







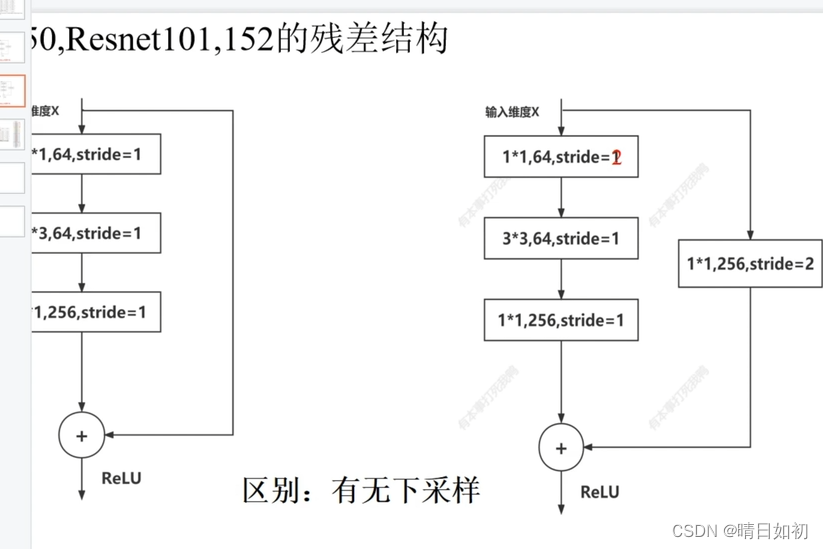
resnet50模型代码
import math
import torch
import torch.nn as nn
from torch.hub import load_state_dict_from_url
# Bottleneck用来定义Conv Block和Identity Block
class Bottleneck(nn.Module):
def __init__(self, in_channels, filters, stride=1):
super(Bottleneck, self).__init__()
self.stride=stride
self.in_channels=in_channels
F1,F2,F3=filters
self.out_channels=F3
self.block=nn.Sequential(nn.Conv2d(in_channels,F1,1,stride=stride,padding=0,bias=False),
nn.BatchNorm2d(F1),
nn.ReLU(inplace=True),
nn.Conv2d(F1, F2, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(F2),
nn.ReLU(inplace=True),
nn.Conv2d(F2, F3, kernel_size=1, padding=0,bias=False),
nn.BatchNorm2d(F3)
)
self.downsample =nn.Sequential(nn.Conv2d(in_channels,out_channels=F3,kernel_size=1,stride=stride,bias=False),
nn.BatchNorm2d(F3))
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
identity = x # 输入
out = self.block(x)
if self.stride != 1 or self.in_channels != self.out_channels: #
identity = self.downsample(x)
# 如果残差边上有卷积就对残差边进行卷积,再和输出进行相加;
# 如果残差边上没有卷积就直接进行输出
out += identity #
out = self.relu(out)
return out
class Resnet50(nn.Module):
def __init__(self,n_class):
# 假设输入进来的图片是600,600,3
super(Resnet50, self).__init__()
self.stage1=nn.Sequential(
nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3,bias=False), # 输入三通道输出64通道,尺寸由600变为300,64*300*300,k7,s=2,p=3
nn.BatchNorm2d(64), # 标准化
nn.ReLU(inplace=True) , # 激活函数
# 300,300,64 -> 150,150,64
nn.MaxPool2d(kernel_size=3, stride=2, padding=1, ceil_mode=True)
) # 最大池化64*150*150,k=3,s=2,p=1 第一步
self.stage2 = nn.Sequential(
Bottleneck(in_channels=64,filters=[64,64,256], stride=1),
Bottleneck(in_channels=256, filters=[64, 64, 256]),
Bottleneck(in_channels=256, filters=[64, 64, 256])
)
self.stage3 = nn.Sequential(
Bottleneck(in_channels=256, filters=[128, 128, 512], stride=2),#下采样
Bottleneck(in_channels=512, filters=[128, 128, 512],stride=1),
Bottleneck(in_channels=512, filters=[128, 128, 512],stride=1),
Bottleneck(in_channels=512, filters=[128, 128, 512],stride=1)
)
self.stage4 = nn.Sequential(
Bottleneck(in_channels=512, filters=[256, 256, 1024], stride=2),#下采样
Bottleneck(in_channels=1024, filters=[256, 256, 1024],stride=1),
Bottleneck(in_channels=1024, filters=[256, 256, 1024],stride=1),
Bottleneck(in_channels=1024, filters=[256, 256, 1024],stride=1),
Bottleneck(in_channels=1024, filters=[256, 256, 1024],stride=1),
Bottleneck(in_channels=1024, filters=[256, 256, 1024],stride=1),
Bottleneck(in_channels=1024, filters=[256, 256, 1024],stride=1))
self.stage5 = nn.Sequential(
Bottleneck(in_channels=1024, filters=[512, 512, 2048], stride=2),#下采样
Bottleneck(in_channels=2048, filters=[512, 512, 2048],stride=1),
Bottleneck(in_channels=2048, filters=[512, 512, 2048],stride=1),
)
self.avgpool = nn.AvgPool2d((1,1))
self.fc = nn.Linear(2048, n_class)
def forward(self, x):
x = self.stage1(x)
x = self.stage2(x)
x = self.stage3(x)
x = self.stage4(x)
x = self.stage5(x)
x = self.avgpool(x)
x = x.view(x.size(0), -1) #展平为1*2048
x = self.fc(x)#全连接
return x
if __name__ == '__main__':
model=Resnet50(2)
x=torch.randn(1,3,224,224)
y=model(x)















 719
719











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









