







Facial Expression Recognition Using Residual Masking Network
论文链接:https://ieeexplore.ieee.org/document/9411919
Abstract
论文创新点:
提出了一种新的掩膜方法来提高CNN在面部表情任务中的性能。它使用分割网络来细化特征图,使网络能够关注相关信息以做出正确的决策。在实验中,我们将普遍存在的深度残差网络和U-net结构相结合,生成一个残差掩膜网络。
Introduction
作者提出了一种新的掩膜思想。该思想使用基于U-net的定位网络来细化输入特征映射,并生成包含对输入特征映射某些区域的关注的输出特征映射。每个掩膜块都是U-net网络的一个小方差,这使得残差掩膜网络能够聚焦关键的空间信息并进行正确的面部表情分类。
论文贡献:
- 提出了一个新的掩膜想法来提高性能;
- 建立人脸表情识别的残差掩膜网络;
- 创建一个名为VEMO的新数据集。
小结:
- 人脸关键区域的检测精度主要有助于分类精度的提高。
- 面部表情是基于一些面部区域的组合来确定的,例如眼睛、鼻子、嘴巴。一些传统的方法是基于面部标志点提取这些面部区域。然而,由于受试者内部的变化,如遮挡、照明和头部姿势的变化,标志点检测主要在实验室控制的数据集上工作良好,但在野生数据集中工作不好。
- 对于基于CNN的FER方法,可以通过CNN的中间层观察面部区域的定位。
- 注意力机制经常应用于基于CNN的方法,以提高网络对相关信息的集中度,并忽略不必要的信息。
本文方法
该网络包含四个主要的残差掩膜块(Resmasking块)。在不同特征尺寸上操作的每个残差掩膜块包含一个残差层和一个掩膜块。
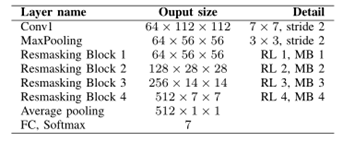
大小为224×224的输入图像将以步长2通过第一个3×3卷积层,然后通过2×2最大池层,将其空间大小减小到56×56。接下来,在前一个池化层之后获得的特征图通过以下四个残差掩膜块进行转换,生成四个空间尺寸的特征图,包括56×56、28×28、14×14和7×7。网络以平均池化层和7路全连接层结束,并使用softmax生成对应于七种面部表情状态(6种情绪和一种中性状态)的输出。
残差掩膜块:
在这项研究中,作者提出了掩膜块,它执行评分操作。然后,直接组合掩模块的输入特征映射及其输出。作者移除主干分支,并重新使用Resnet34作为主干。
作者设计了包含一个残差层和一个掩膜块的残差掩膜块,前者负责特征处理,后者为相应的特征映射生成权重。
图2 残差掩膜网络

给定一个输入特征映射
F
∈
R
C
×
W
×
H
F∈R^{C×W×H}
F∈RC×W×H,首先,
F
F
F将通过残差层
R
R
R(图2a)生成粗特征映射
F
R
=
R
(
F
)
F_R=R(F)
FR=R(F),
F
R
∈
R
C
′
×
W
′
×
H
′
F_R∈R^{C'×W'×H'}
FR∈RC′×W′×H′。然后,通过公式
F
M
=
M
(
F
R
)
F_M=M(F_R)
FM=M(FR)通过掩膜块计算具有范围[0,1]中的值的相同大小的激活映射
F
M
F_M
FM。最后,公式1将产生残差掩膜块的细化特征映射输出。这样,我们假设
F
M
F_M
FM比修改后的特征映射
F
R
F_R
FR更便于明智地对输入特征映射的元素重要性进行评分。

其中
F
R
F_R
FR是通过残差层的
F
F
F的变换特征图,
⨂
⨂
⨂表示按元素的乘法。作者也使用[10]中提出的注意残差学习方法来防止掩膜块移除有用的特征。
掩膜块基于[11]中提出的U-net结构,这是一种用于定位小型医疗对象的著名结构。该块由一条收缩路径(编码器)和一条扩展路径(解码器)组成,如图2b所示。与其他[8]、[10]相比,使用掩膜块是我们注意力模块的主要区别。此外,值得注意的是,根据残差输入单元的空间特征尺寸,掩膜块具有不同数量的池化和上采样层。掩膜块可以在许多分段体系结构中扮演激活的角色,而不是像作者的方法中那样仅在类似于U-net的体系结构中。
集成方法:
竞争环境中,很难避免集成方法对精度的影响。为了证明残差掩膜网络与其他CNN相结合的能力,作者使用一个简单的非加权和平均集合来融合7个不同CNN的预测结果。模型搜索基于[34]中的验证准确性条款。
结论
本文提出了一种人脸表情识别系统,其主要贡献是在残差掩膜网络中实现了一种新的掩膜思想。该残差掩膜网络包含多个掩膜块,这些掩膜块跨残差层应用,以提高网络对重要信息的注意能力。实验结果表明,所提出的方法比著名的分类系统以及FER2013数据集上最新的报告结果具有更高的精度。该方法未来改进的重点是通过在最大的分类数据集ImageNet数据集上评估模型泛化来检验模型泛化。此外,还将探讨不同的网络参数以及模型参数的简化,以提高分类和检测等视觉任务的网络性能。作者的目标是构建一个完整的系统,并在开放的排练环境中进行测试。















 1349
1349











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









