







这篇文章是属于今年TOD领域的文章,比较惊喜的是它提出了基于Gaussian prior分布差异的度量距离,虽然玩的都是KD。不过还是值得将这份代码看看你是否能拓展在其他领域中。比如我现在就拿这个来尝试跑通缺陷检测
环境配置
这份代码是基于mmdetection框架进行魔改。所以配置方式和mmdetection是一样的。我的是3060卡。现在配置mmdetection可按照下面的步骤走,以及我会记录之前遇到的问题。
- 创建conda虚拟环境
conda create -n mmd python=3.8
- 开启虚拟环境
conda activate mmd
- 安装torch torchvision
pip install torch==1.8.0+cu111 torchvision==0.9.0+cu111 torchaudio===0.8.0 -f https://download.pytorch.org/whl/torch_stable.html
- 验证当前torch是否匹配你的cuda
import torch
torch.cuda.is_available() # 如果返回True,说明ok
torch.zeros(1).cuda()
- 安装mmcv
注意,这里是要小心,mmcv-full的版本要根据工程规定的版本安装。不然就会不匹配。就拿rfa这份代码。我也是后来才知道它做了版本限制。它是在mmdet-rfla/build/lib/mmdet/_init_.py中写了这一段
mmcv_minimum_version = '1.3.2'
mmcv_maximum_version = '1.4.0'
mmcv_version = digit_version(mmcv.__version__)
assert (mmcv_version >= digit_version(mmcv_minimum_version)
and mmcv_version <= digit_version(mmcv_maximum_version)), \
f'MMCV=={mmcv.__version__} is used but incompatible. ' \
f'Please install mmcv>={mmcv_minimum_version}, <={mmcv_maximum_version}.'
根据这个表格
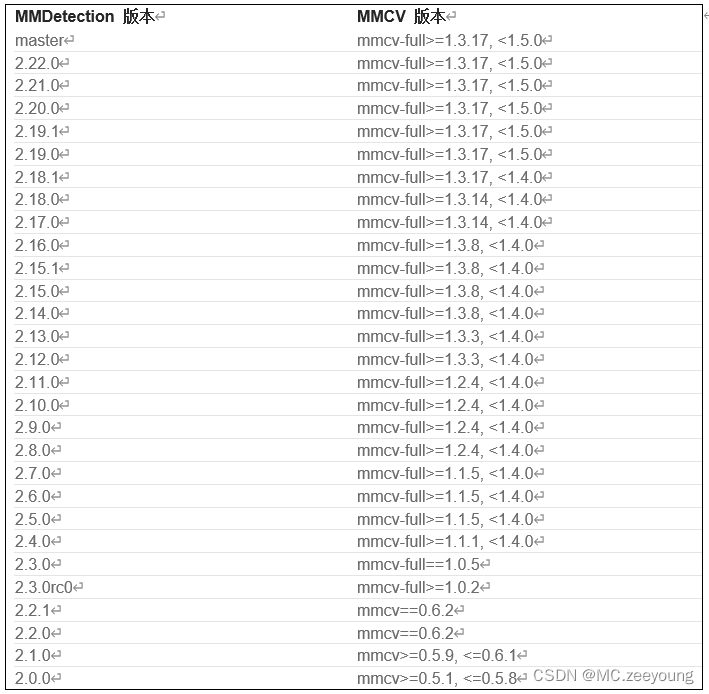
最后安装了mmcv==1.3.9
注意cu111和torch1.8.0这里要和前面torch所安装的版本要对应
pip install mmcv-full==1.3.9 -f https://download.openmmlab.com/mmcv/dist/cu111/torch1.8.0/index.html
- 安装mmcv
git clone https://github.com/open-mmlab/mmdetection.git
cd mmdetection
pip install -r requirements/build.txt
pip install -v -e .
- 安装cocoapi
这是这份代码专属的cocoapi
# Install cocoapi
pip install "git+https://github.com/jwwangchn/cocoapi-aitod.git#subdirectory=aitodpycocotools"
- 验证一下
这里我还在摸索为啥jupyter notebook导入不了mmcv,但是我在命令行是可以的
Q&A
- no kernel image is available for execution on the device问题–(基本可判断为版本不匹配)
然后这里的问题,并非网上说的算力不匹配,而是你mmcv的版本搞错了。一定要对照表格以及torch的安装版本
导入数据
你需要与configs同级目录下创建一个data文件夹,然后如果你是coco数据集,那就这么放
安排数据集文件夹
# ├── configs
# └── data
# └── annotations
# └── train.json
# └── val.json
# └── JPEGImages
# └── xxx.jpg
调试数据集路径
这里的规律我是通过看configs/rfla/下的py,它在开头写
_base_ = [
'../_base_/datasets/aitodv2_detection.py',
'../_base_/schedules/schedule_1x.py', '../_base_/default_runtime.py'
]
我就知道应该是这个model文件要关联dataset的调用,optimizer的配置以及log文件的配置。
复制一份coco_detection.py作为当前任务的数据集配置脚本,命名为defect_detection.py
记住要改成这八个位置 强烈建议刚刚接触mmdetection的小伙伴,第一个位置就写CocoDataset,因为它这里是使用了
dataset_type = 'CocoDataset' # 1
data_root = r'../data/' # 2
data = dict(
samples_per_gpu=8,
workers_per_gpu=1,
train=dict(
type=dataset_type,
ann_file=data_root + 'annotations/train.json',# 3
img_prefix=data_root + 'JPEGImages/',# 4
pipeline=train_pipeline),
val=dict(
type=dataset_type,
ann_file=data_root + 'annotations/val.json', # 5
img_prefix=data_root + 'JPEGImages/', # 6
pipeline=test_pipeline),
test=dict(
type=dataset_type,
ann_file=data_root + 'annotations/val.json', # 7
img_prefix=data_root + 'test/', # 8
pipeline=test_pipeline))
切记,这份py不能出现中文和反斜杠,因为mmdetection说白了就是从一份py里面通过命令行调用直接调用另外一份py,所以他对py里面的注释内容都很严格
网络选型
我选择的是cascade rcnn的py,那么我们在./configs/rfla/aitod_cascade_r50_rfla_kld_1x.py中修改参数
一个是_base_ ,另外一个是roi_head里面的num_classes
_base_ = [
'../_base_/datasets/defect_detection.py', # 1这个的py就是上面数据集脚本的名字
'../_base_/schedules/schedule_1x.py', '../_base_/default_runtime.py'
]
# 这里的所有num_classes
roi_head=dict(
type='CascadeRoIHead',
num_stages=3,
stage_loss_weights=[1, 0.5, 0.25],
bbox_roi_extractor=dict(
type='SingleRoIExtractor',
roi_layer=dict(type='RoIAlign', output_size=7, sampling_ratio=0),
out_channels=256,
featmap_strides=[4, 8, 16, 32]),
bbox_head=[
dict(
type='Shared2FCBBoxHead',
in_channels=256,
fc_out_channels=1024,
roi_feat_size=7,
num_classes=3, #2
bbox_coder=dict(
type='DeltaXYWHBBoxCoder',
target_means=[0., 0., 0., 0.],
target_stds=[0.1, 0.1, 0.2, 0.2]),
reg_class_agnostic=True,
loss_cls=dict(
type='CrossEntropyLoss',
use_sigmoid=False,
loss_weight=1.0),
loss_bbox=dict(type='SmoothL1Loss', beta=1.0,
loss_weight=1.0)),
dict(
type='Shared2FCBBoxHead',
in_channels=256,
fc_out_channels=1024,
roi_feat_size=7,
num_classes=3,
bbox_coder=dict(
type='DeltaXYWHBBoxCoder',
target_means=[0., 0., 0., 0.],
target_stds=[0.05, 0.05, 0.1, 0.1]),
reg_class_agnostic=True,
loss_cls=dict(
type='CrossEntropyLoss',
use_sigmoid=False,
loss_weight=1.0),
loss_bbox=dict(type='SmoothL1Loss', beta=1.0,
loss_weight=1.0)),
dict(
type='Shared2FCBBoxHead',
in_channels=256,
fc_out_channels=1024,
roi_feat_size=7,
num_classes=3,
bbox_coder=dict(
type='DeltaXYWHBBoxCoder',
target_means=[0., 0., 0., 0.],
target_stds=[0.033, 0.033, 0.067, 0.067]),
reg_class_agnostic=True,
loss_cls=dict(
type='CrossEntropyLoss',
use_sigmoid=False,
loss_weight=1.0),
loss_bbox=dict(type='SmoothL1Loss', beta=1.0, loss_weight=1.0))
]),
数据集类别配置
在这个./mmdet/datasets/coco.py里面修改
class CocoDataset(CustomDataset):
# CLASSES = ('person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus',
# 'train', 'truck', 'boat', 'traffic light', 'fire hydrant',
# 'stop sign', 'parking meter', 'bench', 'bird', 'cat', 'dog',
# 'horse', 'sheep', 'cow', 'elephant', 'bear', 'zebra', 'giraffe',
# 'backpack', 'umbrella', 'handbag', 'tie', 'suitcase', 'frisbee',
# 'skis', 'snowboard', 'sports ball', 'kite', 'baseball bat',
# 'baseball glove', 'skateboard', 'surfboard', 'tennis racket',
# 'bottle', 'wine glass', 'cup', 'fork', 'knife', 'spoon', 'bowl',
# 'banana', 'apple', 'sandwich', 'orange', 'broccoli', 'carrot',
# 'hot dog', 'pizza', 'donut', 'cake', 'chair', 'couch',
# 'potted plant', 'bed', 'dining table', 'toilet', 'tv', 'laptop',
# 'mouse', 'remote', 'keyboard', 'cell phone', 'microwave',
# 'oven', 'toaster', 'sink', 'refrigerator', 'book', 'clock',
# 'vase', 'scissors', 'teddy bear', 'hair drier', 'toothbrush')
CLASSES =('hp_cm','hp_cd','kp')
训练命令
python tools/train.py --gpus 1 --gpu-ids [0] ../configs/rfla/aitod_cascade_r50_rfla_kld_1x.py
Q&A
- ModuleNotFoundError: No module named ‘aitodpycocotools’
就是你忘记安装它提供的cocoapi,参照上面环境配置安装即可 - UnicodeDecodeError: ‘utf-8’ codec can’t decode byte 0xca in position 32: invalid continuation byte
或者python3 unicodedecodeerror: ‘ascii‘ codec can‘t decode byte 0xe6
是因为你在上述所提及的所有py中加了中文注释
未完待续…如果有遗漏,欢迎评论区留言















 625
625











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









