







这一篇其实并不是提出什么新的东西,而且是做了点类似综述的技术调用实验。省流:T-normalization最好用
摘要
现状:Existing solutions usually involve class-balancing strategies, e.g. by loss re-weighting, data re-sampling, or transfer learning from head- to tail-classes, but most of them adhere to the scheme of jointly learning representations and classifiers.
做法:we decouple the learning procedure into representation learning and classification, and systematically explore how different balancing strategies affect them for long-tailed recognition.
结论:The findings are surprising: (1)data imbalance might not be an issue in learning high-quality representations; (2)with representations learned with the simplest instance-balanced sampling, it is also possible to achieve strong long-tailed recognition ability by adjusting only the classifier.
Classification For LONG-TAILED RECOGNITION
cRT(Classifier Re-training)
re-train the classifier with class-balanced sampling. That is, keeping the representations fixed, we ramdomly re-initialize and optimize the classifier weights W and b for a small number of epochs using class-balanced sampling.
NCM (Nearest Class Mean classifier)
- compute the mean feature representation for each class on the training set
- perform nearest neightbor search either using cosine similarity or the Euclidean distance computed on L2-normalized mean features.
- the cosine similarity alleviates the weight imbalance problem via its inherent normalization.
t-normalized(t-normalized classifier)
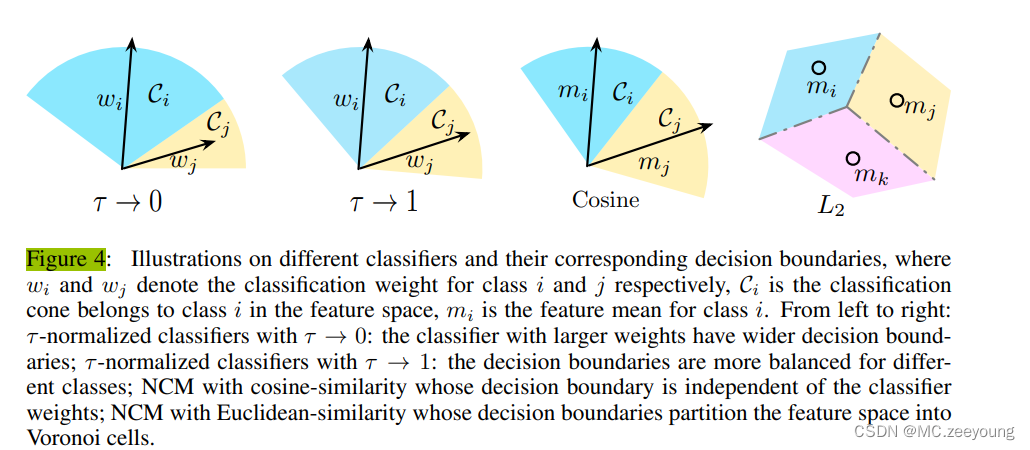
inspired: after joint training with instance-balanced sampling, the norms of the weights || wj || are correlated with the cardinality of the classes nj, while, after fine-tuning the classifiers using class-balanced sampling, the norms of the classifier weights tend to be more similar.
做法:adjusting the classifier weight norms directly through the following t-normalization procedure.
LWS(Learnable weight scaling)
Another way of interpreting t-normalization would be to think of it as a re-scaling of the magnitude for each classifier wi keeping the direction unchanged.(将T-norm 转化为一种对每个分类器权重大小的重新缩放)
Sampling Strategies
Instance-balanced sampling:the most common way of sampling data, where each training example has equal probability of being selected.
Class-balanced sampling:each class has an equal probability of being selected. One can see this as a two-stage sampling strategy, where first a class is selected uniformly from the set of classes, and then an instance from that class is subsequently uniformly sampled.
Square-root sampling
A number of variants of the previous sampling strategies have been explored.
Progressive-balanced sampling
This involves first using instance-balanced sampling for a number of epochs, and then class-balanced sampling for the last epochs.
Experiments
As illustrated in Fig.4, this yields a wider classfication boundary in feature space, allowing the classifier to have much higher accuracy on data-rich classes, but hurting data-scarce classes. t-normalized classifiers alleviate this issue to some extent by providing more balanced classifier weight magnitudes.
官方提供的代码链接: https://github.com/facebookresearch/classifier-balancing.


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









