







综述内容
Abstract
Recently, long-tailed image classification harvests lots of research attention, since the data distribution is long-tailed in many real-world situations. Piles of algorithms are devised to address the data imbalance problem by biasing the training process toward less frequent classes.
【基于当前许多真实世界场景中的数据分布都呈现长尾分布,因此,许多关于长尾分布的图像分类的成果被许多人所关注】
However, they usually evaluate the performance on a balanced testing set or multiple independent testing sets having distinct distributions with the training data.
【然而,他们通常评估一个平衡测试集或多个独立测试集的性能,都需要这些测试集具有与训练数据不同的分布。】
Considering the testing data may have arbitrary distributions, existing evaluation strategies are unable to reflect the actual classification performance objectively.
【当前测试数据可能存在相似的分布,现存评估测量无法客观反映出模型的泛化性能】
Therefore, a corpus of metrics are designed for measuring the accuracy, robustness, and bounds of algorithms for learning with long-tailed distribution.
Introduction
In practice, training or testing data appears to be long-tailed, e.g., there exist few samples for rare diseases in medical diagnosis [19,35,36,39,42,45] or endangered animals in species classification. The conventional training process of CNNs is dominated by frequent classes while rare classes are neglected. A large number of methods focus on rebalancing the training data through biasing the training process towards rare classes. However, they usually assume the testing data is balanced, while the distribution of real testing data is unknown and arbitrary.
【实际上,长尾分布会存在于一些医学疾病领域中。传统的CNN训练过程中,稀缺类别很容易被忽视。因此当前大量的方法都主要集中于重新平衡训练数据来让CNN在训练过程中偏向稀缺类。然而,这样的做法是假设测试集数据是平衡的,但是往往测试集的分布是未知的】
[35] Dingwen Zhang, Guohai Huang, Qiang Zhang, Jungong Han, Junwei Han, Yizhou Wang, and Yizhou Yu. Exploring task structure for brain tumor segmentation from multi-modality mr images. IEEE Transactions on Image Processing, 29:9032–9043, 2020. 1
[36] Dingwen Zhang, Guohai Huang, Qiang Zhang, Jungong Han, Junwei Han, and Yizhou Yu. Cross-modality deep feature learning for brain tumor segmentation. Pattern Recognition,110:107562, 2021. 1
[39] Dingwen Zhang, Jiajia Zhang, Qiang Zhang, Jungong Han, Shu Zhang, and Junwei Han. Automatic pancreas segmentation based on lightweight dcnn modules and spatial prior propagation. Pattern Recognition, 114:107762, 2021. 1
[42] Gangming Zhao, Chaowei Fang, Guanbin Li, Licheng Jiao, and Yizhou Yu. Contralaterally enhanced networks for thoracic disease detection. IEEE Transactions on Medical Imaging, 40(9):2428–2438, 2021. 1
According to the focused procedures, they can be categorized into four types, data balancing [4,7], feature balancing [6], loss balancing [16,21,22], and prediction balancing [13,28,41]. Most of them train models with imbalanced subsets of existing datasets, such as CIFAR-10/100, ImageNetLT and iNaturalist. Then, they evaluate the classification performance on a balanced testing set with accuracy values of all classes and partial classes (e.g., many/middle/few-shot classes).
Attempts to estimate LLTD algorithms on testing data with multiple distributions : 1) Testing data has an imbalanced distribution sharing the forward trend as the training data; 2) Testing data has uniform sample sizes across classes, namely the distribution is balanced; 3) Testing data has imbalanced distributions with the backward trend of the training data.
1)测试数据与训练数据具有不均衡的分布,共享正向趋势;2) 测试数据具有跨类的统一样本大小,即分布是均衡的;3) 测试数据的分布与训练数据的向后趋势不平衡。
Survey of Long-tailed Learning
Pipeline:
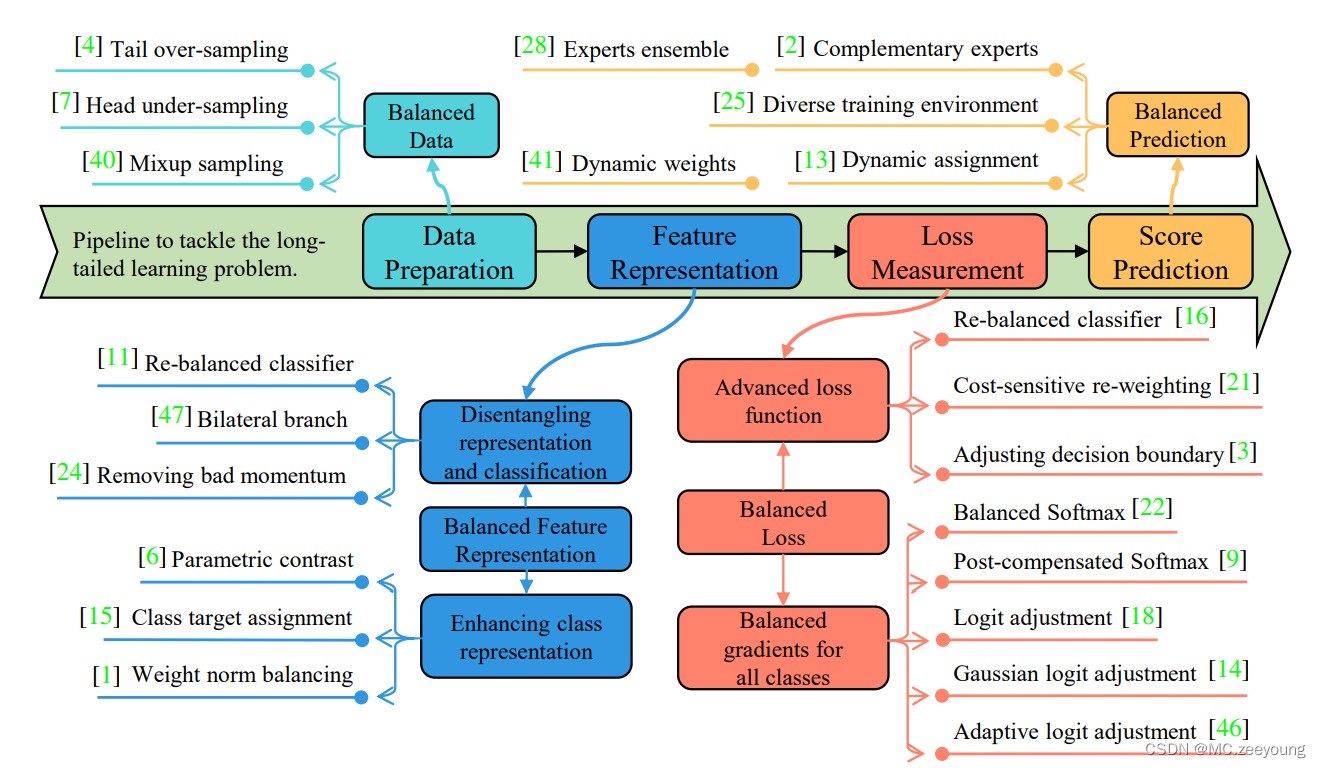
Under long-tailed distribution, head classes are prone to dominate the learning process, thus impairing the accuracy of tail classes. The core factor to address this problem is balancing the learning process.
1. Balanced Data
最直接去解决数据不平衡问题的方法就是去构造一种平衡的数据分布,即重采样训练数据。然而,一些极端地过采样尾部类别的存在会引入过拟合的风险,同时,欠采样多数类又会妨碍到这些多数类的表征学习。因此,有些人则利用一些mixup类型的方法来缓解这些挑战。但是这种的方式很容易出现head-head pair的判读趋势。因此, Xu et al. [29] propose a balance-oriented mixup algorithm by biasing the mixing factor towards tail classes and increasing the occurrence of head-tail pairs.
【29】Zhengzhuo Xu, Zenghao Chai, and Chun Yuan. Towards calibrated model for long-tailed visual recognition from prior perspective. In NeurIPS, pages 7139–7152, 2021. 3, 5, 6, 8
2. Balanced Feature Representation
cRT [11] learns the feature extraction backbone with the conventional training strategy and then employ the data re-balancing algorithms to train the classifier.
BBN [47] unifies the traditional and re-balanced data sampling strategies, and gradually shifts focus from the former to the latter.
Tang et al. [24] use the moving average of momentum to measure the misleading effect of head classes during training, and build a causal inference algorithm to remove the misleading effect during inference.
【cRT先用传统的方法训练backbone,再用数据re-balance算法训练分类器;BBN则是不断地调整数据分布;Tang的方法则是利用可移动平均峰值来衡量当前head class对tail class的不良影响】
Enhance the representation ability for each class, e.g. by contrastive learning.
Cui et al. [6] propose to explicitly learn a feature center for each class, which is used to increase the inter-class separability.
Li et al. [15] reveal that the imbalanced sample distribution leads to close feature centers for tail classes.
Alshammari et al. [1] tackle the long-tailed challenge from the perspective of weight balancing, and apply the weight decay strategy to penalize large weights.
【Cui提出学习每个类的特征中心,来增强类间特征距离;Li揭示了不平衡采样分布可以让tail class的特征中心更加靠近。Alshammari从权重均衡的角度来入手,并应用weight decay 来构造惩罚权重】
【11】Bingyi Kang, Saining Xie, Marcus Rohrbach, Zhicheng Yan, Albert Gordo, Jiashi Feng, and Yannis Kalantidis. Decoupling representation and classifier for long-tailed recognition. In ICLR, 2019. 3, 4, 5, 6, 8
【47】Boyan Zhou, Quan Cui, Xiu-Shen Wei, and Zhao-Min Chen. Bbn: Bilateral-branch network with cumulative learning for long-tailed visual recognition. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9719–9728, 2020. 2, 3, 4, 5, 6,
【24】Kaihua Tang, Jianqiang Huang, and Hanwang Zhang. Longtailed classification by keeping the good and removing the
bad momentum causal effect. Advances in Neural Information Processing Systems, 33:1513–1524, 2020. 3, 4, 5, 6,8
【6】Jiequan Cui, Zhisheng Zhong, Shu Liu, Bei Yu, and Jiaya Jia. Parametric contrastive learning. In ICCV, pages 715–724, 2021. 1, 2, 3, 4, 5, 6, 8
【15】Tianhong Li, Peng Cao, Yuan Yuan, Lijie Fan, Yuzhe Yang, Rogerio S Feris, Piotr Indyk, and Dina Katabi. Targeted supervised contrastive learning for long-tailed recognition. In CVPR, pages 6918–6928, 2022. 3, 4
【1】Shaden Alshammari, Yu-Xiong Wang, Deva Ramanan, and Shu Kong. Long-tailed recognition via weight balancing. In CVPR, pages 6897–6907, 2022. 3, 4
3. Balanced Loss
assigning relatively higher attention to tail classes during the network optimization process.
Focal loss [16] assigns larger weights to samples with lower prediction confidences, i.e., the so-called hard samples.
Park et al. [21] propose to re-weight samples according to the reverse of their influences on decision boundaries.
LDAM [3] tackles the data imbalances challenge by increasing margins of tail classes’ decision boundaries, considering decision boundaries of head classes are more reliable than those of tail classes.
【focal loss是一个常用的均衡类别不平衡的损失函数。Park 则提出一种重权重采样的策略,并应用在决策边界上;LDAM通过增加tail类的决策边界来解决数据不平衡,并将head class的决策边界比tail class更加合理。】
【16】Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, and Piotr Dollar. Focal loss for dense object detection. In ´ Proceedings of the IEEE international conference on computer vision, pages 2980–2988, 2017. 1, 3, 4, 5, 6, 8
【21】Seulki Park, Jongin Lim, Younghan Jeon, and Jin Young Choi. Influence-balanced loss for imbalanced visual classification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 735–744, 2021. 1, 2, 3, 4, 5, 6, 8
【3】Kaidi Cao, Colin Wei, Adrien Gaidon, Nikos Arechiga, and Tengyu Ma. Learning imbalanced datasets with label distribution-aware margin loss. Advances in neural information processing systems, 32, 2019. 1, 3, 4, 5, 6, 8
focus on balancing gradients for head and tail classes by adjusting the Softmax function.
Ren et al. [22] make an early attempt to balance the Softmax function and develop the meta-sampling strategy to dynamically adjust the data distribution in the training process.
LADE [9] proposes the post-compensated Softmax strategy to disentangle the source data distribution from network predictions.
Menon et al. [18] introduce the logit adjustment strategy. If testing samples obey the independent and identical distribution of training samples, the logit adjustment strategy can generate accurate predictions.
GCL [14] introduces Gaussian clouds into the logit adjustment process, and adaptively sets the cloud size according to the sample size of each class.
Zhao et al.[46] reveal that previous logit adjustment techniques primarily focus on the sample quantity of each class, while ignoring the difficulty of samples and propose to prevent the over-optimization on easy samples of tail classes, while highlighting the training on difficult samples of head classes.
【通过改进softmax函数来平衡head class和tail class的gradients.】
【22】Jiawei Ren, Cunjun Yu, Xiao Ma, Haiyu Zhao, Shuai Yi, et al. Balanced meta-softmax for long-tailed visual recognition. Advances in neural information processing systems, 33:4175–4186, 2020. 1, 2, 3, 4, 5, 6, 8
【9】Youngkyu Hong, Seungju Han, Kwanghee Choi, Seokjun Seo, Beomsu Kim, and Buru Chang. Disentangling label distribution for long-tailed visual recognition. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6626–6636, 2021. 1, 2, 3, 4, 5, 6, 8
【18】Aditya Krishna Menon, Sadeep Jayasumana, Ankit Singh Rawat, Himanshu Jain, Andreas Veit, and Sanjiv Kumar. Long-tail learning via logit adjustment. In ICLR, 2021. 3, 4
【14】Mengke Li, Yiu-ming Cheung, and Yang Lu. Long-tailed visual recognition via gaussian clouded logit adjustment. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6929–6938, 2022. 2, 3, 4, 5, 6, 8
【46】Yan Zhao, Weicong Chen, Xu Tan, Kai Huang, and Jihong Zhu. Adaptive logit adjustment loss for long-tailed visual recognition. In AAAI, volume 36, pages 3472–3480, 2022. 3, 4
4. Balanced Prediction
improving the inference process.
Wang et al. [28] learn multiple experts simultaneously and ensemble their predictions to reduce the bias of single models. A dynamic routing module is developed to control the computational costs.
ACE [2] attempts to learn multiple complementary expert models. Specifically, each expert model is responsible for distinguishing a specific set of classes while its responses to non-assigned classes are suppressed.
Zhang et al. [41] learn multiple models under different distributions and combines them with weights generated via testing-time adaptation.
For decreasing the computational cost, Li et al. [13] propose to measure the uncertainty of each expert, and assign experts to each sample dynamically.
Tang et al. [25] utilize uniform intra-class data sampling and confidence aware data sampling strategies to construct different training environments for learning features invariant to diversified attributes.
【Wang 将多个专家模型同时集成推理。 ACE尝试将每个专家模型负责只识别某几种类别。Zhang表示通过权重分配的方式来控制每个专家模型输出的结果。Tang等人[25]利用统一的类内数据采样和置信度感知数据采样策略,为学习特征构建不同的训练环境,使其对多样化属性保持不变。】
【28】Xudong Wang, Long Lian, Zhongqi Miao, Ziwei Liu, and Stella X Yu. Long-tailed recognition by routing diverse distribution-aware experts. In ICLR, 2021. 1, 3, 4, 5, 6, 8
【2】Jiarui Cai, Yizhou Wang, and Jenq-Neng Hwang. Ace: Ally complementary experts for solving long-tailed recognition in one-shot. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 112–121, 2021. 3, 4
【41】Yifan Zhang, Bryan Hooi, Lanqing Hong, and Jiashi Feng. Test-agnostic long-tailed recognition by test-time aggregating diverse experts with self-supervision. In NeurIPS, 2022. 1, 2, 3, 4, 5, 6, 8
【25】Kaihua Tang, Mingyuan Tao, Jiaxin Qi, Zhenguang Liu, and Hanwang Zhang. Invariant feature learning for generalized long-tailed classification. In ECCV, 2022. 3, 4















 840
840











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









