







BN
归一化方法总结、BatchNormalization、可视化BN-工作方式以及为什么神经网络需要它、

论文-Rethinking"Batch” in BatchNorm-阅读中
翻译1√、翻译2√、
CVPR2021|重新思考BatchNorm中的Batch
单位:FAIR(Yuxin Wu, Justin Johnson两位巨佬)
论文:https://arxiv.org/abs/2105.07576
新方法
开源|性能炸裂,旷视提出适用于底层问题的Half Instance Normalization
01-Motivation
BatchNorm现在已经广泛的应用于CNN中。但是BN针对不同的场景使用时有许多细微的差异,如果选择不当会降低模型的性能。BatchNorm相对于其他算子来说,主要的不同在于BN是对batch数据进行操作的。BN在batch数据中进行统计量计算,而其他算子一般都是独立处理单个样本的。因此影响BN的输出不仅仅取决于单个样本的性质,还取决于batch的采样方式/分组方式(下图)。 ==>合理使用batch采样方式来提高性能。

02-A review of BatchNorm
相关:BN中为什么需要scale和shift 因为convariance问题在每一个层layer上都存在,都需要batch norm来解决问题 | convariance shift问题:在输入层上,如果一部分样本的分布与另一部分样本显著分布不同:[0,1] vs [10,100]。输入层的这种情况,对于其他层而言,也是一样,无法逃避。| 原论文中:
- Covariance shift:由于parameters发生变化,导致本层的activation发生变化 当每层activation的分布都不相同或者差异较大时,训练效率会很低下;
- 因此既然是分布不同导致的问题,解决方案就是统一每一层的activations的分布,BN统一所有层的neurons值的分布,就有了normalization: mean = 0, variance = 1;
γ,β的作用:在上述框架(正态分布0,1)不变下,稍微增加一点灵活性(可能够灵活放缩和平移分布),可能会让模型训练的效率更高。原论文中:
- 因为normalization会导致新的分布丧失从前层传递过来的特征与知识
- 以sigmoid作为激活函数的层为例,normalize后的分布会导致无法有效利用sigmoid的非线性功能
- 加入了γ,β的放缩和平移的能力,是为了让新生成的分布,能够利用好接下来的激活函数的非线性功能
- 在特定区域的大体框架下,如果可以在垂直方向上有一定程度的放大缩小的自由度(scale),在水平方向上有一定的移动的自由度(shift)
- γ,β和其他的parameters 一样,在训练中通过反向传递来更新自己
视频-initialization、batch normalization、covariance shift、同前-中文、=>笔记、
论文:在一个mini-batches中,在每一BN层中,对每个通道计算它们的均值和方差,再对数据进行归一化,归一化的值具有零均值和单位方差的特点,最后使用两个可学习参数gamma和beta对归一化的数据进行缩放和移位。
此外,在训练过程中还保存了每个mini-batches每一BN层每一通道的均值和方差,最后求所有mini-batches均值和方差的期望值,以此来作为推理过程中该BN层各自通道的均值和方差。
以CNN中的BN为例

batch采样方式主要影响的是统计量mean和std,本文将mean和std看成是一个逐通道分开计算的仿射变换(可以等价为一个1x1的depth-wise layer)。
03- Whole Population as a Batch
相关:EMA-指数平均数指标-MA反映的是均价数值变换 EMA反映的是均价趋势变化、EMA更关注现在的市场价格变化,这也是在交易中追求的。但相对来说EMA还是一个滞后指标,在判断趋势中有一定作用,但对于交易信号上比较迟缓。| EMA(t)=平滑常数*当前价格+(1-平滑常数)*EMA(t-1)
论文:BN中统计量的计算默认使用EMA方法,但是作者实验发现EMA会导致模型性能次优,然后提出了PreciseBN方法,近似将整个训练集统计量作为一个batch。
实验-4个结论:①推理时使用PreciseBN会更加稳定②当batchsize很大时,对EMA影响很大,EMA算法不稳定③PreciseBN只需要10^3~10^4个样本可以得到近似最优④小batch会累计误差
04- Batch in Training and Testing
BN在训练和测试中行为不一致:训练时,BN的统计量来自mini-batch;测试时,BN的统计量来自population。这部分主要探讨了BN行为不一致对模型性能的影响,并且提出消除不一致的方法提升模型性能。
(1)BatchSize的影响:normalization batch size对training noise和train-test inconsistency有着直接影响:使用更大的batch,mini-batch统计量越接近population统计量,从而降低training noise和train-test inconsistency。
(2)使用Mini-batch
(3)训练时使用Population Batch
05-Batch from Different Domains
BN的训练过程可以看成是两个独立的阶段:第一个阶段是通过SGD学习features,第二个阶段是由这些features得到population统计量。两个阶段分别称为SGD training和population statistics training。
由于BN多了一个population统计阶段,导致训练和测试之间的domain shift。当数据来自多个doman时,SGD training、population statistics training和testing三个步骤的domain gap都会对泛化性造成影响。
06-Information Leakage within a Batch
07-总结
【记录】
1、BN与batchsize关系


不过当batch size=1,BatchNorm就不能准确估计数据集的均值和方差。可以考虑使用GroupNorm,性能可能会有提升。


不过说到底,还是多做几次实验看看效果吧
2、batchsize设定



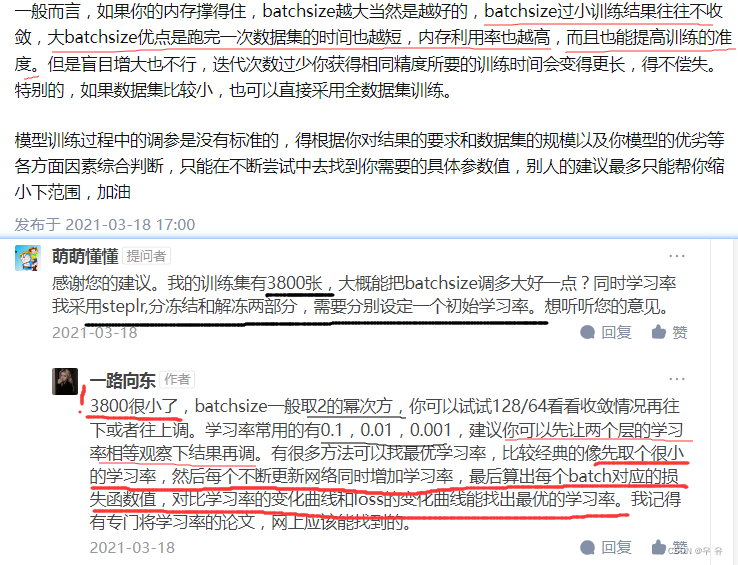



其他相关参数:















 5188
5188











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









