







Python多进程加快图片读取速度(mp.Queue)
多进程,加快图片读取,多进程下图片的有序读取,Python,multiprocessing,multiprocessing.Queue,opencv-python

-
文章结构
- 快速使用,多进程读取图片(简化版)
- 影响读取速度的瓶颈(CPU 与磁盘)
- 多进程读取图片(完整版):有序读取、图片检查
1.快速使用,多进程读取图片(简化版)
黑色加粗的地方,是文件夹路径,请自行修改,图片为 jpg 格式,可以直接复制运行一下,体验一下磁盘占用率 100% 的感觉。
这里用到了 python3 自带的 multiprocessing.Queue 完成多进程的实现,如果你想先对 multiprocessing 有一定的了解,可以先看我的另一篇文章(还没写,有人催我就写)——multiprocessing 简单使用
import os
import multiprocessing as mp
import cv2
import numpy as np
'''
2018-07-05 Yonv1943 show file images, via multiprocessing
2018-09-04 use multiprocessing for loading images
2018-09-05 add simplify
'''
def img_load(queue, queue_idx__img_paths):
while True:
idx, img_path = queue_idx__img_paths.get()
img = cv2.imread(img_path) # Disk IO
queue.put((img, idx, img_path))
def img_show(queue, window_name=''): # img_show_simplify
cv2.namedWindow(window_name, cv2.WINDOW_KEEPRATIO)
while True:
img, idx, img_path = queue.get()
cv2.imshow(window_name, img)
cv2.waitKey(1)
def run():
src_path = 'F:/url_get_image/ftp.nnvl.noaa.gov_GER_2018'
img_paths = [os.path.join(src_path, f) for f in os.listdir(src_path)]
mp.set_start_method('spawn')
queue_img = mp.Queue(8)
queue_idx__img_path = mp.Queue(len(img_paths))
[queue_idx__img_path.put(idx__img_path) for idx__img_path in enumerate(img_paths)]
processes = list()
processes.append(mp.Process(target=img_show, args=(queue_img,)), )
processes.extend([mp.Process(target=img_load, args=(queue_img, queue_idx__img_path))
for _ in range(3)])
[setattr(process, "daemon", True) for process in processes]
[process.start() for process in processes]
[process.join() for process in processes]
if __name__ == '__main__':
run()
2.影响读取速度的瓶颈(CPU 与磁盘)
开启多个进程从磁盘读取文件,并由 CPU 解析图片格式,将图片转化为 numpy 的 ndarray 保存在内存里面

当备用内存中找不到我们要读取的图片时,进程开始从磁盘中读取,这个时候磁盘成为限制读取的瓶颈。
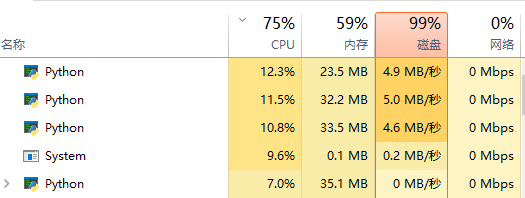
如果操作系统有类似于 Win10 的 Superfetch 服务,那么读取初期,要读取的文件其实已经在内存里面了,此时的系统瓶颈在 CPU 处,CPU 需要把对应的图片格式转化为 ndarray
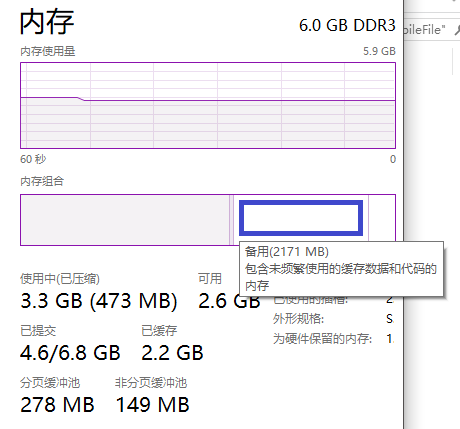
看下面图中的 CPU 占用 与 磁盘占用,可以看到前期是 CPU 满载,后期是磁盘满载,
因为我没有把读取到内存的 ndarray 继续保存在内存里,所以内存占用没有上升。
3.多进程读取图片(完整版)
我放了一份完整版代码在 GitHub 上: DEMO_images_load_order_mp_cv2.py(GitHub 上的代码会时常修改,有时候因为文件改名,会导致链接会指向错误,到时候请联系我修改,当然你也可以直接看下面的代码)
完整版添加了:
- 多进程下的有序读取:维护一个有序数组,按顺序读取图片
- 图片类型检查:图片是否可以正确读取,检查图片是否完整
- 图片后缀名检查:只读取匹配的文件类型,如 jpg
import os
import multiprocessing as mp
import cv2
import numpy as np
'''
2018-07-05 Yonv1943 show file images, via multiprocessing
2018-09-04 use multiprocessing for loading images
2018-09-05 add simplify
'''
def img_load(queue, queue_idx__img_paths):
while True:
idx, img_path = queue_idx__img_paths.get()
img = cv2.imread(img_path) # Disk IO
queue.put((img, idx, img_path))
def img_show(queue, window_name=''): # check images and keep order
cv2.namedWindow(window_name, cv2.WINDOW_KEEPRATIO)
import bisect
idx_previous = -1
idxs = list()
queue_gets = list()
while True:
queue_get = queue.get()
idx = queue_get[1]
insert = bisect.bisect(idxs, idx) # keep order
idxs.insert(insert, idx)
queue_gets.insert(insert, queue_get)
# print(idx_previous, idxs)
while idxs and idxs[0] == idx_previous + 1:
idx_previous = idxs.pop(0)
img, idx, img_path = queue_gets.pop(0)
if not isinstance(img, np.ndarray): # check images
os.remove(img_path)
print("| Remove no image:", idx, img_path)
elif not (img[-4:, -4:] - 128).any(): # download incomplete
os.remove(img_path)
print("| Remove incomplete image:", idx, img_path)
else:
try:
cv2.imshow(window_name, img)
cv2.waitKey(1)
except error as e:
print("|Error:", e, idx, img_path)
def run():
src_path = 'F:/url_get_image/ftp.nnvl.noaa.gov_GER_2018'
img_paths = [os.path.join(src_path, f) for f in os.listdir(src_path) if f[-4:] == '.jpg']
print("|Directory perpare to load:", src_path)
print("|Number of images:", len(img_paths), img_paths[0])
mp.set_start_method('spawn')
queue_img = mp.Queue(8)
queue_idx__img_path = mp.Queue(len(img_paths))
[queue_idx__img_path.put(idx__img_path) for idx__img_path in enumerate(img_paths)]
processes = list()
processes.append(mp.Process(target=img_show, args=(queue_img,)), )
processes.extend([mp.Process(target=img_load, args=(queue_img, queue_idx__img_path))
for _ in range(3)])
[setattr(process, "daemon", True) for process in processes]
[process.start() for process in processes]
[process.join() for process in processes]
if __name__ == '__main__':
run()
4.多进程下的有序读取:(重点)
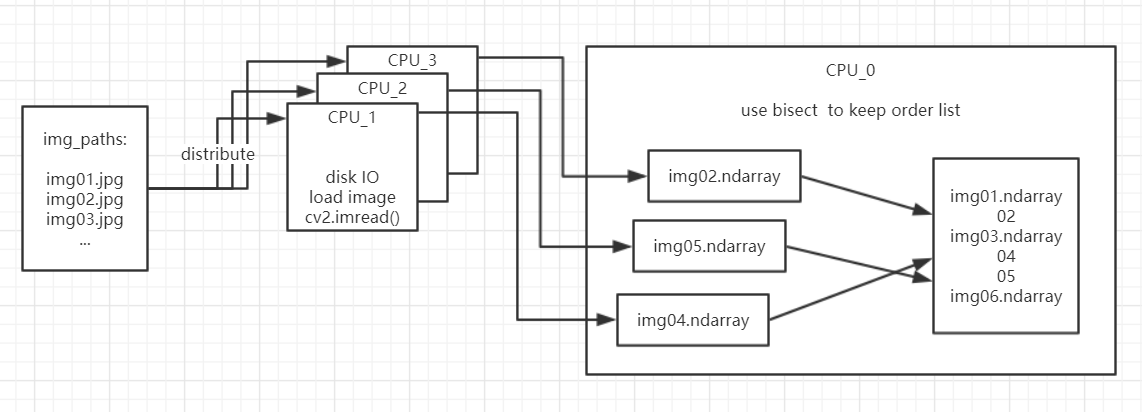
因为将读取的任务列表分发给各个 CPU 的时候,因为 CPU 读取耗费的时间不同,而导致图片顺序被小幅度打乱,所以需要将图片排序。
用于输出图片的 CPU_0 负责排序,如果上一张输出图片 01,那么下一张输出的图片是 02,如果接收到其他 CPU 传来的图片 04、图片 05,那么就先不输出,暂时存入有序列表;
接收到图片 02 后,才输出图片,等到缺少下一张图片的时候,再从 CPU 处接收新的图片。
4.1 图片类型检查:
读取大量图片的时候,需要进行类型检查,以避免程序因错误而中断,这里进行了两个检查
- 检查图片是否正确读取(使用 Python 的内建函数 ininstance(object, object))
- 检查图片是否下载完整(未完整下载的图片,图片下方 RGB 值为固定值)
- 捕获未知的错误
其实对于无法打开的图片,比较好的处理方式并不是删除,而是移动,把出错的图片移动到其他文件夹。使用 shutil.rmtree() 替代 os.remove()
if not isinstance(img, np.ndarray): # check images
os.remove(img_path)
print("| Remove no image:", idx, img_path)
elif not (img[-4:, -4:] - 128).any(): # download incomplete
os.remove(img_path)
print("| Remove incomplete image:", idx, img_path)
else:
try:
cv2.imshow(window_name, img)
cv2.waitKey(1)
except error as e:
print("|Error:", e, idx, img_path)
4.2 图片后缀名检查:
检查后缀名可以避开文件夹里面的其他文件,读取的图片格式应该随实际情况修改, 我读取的是’jpg’,以免被过滤掉,opencv-python 的 cv2.imread() 支持 jpg,jpeg,png,bmp 等格式的读取
src_path = 'F:\\url_get_image\\ftp.nnvl.noaa.gov_GER_2018' # better in winOS
img_paths = [os.path.join(src_path, f) for f in os.listdir(src_path) if f[-4:] == '.jpg']
我读取的图片是从美国国家海洋和大气管理局下载的,在我的另外一篇文章( 使用卷积网络移除卫星图片中的云层 )中,我也需要使用多进程加快磁盘图片文件的读取,因为我顺便把多进程读取图片的代码发到网络上,方便大家交流。
参考资料:
17.2. multiprocessing - Process-based parallelism - Python 3.7.0 documentation

















 7367
7367











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











