







这是我的第304篇原创文章。
一、引言
方差分析(Analysis of Variance,简称ANOVA)是一种统计方法,用于比较两个或多个组之间的平均值是否存在显著差异。
方法简介:
ANOVA 通过分解总方差为组间方差和组内方差,计算统计量 F 值来检验不同组之间的平均值是否存在显著差异(例如不同学习方法,考试成绩的差异,学习方法的类型是标签,考试成绩是特征)。在特征选择中,可以将特征对目标变量的影响视为不同组的平均值,从而利用 ANOVA 分析各个特征对模型性能的贡献程度。
二、实现过程
2.1 准备数据
data = pd.read_csv(r'dataset.csv')
df = pd.DataFrame(data)
2.2 目标变量和特征变量
target = 'target'
features = df.columns.drop(target)特征变量如下:

2.3 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(df[features].values, df[target].values, test_size=0.2, random_state=0)2.4 计算f统计量
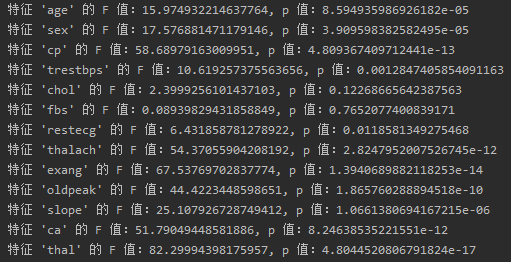
进行 ANOVA 分析,通过计算每个特征与目标变量之间的f统计量,来判断哪些特征与目标变量最相关。
f_scores, p_values = f_classif(X_train, y_train)
# 打印每个特征的 F 值和 p 值
for i, feature_name in enumerate(features):
print(f"特征 '{feature_name}' 的 F 值:{f_scores[i]}, p 值:{p_values[i]}")打印结果:
2.5 可视化卡方统计量
代码:
sns.set(font_scale=1.2)
plt.rc('font',family=['Times New Roman', 'SimSun'], size=12)
plt.figure(figsize=(10, 6))
plt.bar(features, chi_scores, color='skyblue')
plt.xticks(rotation=45)
plt.xlabel('特征')
plt.ylabel('卡方统计量')
plt.title('各特征的卡方统计量')
plt.show()结果:

在进行 ANOVA 分析后,我们可以根据 F 值和 p 值来解读结果:
F 值: 表示不同组之间的方差差异程度。F 值越大,表示不同组之间的平均值差异越显著。
p 值: 表示观察到的结果是否由随机因素引起的概率。通常,如果 p 值小于显著性水平(如0.05),则拒绝零假设,认为差异显著。
通过分析 ANOVA 结果,我们可以确定哪些特征对模型性能的影响最为显著,从而指导特征选择和模型优化的策略。
作者简介:
读研期间发表6篇SCI数据挖掘相关论文,现在某研究院从事数据算法相关科研工作,结合自身科研实践经历不定期分享关于Python、机器学习、深度学习、人工智能系列基础知识与应用案例。致力于只做原创,以最简单的方式理解和学习,关注我一起交流成长。需要数据集和源码的小伙伴可以关注底部公众号添加作者微信。


















 3720
3720

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











