







基于全监督模式的方法
使用 CNN 进行数据训练,提取特征,识别出 Positive && Negative.
问题有2个
- 需要在 Close-Set 下工作:只能识别样本里出现过的。
- 需要在 Strongly-Supervised 下工作:每个视频帧都要标记,人工标记的成本太大。
基于 Open-Set 的异常检测
引入边界学习(Margin Learning, MNL),解决 Close-Set 的局限性。
具体做法
在训练阶段,输入三元组样本(Anchor、Negative、Positive),通过调整三元组损失,让正常样本的分布更紧凑,让异常行为远离正常样本的分布,形成一个正常样本与异常样本之间的边界。
在推理阶段,计算视频样本与的特征位置,如果与正常边界的距离超过阈值,则判定为异常。
基于弱标注设置的方法
使用多实例学习方法,只需要对视频片段标记,而不是对每个视频帧标记,解决 Strongly-Supervised 的局限性。
将视频划分为多个实例,实例可以是片段或者帧。一个视频作为一个袋子。
正常袋子:袋子里的所有实例都是正常的。
异常袋子:袋子里至少有一个异常实例
具体做法
1. 数据准备:
视频划分为 10 秒的片段,每个片段作为一个实例。
如果某段视频包含徘徊行为,该视频袋子被标记为“异常”,否则为“正常”。
2. 特征提取:
使用预训练的 3D 卷积神经网络(如 C3D)提取每个片段的时空特征。
3. 模型训练:
构建一个异常得分预测网络,输入每个实例的特征,输出对应的异常得分。
使用 MIL 排序损失训练模型,确保异常袋子的最高得分高于正常袋子的最高得分。
4. 推理阶段:
对于一个未标注的视频,预测每个片段的异常得分。
识别异常片段的位置,并判定整个视频是否异常。
识别异常片段的位置:计算异常视频里每个实例的异常值,最高的那个实例为异常实例。
基于半监督模式的方法
半监督模式的方法主要利用正常样本进行训练,而无需异常样本的标注。在推理阶段,通过检测输入样本是否偏离正常分布来判断其是否异常。
适用场景:有大量的正常样本,模型可以学习到对正常行为的定义,局限性在于只能判断出是否异常,但无法判断出具体是哪类异常。
1. 基于 CAE/CAN 的方法
训练阶段
使用正常样本训练模型,使模型能够重构或预测正常样本的特性。
建立正常行为或特征的分布模型。
推理阶段
测试样本与正常分布的偏离程度决定其异常性。
偏离越大,越可能是异常样本。
常用结构
卷积自编码器 (Convolutional Autoencoder, CAE)
CAE 是一种基于卷积神经网络(CNN)的自编码器,通常用于学习高维数据的紧凑表示,并尝试从压缩表示中重构原始输入。
CAE 由 Encoder 与 Decoder 构成。Encoder 将原始数据输出成一个用低维表示的特征,Decoder 将低维表示的特征重构(还原)为高维的原始表示。
E E E为重构后的误差,也被用作异常检测的依据。
异常样本由于偏离正常分布,其重构误差通常较高,可据此判定为异常。
但是传统的 CAE 的泛化水平过高,容错能力过强,会对异常样本也生成低误差,导致漏检。
e n c o d e ( r a w d a t a ) = c h a r a c t e r i s t i c encode(raw_data) = characteristic encode(rawdata)=characteristic
d e c o d e ( c h a r a c t e r i s t i c ) = d e c o d e d a t a decode(characteristic) = decode_data decode(characteristic)=decodedata
E = ∣ ∣ r a w d a t a − d e c o d e d a t a ∣ ∣ 2 E = || raw_data - decode_data || ^ 2 E=∣∣rawdata−decodedata∣∣2
生成对抗网络(Generative Adversarial Network, GAN)
GAN 是一种生成模型,由**生成器(Generator)和判别器(Discriminator)**组成,通过二者的对抗学习实现数据生成或分布建模。
生成器(G)
- 接收随机噪声 (少量正常样本) z z z 作为输入,生成伪造数据 G ( z ) G(z) G(z)
- 目标是欺骗判别器,让其认为 G ( z ) G(z) G(z) 是真实数据
判别器(D)
- 判定输入数据是来自真实分布还是生成器生成的数据。
- 输出概率 D ( x ) D(x) D(x),值越接近 1 表示越接近真实数据
当我们训练好足够牛逼的生成器生成器与判别器后,就可以使用生成器来进行数据生成(基于我们提供的少量正常样本)。
传统 GAN 存在的问题
- 训练过程不稳定
- 梯度消失
常用方法
基于评估式的
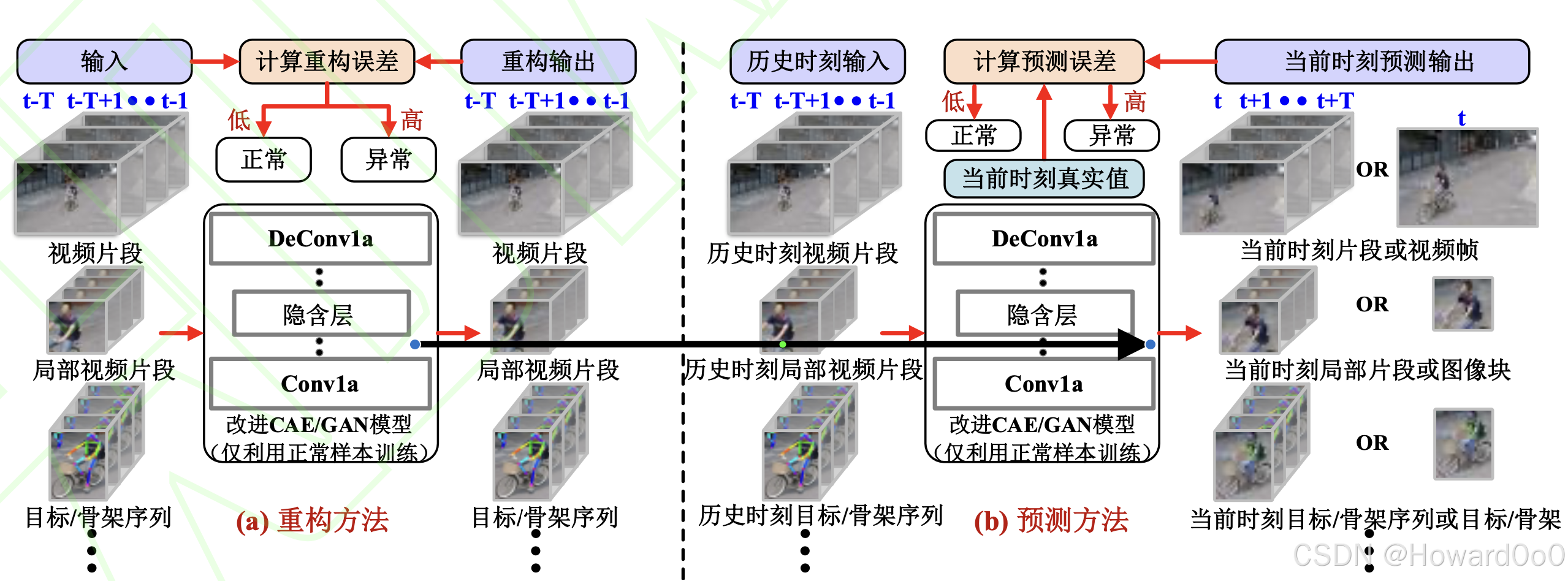
评估重构误差
使用 CAE 对测试样本进行重构,评估重构前后的误差,误差高于阈值的,则判定为异常样本
评估预测误差
利用 GAN 生成下一帧的预测,计算预测帧与当前帧的误差,误差高于阈值的,则判定为异常样本。
评估重构&&预测误差
同时评估重构误差与预测误差。
基于判别式的
基于判别器模型的方法
使用 GAN 的判别器输出测试样本与生成样本之间的相似性。正常样本与对应的生成样本应该高度相似,否则为异常样本。
基于概率模型的方法
使用 CAE 编码器得到训练数据里每个视频片段对应的隐层特征,建立合适的概率模型。
当有一个待测视频片段进入系统时,CAE 编码器将其转换为隐层特征,根据已经建立好的概率模型来计算这个待测隐层特征的概率值。
基于决策模型的方法
CAE 编码器输出的隐层特征 ==> 绘制正常特征分布区域边界(OC-SVM | SVDD)
2. 基于小样本学习的方法
迁移学习 && 元学习
基于无监督学习方法
基于无监督学习的方法适用于有大量(正常&&异常)样本,但是没有标记的情况,不符合我们的场景。
基于伪标注生成
使用 iForest 进行迭代式分类,最终2个分类标签越来越准确。
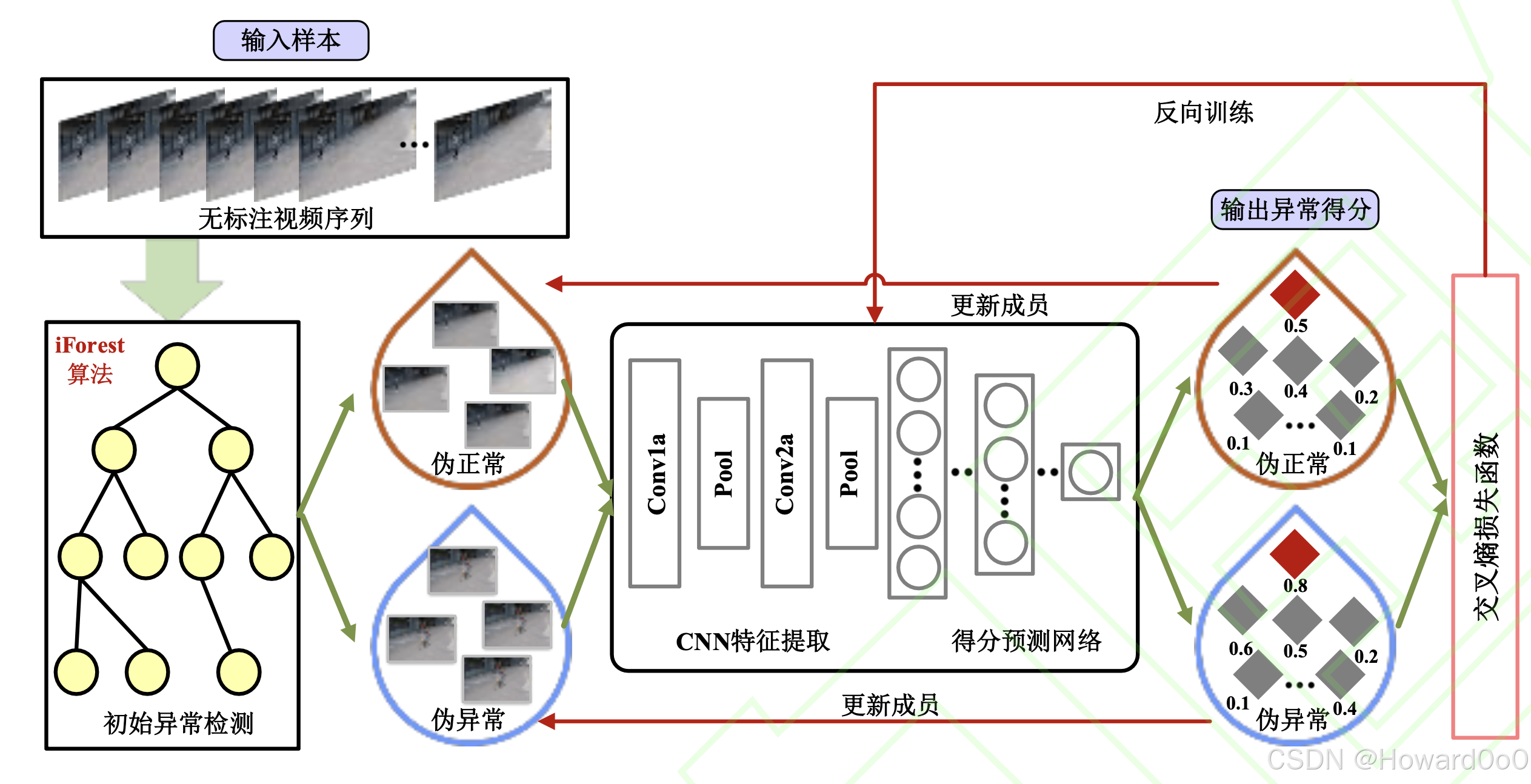
基于伪样本构造
1. 提供正常样本,训练生成器和判别器
生成器基于正常样本,不断生成异常样本,从而训练出一个合格的判别器。再用在这个判别器来识别测试样本。
2. 提供正常样本,构造异常样本(进行混洗、反向、旋转)
将正常样本与构造出来的异常样本进行对比,让模型学习到正常样本的特征。
3. 提供正常样本,从空间维度和时序维度来构造异常样本
也是基于正常样本来构造异常样本,只不过分了空间维度和时序维度,目的也是让模型学习到正常样本的特征。

















 1185
1185

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









