mean
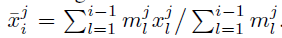
(2)Last Observation
引入
x
i
−
1
j
x^j_{i-1}
xi−1j 与上一未缺失数据的时间距离(temporal distance):
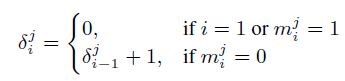
引入 衰减率(decaying mechanism)来平衡Empirical Mean与Last Observation的权重。
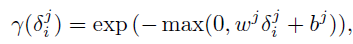
最后数据的补全计算方式为:
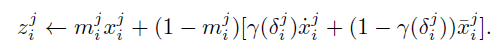
与论文[1]不同,该文章使用双向的补全方式,即,用
z
i
z_i
zi表示通过时刻1到
n
−
i
+
1
n-i+1
n−i+1提取的local statistics,用
z
i
′
z_i'
zi′表示通过时刻
i
+
1
i+1
i+1到
n
n
n提取的local statistics。
(3)LSTM提供的 local statistics
LSTM可以自然地对缺失数据进行估计,我们使用LSTM在
i
−
1
i-1
i−1时间的输出作为另一个local statistics:
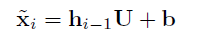
2.2 Modeling Global Dynamics
根据论文[1]的想法,可以直接把三个local statistics输入给LSTM。但是随着缺失率提高, z i z_i zi、 z i ′ z_i' zi′的可信度也随之降低;并且local statistics只包含了局部信息,没有包含全局信息。
本文利用了memory network 来存储全局信息。我们设计了一个memory module来存储全局信息。
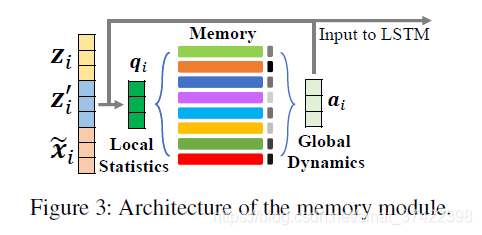
我们假设在数据(dataset)中存在
L
L
L个时间模式(temporal patterns),
L
L
L是一个超参数;初始化参数(parameterized memory):
G
∈
R
L
×
d
G
\mathcal{G}\in R^{L \times d^\mathcal{G}}
G∈RL×dG。其中,
d
G
d^\mathcal{G}
dG是模式表示(pattern representation)的维度。memory
G
\mathcal{G}
G 随着LSTM的迭代更新。
用local statistics作为key去查询memory module,查询方式为:
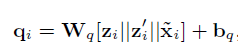
其中 || 表示 列(column)维度上的拼接。
W
q
W_q
Wq 和
B
q
B_q
Bq为参数。接下来我们计算
q
i
q_i
qi和memory component
G
\mathcal{G}
G 之间的相似度:
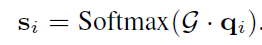
相似度的值衡量了memory中每个temporal patterns的重要性——称之为attention score。如果attention score比较高,说明这个temporal patterns与缺失值的上下文更加匹配。
最后我们通过各个temporal patterns的加权和来构造
x
i
x_i
xi的 提供了全局信息的 表示向量(representation vector):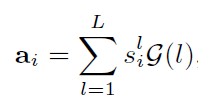
其中
G
(
l
)
\mathcal{G}(l)
G(l)表示
G
\mathcal{G}
G的第
l
l
l行。
2.3 LSTM
用local statistic features 和 global representations作为时间步
i
i
iLSTM的输入。
需要注意并不是所有的local statistics都可以被构建出来,比如说第一个时间的数据就确实了,这种情况我们直接用0进行补全。
通过LSTM的n次迭代我们可以得到预测结果: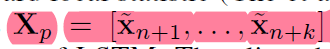
即我们利用前n个时间步的数据预测n~n+k时间步的数据,真实数据用
X
p
^
\hat{X_p}
Xp^表示,
X
p
^
\hat{X_p}
Xp^中也包含缺失数据。因此,我们在均方误差的计算中加上掩码矩阵(mask matrix),只计算未缺失数据的均方误差,LGnet的训练方式如下:
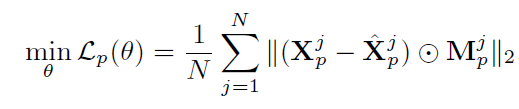
其中
θ
\theta
θ是LGnet的参数,包括LSTM和memory component的参数;
M
p
j
M_p^j
Mpj是第
j
j
j个MTS数据样例
X
j
X^j
Xj对预测数据的掩码矩阵,个人理解作用是缺失数据部分的掩码矩阵值为0,这样可以只计算未缺失数据的均方误差;
⨀
\bigodot
⨀是dot-production。
3、Adversarial Training
如上所述,LGnet的训练 只利用了 未缺失数据,但是如果缺失率比较高的话就不太好。如果如果我们能训练LGnet产生更多伪真实数据,可以提高MTS预测的整体精度。为了实现这一目标,我们引入对抗性训练(adversarial training)来控制生成的MTS的分布,即GAN。
典型的GAN由一个生成器和一个鉴频器组成。鉴别器的目标是区分生成器生成的伪数据和真实输入数据。通过对数据分布进行min-max game建模,生成器可以生成更真实的样本。
我们设计一个鉴别器 discriminator D D D,LSTM生成的预测数据作为伪数据输入给鉴别器 D D D,鉴别器的训练目标是区分伪数据和真实输入数据。通过迭代训练,LSTM更能生成更像真实数据的预测数据,使得预测结果更加准确。
本文采用的GAN模型是W-GAN,构造了双层神经网络作为鉴别器 D D D。输入一个MTS s s s, D D D输出真实值 D ( s ) D(s) D(s),值的大小表示 s s s的真实程度,越大越真实。
在forecasting part之后,生成一个长度为
k
′
k'
k′的“fake” 多变量时序数据: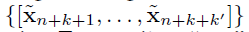
在真实数据中采样相同长度的数据,用
S
S
S表示时序片段的采样子集。当
k
′
k'
k′很小(
k
′
<
=
5
k'<=5
k′<=5)的时候很容易拟合。训练目标如下:
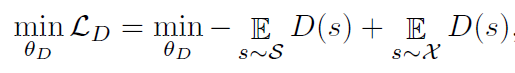
其中~表示sampling from;
θ
D
\theta _D
θD表示鉴别器的参数。一般情况下,越像真实数据的伪数据,得分越高。
对应的,将LSTM的目标函数定义为:
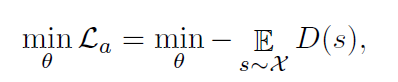
它的目标是欺骗鉴别器。需要注意在预测部分和生成部分没有重叠,因为我们发现在预测部分增加对抗性损失可能会损害性能。一个潜在的原因是欺骗鉴别器的最佳时间序列可能不是最准确的预测结果。所以这里我们将损失
L
a
L_a
La放在生成序列上,以达到最佳性能。
我的理解是,预测部分损失函数为:
生成部分损失函数为:
LSTM在迭代的过程中同时生成预测数据 和 伪数据,使这两个损失同时逐步下降。
2.4 Objective Function and Training
我们定义总体目标函数来学习模型参数
θ
\theta
θ:
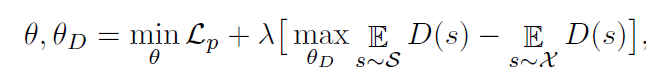
其中,
λ
\lambda
λ平衡 MTS forecasting part 和 adversarial training part。
使用 随机梯度下降 来更新模型参数,鉴别器和LSTM***交替训练***,直到模型收敛。首先更新 θ D \theta _D θD,然后固定 θ D \theta _D θD 优化LSTM的参数 θ \theta θ 和 memory module。
3、实验部分
在本节中,我们将通过实验来评估所提出的LGnet框架。具体而言,我们旨在回答以下研究问题:
(i) RQ1: LGnet能否提高 带缺失值MTS预测 的准确性?
(ii) RQ2:LGnet w.r.t 在不同缺失率下的健壮性?
(iii) RQ3: memory module对LGnet有何好处?
(iv) RQ4: 对抗性训练对LGnet有何贡献?
接下来,我们通过介绍MTS预测的各种实验来回答上述问题。
3.1 数据集
4个大型数据集:
(1)Beijing Air
该数据集是由2018年KDD Cup引入的。提取北京35个监测站的PM2.5值,构建多元时间序列。这些数值在2014年5月1日至2015年4月30日每小时报告一次。
在时间维度上缺失率为13%。我们使用过去9小时的观测数据来训练每个模型,并预测接下来3小时的PM2.5值。
(2)PhysioNet
PhysioNet (Silva et al. 2012)提供了重症监护病房(ICU)的4000个多变量临床时间序列。每个时间序列记录了患者入院48小时内的35项测量数据,如血糖和心率。我们摘取12个重要的测量数据,如心率和温度。在时间维度上,丢失的PhysioNet比率约为78%。我们以过去6小时的观测结果来预测未来3小时的数值。
(3)Porto Taxi
该数据集包括波尔图市442辆出租车在一年中(从2013年7月1日至2014年6月30日)运行的大约100万条轨迹。每条轨迹包含许多GPS坐标(即GPS坐标)。
(经度和纬度)按年代记录的。每个坐标的采样速度是15秒。我们使用过去7个GPS坐标来预测未来点的位置。
(4)London Weather
数据集包括2017年1月1日至2018年3月27日伦敦861个地区的温度、压力、湿度、风向和风速。所有特征每小时收集一次。我们利用过去的5个观测值来预测未来的值。
Beijing Air 和 PhysioNet 数据集包含缺失数据,用来回答问题1;剩余两个数据集用来研究剩下的问题。
3.2 Baselines
Linear Regression (LR)、XGBoost、MICE、GRUI、GRU-D、BRITS
3.3 实验结果
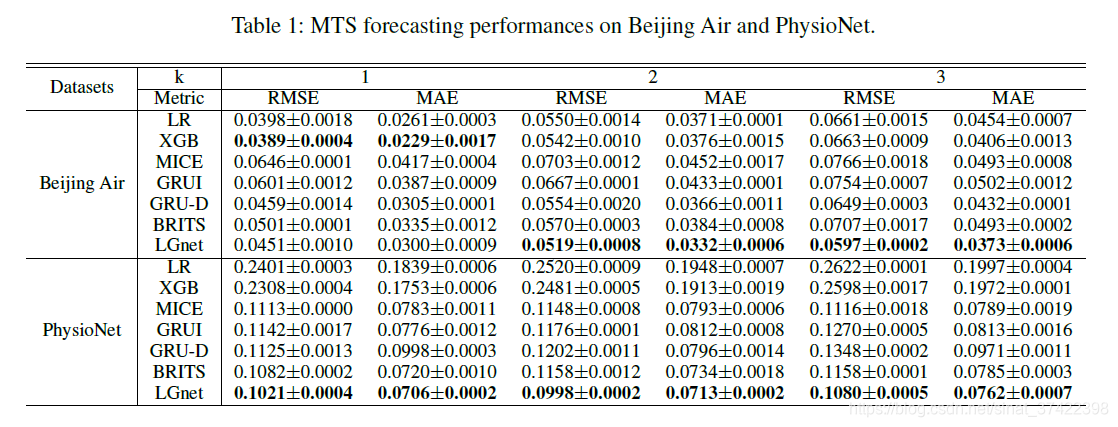
评价指标:
采用均方根误差(RMSE)和平均绝对误差(MAE)。RMSE和MAE越小,性能越好。
结论
(i)在大多数情况下,LGnet优于所有基线方法,这表明记忆模块和对抗式学习在缺失值的多元时间序列预测方面的有效性。内存模块探索全局时间动态并为缺失值生成适当的估计;
(ii)当k增大时,即在预测未来遥远值时,所有方法的性能都有所下降,这是合理的,因为预测未来遥远值比预测近期值更难。
然而,LGnet仍然显著优于比较方法,这是因为我们对预测序列进行了对抗性训练,使预测更符合实际;
(三)此外,LGnet在PhysioNet上的性能提升远比Beijing Air显著。
与北京空气相比,PhysioNet缺失率较高,对基线方法提出了挑战;
而LGnet仍能处理如此高的缺失率,这进一步说明了LGnet通过设计记忆网络和采用对抗性训练的有效性。
参考文献
[1] Che, Z.; Purushotham, S.; Cho, K.; Sontag, D.; and Liu, Y. 2018. Recurrent neural networks for multivariate time series with miss-ing values. Scientific reports 8(1):6085.

















 7216
7216

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









