







DIN,Deep Interest Network,深度兴趣网络。论文的关键在于对用户历史行为的embedding向量的改进。模型结构如下:

左边是一般的深度推荐模型,basemodel,basemodel就是将用户特征,进行sum pooling输入给全连接层,和sigmoid函数得到一个输出的结果;
右边则是DIN模型。利用注意力机制对用户的兴趣进行进行一个加权最后再使用一个sum pooling。
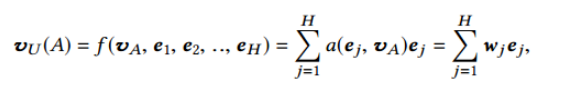
其中,va代表的是候选广告的嵌入向量,ej是用户历史中的兴趣;通过注意力机制来表示用户对于不同历史信息中的关注的重点部分;
改进的关键在于DIN提出了一个局部激活单元,用来产生用户历史行为特征的权重,从而根据候选商品进行自适应调整不同历史行为特征对最终结果的影响程度。传统方法中不管候选商品是什么,经过SUM Pooling后得到的用户历史行为特征都是一样的。但是从现实角度来看,对于不同的候选商品,用户的不同历史行为商品的影响程度是不一样的,而传统深度模型并没有体现出这一点。而DIN中的local activation unit则会根据历史行为商品和候选商品算出一个权重作为该历史行为商品对点击率的影响程度,此时经过 SUM Pooling后得到的用户历史行为特征则会根据不同候选商品发生变化,模型的多样化表征能力也就更强了。我们再来看下上图最右边的local activation unit,模型的输入是历史行为商品embedding向量和候选商品embedding向量,但是传到内部全连接层的输入还加上了两个特征向量的乘积,论文中提到是为了“help relevance modeling”。
采用的特征:包括用户信息,用户行为信息,商品信息等等;其中包含了很多多值离散特征

Dice函数(Data Adaptive Activation Function)是根据Pleakyrelu激活函数演化而来的,它的分割点不是严格的零点,而是根据数据来进行变化的,两者图像如下图所示;



我们这里直接调包来使用这个模型, 关于这个模型的详细细节部分我们会在下一期的推荐系统组队学习中给出。下面说一下该模型如何具体使用:deepctr的函数原型如下:
def DIN(dnn_feature_columns, history_feature_list, dnn_use_bn=False,
dnn_hidden_units=(200, 80), dnn_activation=‘relu’, att_hidden_size=(80, 40), att_activation=“dice”,
att_weight_normalization=False, l2_reg_dnn=0, l2_reg_embedding=1e-6, dnn_dropout=0, seed=1024,
task=‘binary’):
dnn_feature_columns: 特征列, 包含数据所有特征的列表
history_feature_list: 用户历史行为列, 反应用户历史行为的特征的列表
dnn_use_bn: 是否使用BatchNormalization
dnn_hidden_units: 全连接层网络的层数和每一层神经元的个数, 一个列表或者元组
dnn_activation_relu: 全连接网络的激活单元类型
att_hidden_size: 注意力层的全连接网络的层数和每一层神经元的个数
att_activation: 注意力层的激活单元类型
att_weight_normalization: 是否归一化注意力得分
l2_reg_dnn: 全连接网络的正则化系数
l2_reg_embedding: embedding向量的正则化稀疏
dnn_dropout: 全连接网络的神经元的失活概率
task: 任务, 可以是分类, 也可是是回归
在具体使用的时候, 我们必须要传入特征列和历史行为列, 但是再传入之前, 我们需要进行一下特征列的预处理。具体如下:
首先,我们要处理数据集, 得到数据, 由于我们是基于用户过去的行为去预测用户是否点击当前文章, 所以我们需要把数据的特征列划分成数值型特征, 离散型特征和历史行为特征列三部分, 对于每一部分, DIN模型的处理会有不同
对于离散型特征, 在我们的数据集中就是那些类别型的特征, 比如user_id这种, 这种类别型特征, 我们首先要经过embedding处理得到每个特征的低维稠密型表示, 既然要经过embedding, 那么我们就需要为每一列的类别特征的取值建立一个字典,并指明embedding维度, 所以在使用deepctr的DIN模型准备数据的时候, 我们需要通过SparseFeat函数指明这些类别型特征, 这个函数的传入参数就是列名, 列的唯一取值(建立字典用)和embedding维度。
对于用户历史行为特征列, 比如文章id, 文章的类别等这种, 同样的我们需要先经过embedding处理, 只不过和上面不一样的地方是,对于这种特征, 我们在得到每个特征的embedding表示之后, 还需要通过一个Attention_layer计算用户的历史行为和当前候选文章的相关性以此得到当前用户的embedding向量, 这个向量就可以基于当前的候选文章与用户过去点击过得历史文章的相似性的程度来反应用户的兴趣, 并且随着用户的不同的历史点击来变化,去动态的模拟用户兴趣的变化过程。这类特征对于每个用户都是一个历史行为序列, 对于每个用户, 历史行为序列长度会不一样, 可能有的用户点击的历史文章多,有的点击的历史文章少, 所以我们还需要把这个长度统一起来, 在为DIN模型准备数据的时候, 我们首先要通过SparseFeat函数指明这些类别型特征, 然后还需要通过VarLenSparseFeat函数再进行序列填充, 使得每个用户的历史序列一样长, 所以这个函数参数中会有个maxlen,来指明序列的最大长度是多少。
对于连续型特征列, 我们只需要用DenseFeat函数来指明列名和维度即可。
处理完特征列之后, 我们把相应的数据与列进行对应,就得到了最后的数据。
转载:
作者:妖皇裂天
链接:https://www.jianshu.com/p/cddb87f19605
来源:简书
欢迎使用Markdown编辑器
你好! 这是你第一次使用 Markdown编辑器 所展示的欢迎页。如果你想学习如何使用Markdown编辑器, 可以仔细阅读这篇文章,了解一下Markdown的基本语法知识。
新的改变
我们对Markdown编辑器进行了一些功能拓展与语法支持,除了标准的Markdown编辑器功能,我们增加了如下几点新功能,帮助你用它写博客:
- 全新的界面设计 ,将会带来全新的写作体验;
- 在创作中心设置你喜爱的代码高亮样式,Markdown 将代码片显示选择的高亮样式 进行展示;
- 增加了 图片拖拽 功能,你可以将本地的图片直接拖拽到编辑区域直接展示;
- 全新的 KaTeX数学公式 语法;
- 增加了支持甘特图的mermaid语法1 功能;
- 增加了 多屏幕编辑 Markdown文章功能;
- 增加了 焦点写作模式、预览模式、简洁写作模式、左右区域同步滚轮设置 等功能,功能按钮位于编辑区域与预览区域中间;
- 增加了 检查列表 功能。
功能快捷键
撤销:Ctrl/Command + Z
重做:Ctrl/Command + Y
加粗:Ctrl/Command + B
斜体:Ctrl/Command + I
标题:Ctrl/Command + Shift + H
无序列表:Ctrl/Command + Shift + U
有序列表:Ctrl/Command + Shift + O
检查列表:Ctrl/Command + Shift + C
插入代码:Ctrl/Command + Shift + K
插入链接:Ctrl/Command + Shift + L
插入图片:Ctrl/Command + Shift + G
查找:Ctrl/Command + F
替换:Ctrl/Command + G
合理的创建标题,有助于目录的生成
直接输入1次#,并按下space后,将生成1级标题。
输入2次#,并按下space后,将生成2级标题。
以此类推,我们支持6级标题。有助于使用TOC语法后生成一个完美的目录。
如何改变文本的样式
强调文本 强调文本
加粗文本 加粗文本
标记文本
删除文本
引用文本
H2O is是液体。
210 运算结果是 1024.
插入链接与图片
链接: link.
图片:
带尺寸的图片:
居中的图片:
居中并且带尺寸的图片:
当然,我们为了让用户更加便捷,我们增加了图片拖拽功能。
如何插入一段漂亮的代码片
去博客设置页面,选择一款你喜欢的代码片高亮样式,下面展示同样高亮的 代码片.
// An highlighted block
var foo = 'bar';
生成一个适合你的列表
- 项目
- 项目
- 项目
- 项目
- 项目1
- 项目2
- 项目3
- 计划任务
- 完成任务
创建一个表格
一个简单的表格是这么创建的:
| 项目 | Value |
|---|---|
| 电脑 | $1600 |
| 手机 | $12 |
| 导管 | $1 |
设定内容居中、居左、居右
使用:---------:居中
使用:----------居左
使用----------:居右
| 第一列 | 第二列 | 第三列 |
|---|---|---|
| 第一列文本居中 | 第二列文本居右 | 第三列文本居左 |
SmartyPants
SmartyPants将ASCII标点字符转换为“智能”印刷标点HTML实体。例如:
| TYPE | ASCII | HTML |
|---|---|---|
| Single backticks | 'Isn't this fun?' |
‘Isn’t this fun?’ |
| Quotes | "Isn't this fun?" |
“Isn’t this fun?” |
| Dashes | -- is en-dash, --- is em-dash |
– is en-dash, — is em-dash |
创建一个自定义列表
-
Markdown
- Text-to- HTML conversion tool Authors
- John
- Luke
如何创建一个注脚
一个具有注脚的文本。2
注释也是必不可少的
Markdown将文本转换为 HTML。
KaTeX数学公式
您可以使用渲染LaTeX数学表达式 KaTeX:
Gamma公式展示 Γ ( n ) = ( n − 1 ) ! ∀ n ∈ N \Gamma(n) = (n-1)!\quad\forall n\in\mathbb N Γ(n)=(n−1)!∀n∈N 是通过欧拉积分
Γ ( z ) = ∫ 0 ∞ t z − 1 e − t
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 785
785











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









