







1、机器学习概念:对于某类任务T和性能度量P,如果一个计算机程序在T上以P衡量的性能随着经验E而自我完善,那么我们称这个计算机程序在从经验E中学习。
eg:西洋跳棋学习问题
任务T:下跳棋
性能标准P:比赛中击败对手的百分比
训练经验E:以往和自己进行对弈
垃圾邮件问题:
任务T:甄别垃圾文件
性能标准P:甄别的正确率
训练经验E:以往的手动分类
2、监督学习
回归问题:连续输出值
分类问题:离散输出值
无穷多特征也可以处理:后期会学到
支持向量机:后续会学到
3、聚类算法是无监督学习算法的一种
4、鸡尾酒会算法(无监督学习算法的一种) :分辩再分离(几种,都有啥)
[W,s,v] =svd((repmat(sum(x.*x,1),size(x,1),1.*x)*x');
svd:奇异值分解(需要线代知识)
5、无监督和监督:链接:https://blog.csdn.net/u012005313/article/details/48023689
6、Octava编程环境,用它建立学习算法原型,再将其起迁移到其他编译环境如c++等。在硅谷好多人都是先用matlab/octava先实现自己的想法,再转化成其他语言。参考链接https://blog.csdn.net/u014096352/article/details/72854077/
7、数据集->学习算法-> (假设)函数
假设函数:
小写m:样本个数
x:输入变量,特征
y:输出值
训练样本(x,y);
(x^(i),y^(i))表示具体的样本
8、线性回归:
代价函数:代价函数有很多种。这里用的是平均误差代价函数。
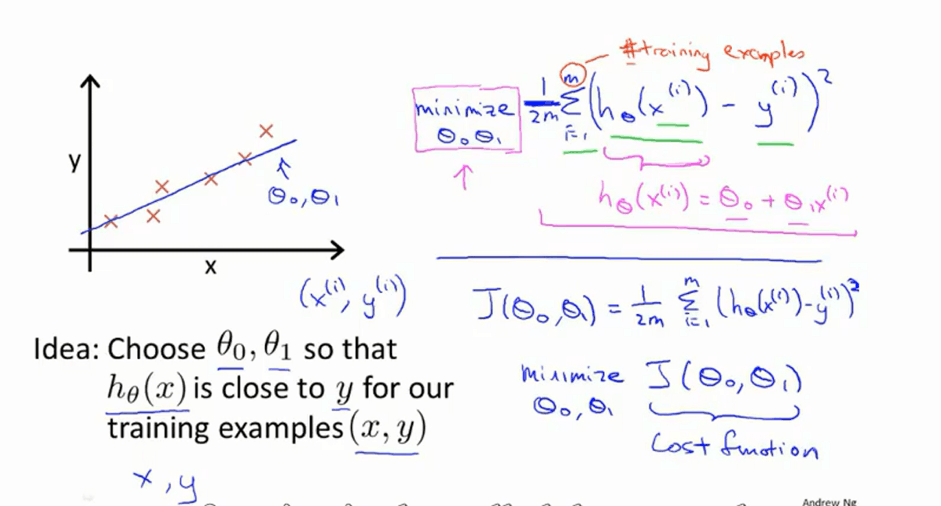
下面是代价函数的下降算法的一次迭代过程:















 246
246











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









